PyTorch项目源码学习(3)——Module类初步学习
torch.nn.Module
Module类是用户使用torch来自定义网络模型的基础,Module的设计要求包括低耦合性,高模块化等等。一般来说,计算图上所有的子图都可以是Module的子类,包括卷积,激活函数,损失函数节点以及相邻节点组成的集合等等,注意这里的关键词是“节点”,Module族类在计算图中主要起到搭建结构的作用,而不涉及运算逻辑的具体实现。
要注意的是,Module类对象的children所指向的其他Module类对象,并不等同于计算图中的子节点。如果我们展开Module网络,得到的一般是树形结构而非DAG,Module网络需要经过其他工作才能转化为计算图。
源代码分析
成员分析
首先直接从前端入手,找到torch/nn/module目录,可以看到这个目录下主要存放Module及其子类的定义,如。我们首先找到module.py内Module的定义

阅读__init__ 函数,可以看到Module基类的主要私有成员,其中包括
指向本Module内带梯度的可学习参数的parameter
指向本Module内不需要学习的模型状态参数的buffer
其他临时参数
前向与反向过程的hook函数,这些函数在运行backward与forward时允许自定义其它额外工作
state_dict相关函数,state_dict保存了模型的状态,是模型写入磁盘与加载的主要方式
modules指向该模块内部的所有子模块

方法分析
结构相关
- 子模块生成
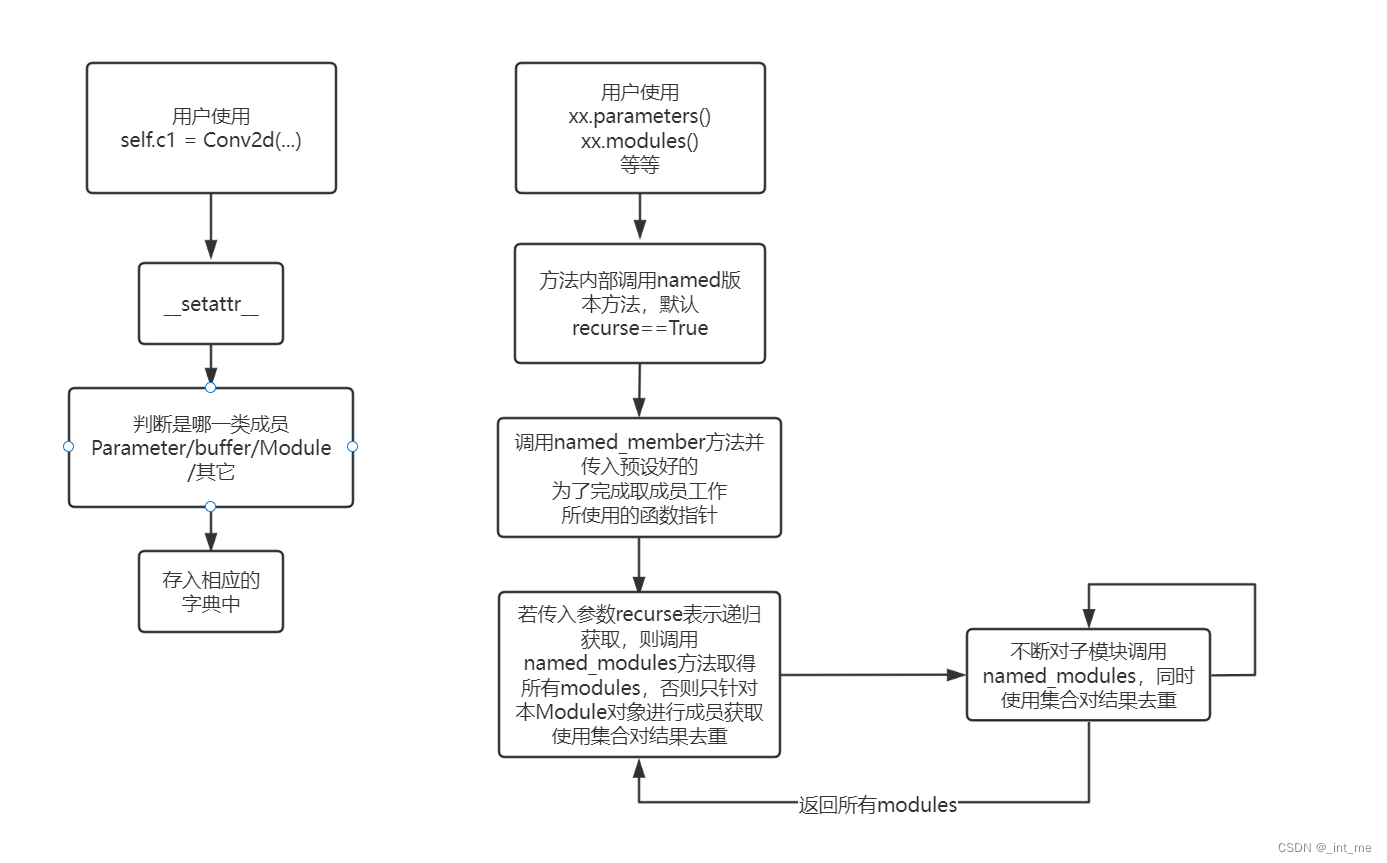
首先从我们日常使用pytorch搭建网络的用法可以想到,应该先去__setattr__函数寻找建立子节点的入口。
下图折叠了几个分支,可以看到当我们运行self.c1 = Conv2d(...)时,将会进入1202行的分支内,并且判断新成员是否是Module类型,如果是则将其放入本对象的子模块字典内。
__setattr__ 内主要对Parameter,Module,特定name的Tensor(也就是buffer)等参数做特判,其他情况则调用object的属性设置流程。事实上,其他的类似方法(如getattr等)也是同样的流程。

