飞桨paddlespeech语音唤醒推理C INT8 定点实现
前面的文章(
飞桨paddlespeech语音唤醒推理C定点实现
)讲了INT16的定点实现。因为目前商用的语音唤醒方案推理几乎都是INT8的定点实现,于是我又做了INT8的定点实现。
实现前做了一番调研。量化主要包括权重值量化和激活值量化。权重值由于较小且均匀,还是用最大值非饱和量化。最大值法已不适合8比特激活值量化,用的话误差会很大,识别率等指标会大幅度的降低。激活值量化好多方案用的是NVIDIA提出的基于KL散度(Kullback-Leibler divergence)的方法。我也用了这个方法做了激活值的量化。这个方法用的是饱和量化。下图给出了最大值非饱和量化和饱和量化的区别。
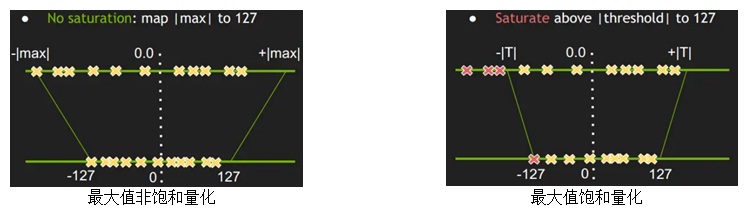
从上图看出,最大值非饱和量化时,把绝对值的最大值|MAX|量化成127,|MAX|/127就是量化scale。激活值的分布范围一般都比较广, 这种情况下如果直接使用最大值非饱和量化, 就会把离散点噪声给放大从而影响模型的精度,最好是找到合适的阈值|T|,将|T|/127作为量化scale,把识别率等指标的降幅控制在一个较小的范围内,这就是饱和量化。KL散度法就是找到这个阈值|T|的一种方法,已广泛应用于8比特量化的激活值量化中。
KL散度又称为相对熵(relative entropy),是描述两个概率分布P和Q差异的一种方法。 KL散度值越小,代表两种分布越相似,量化误差越小;反之,KL散度值越大,代表两种分布差异越大,量化误差越大。 把KL散度用在激活值的量化上就是来衡量不同的INT8分布与原来的FP32分布之间的差异程度。KL散度的公式如下:
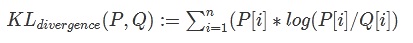
其中P,Q分别称为实际分布和量化分布, KL散度越小, 说明两个分布越接近。
使用KL散度方法前需要做如下准备工作:
1,从验证集选取一个子集。这个子集应该具有代表性,多样性。
2,把这个子集输入到模型进行前向推理, 并收集模型中各个Layer的激活值。
对于每层激活值,寻找阈值的步骤如下:
1, 用直方图将激活值分成N个bin(NVIDIA用的是2048), 每个bin内的值表示在此bin内激活值的个数,从而得到参考样本。
2, 不断地截断参考样本,长度从128开始到N, 截断区外的值加到截断样本的最后一个值之上,从而得到分布P。求得分布P的概率分布。
3, 创建分布Q,其元素的值为截断样本P的int8量化值, 将Q样本长度拓展到和原样本P具有相同长度。求得Q的概率分布 并计算P、Q的KL散度值。
4, 循环步骤2和3, 就能不断地构造P和Q并计算相对熵,最后找到最小(截断长度为M)的相对熵,阈值|T|就等于(M + 0.5)*一个bin的长度。|T|/127就是量化scale,根据这个量化scale得到激活值的量化值。
实现前读了腾讯ncnn的INT8定点实现,看有什么可借鉴的。 发现它不是一个纯定点的实现,即里面有部分是float的,当时觉得里面最关键的权重和激活值都是定点运算了,部分浮点运算可以接受, 我也先做一个非纯定点的实现,把参数个数较少的bias用浮点表示。 接下来就开始做INT8的定点实现了,还是基于不带BN的浮点实现(
飞桨paddlespeech语音唤醒推理C浮点实现
)。依旧像INT16定点实现时那样,一层一层的去调,评估指标还是欧氏距离。调试时还是用一个音频文件去调。方便调试出问题时找到原因以及稳妥起见,我将INT8的定点化分成3步来做。
1,depthwise以及pointwise等卷积函数的激活值数据以及参数等均是用float的(即函数参数相对浮点实现不变),在函数内部根据激活值和权重参数量化scale将激活值和权重量化为INT8,然后做定点运算。做完定点运算后再根据激活值和权重参数量化scale将输出的激活值反量化为float值。每层算完后结果都会去跟浮点实现做比较,用欧氏距离去评估。只有欧氏距离较小才算OK。
2,权重参数的量化事先做好。将上面第一步函数的参数中权重参数从float变为int8。在函数里根据激活值的量化scale只做激活值的量化。做完定点运算后再根据激活值和权重参数量化scale将输出的激活值反量化为float值。每层算完后结果都会去跟浮点实现做比较,用欧氏距离去评估。只有欧氏距离较小才算OK。
3,将上面第二步函数的参数中激活值参数也从float变为int8,这样激活值参数和权重参数就都是INT8。函数中权重和激活值就没有量化过程只有定点运算了。激活值得到后再根据当前层和下一层的激活值量化scale重量化为下一层需要的INT8值。需要注意的是在用欧氏距离评估每一层时要把激活值的INT8值转换为float值,因为评估时是与浮点实现作比较。
经过上面三步后一个不是纯的INT8的定点实现就完成了。以depthwise卷积函数为例来看看卷积层的处理:

从函数实现可以看出,偏置bias未做量化,是浮点参与运算的,权重和激活值做完定点乘累加后结果再转回浮点与bias做加法运算,最后做重量化把激活值结果变成INT8的值给下层使用。Input_scale/output_scale/weight_scale都是事先算好保存在数组里,当前层的output_scale就是下一层的Input_scale。
等模型调试完成后依旧是在INT16实现用的那个大的数据集(有两万五千多音频文件)上对INT8定点实现做全面的评估,看唤醒率和误唤醒率的变化。跟INT16实现比,唤醒率下降了0.9%,误唤醒率上升了0.6%。说明INT8定点化后性能没有出现明显的下降。
INT8定点实现是在PC上调试的,但我们最终是要用在audio DSP(ADSP,主频只有200M)上,我就在ADSP上搭了个KWS的DEMO,重点关注在模型上。试验下来发现运行一次模型推理(上面的INT8实现)需要近1.2秒,这是没办法部署的,需要优化。调查后发现很少的浮点运算却花了很长的时间。我们用的ADSP没有FPU(浮点运算单元),全是用软件来做浮点运算的,因