- 内部参数访问
对于存储于私有成员_module内的子模块,一般使用children方法进行调用

我们在外部所使用的xx.modules()方法,就是通过调用children方法实现的。
另外,nn.Module实现了许多对参数转化的方法,比如CPU(将内部参数转移到内存中),CUDA(将内部参数转移到显存中)以及type(将参数转化为指定类型),而这些是通过调用内部的_apply方法实现的

可以看到,_apply接受一个函数指针参数,并对所有的子模块递归地调用自己。然后对本Module内所有的Parameter与buffer应用该函数。
问题来了,既然每个节点都进行函数应用,那么如何避免对同一参数重复应用fn?这个问题的关键在于内部的Parameter到底是如何存储的。
印象里,我们在外部使用xx.parameters()时,得到的是xx模块的所有参数,看起来和上述代码里的_parameters并非直接取用的关系,我们可以看一下parameters()的实现

注意到默认参数recurse=True,相信大部分人已经明白原因了,我们继续看到named_parameters()

对_named_member方法传入了获取子模块_parameters字典键值对的匿名函数,继续看到_named_members()

可以看到具体流程是先递归或者不递归地获取该模块下的所有用户希望获得的东西(具体定义在第一个函数参数中),然后返回迭代器
这里1489行体现递归调用,原因是named_modules方法本身就是一个递归函数
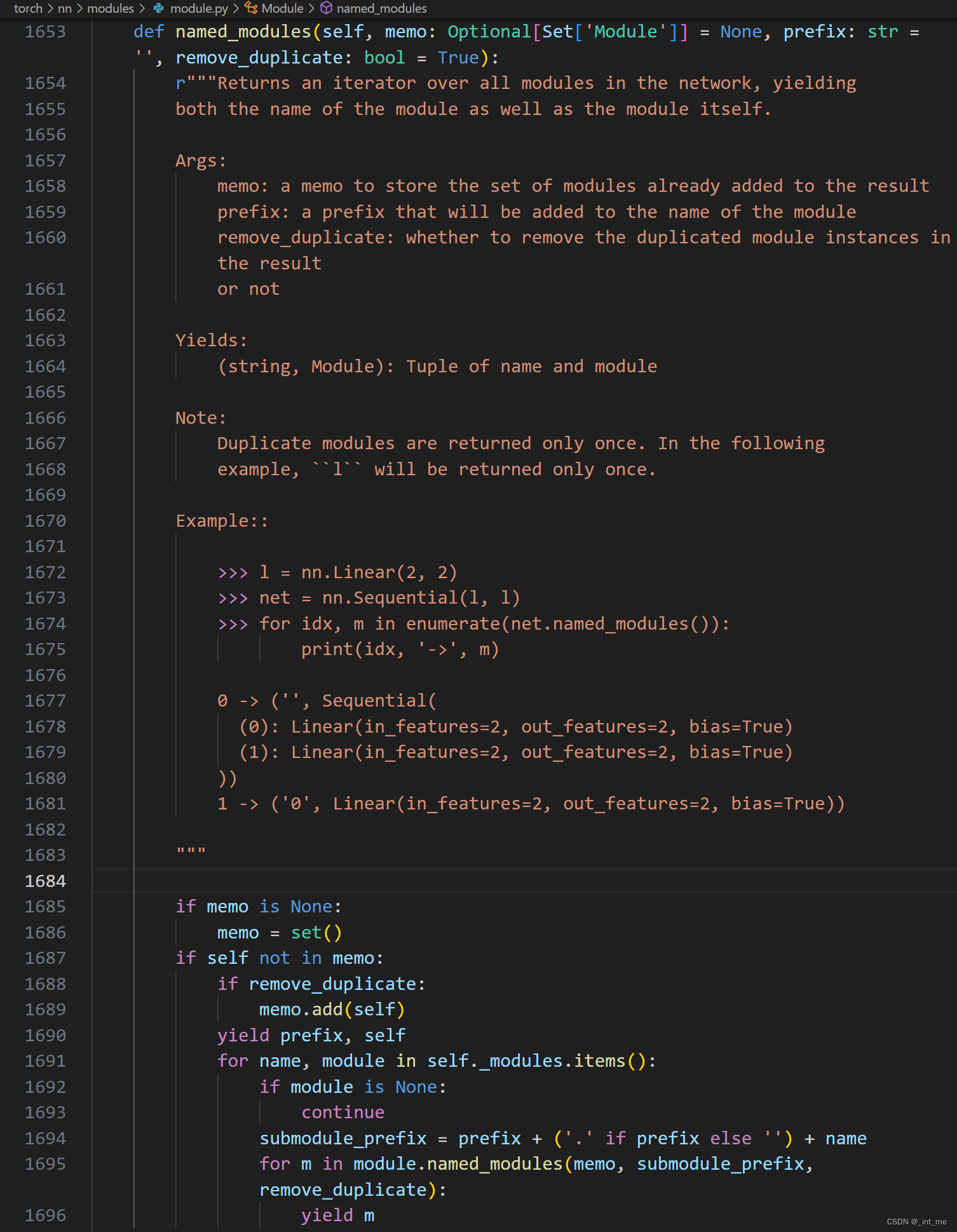
事实上,named_parameters, named_buffers均是通过named_members进而调用named_modules方法实现的,_module成员体现网络结构的特殊性在这里可以窥见一二。另外可以看到,上述方法内都存在memo集合进行去重,确保不会返回相同的指针对象。
- 简要流程图
参考文章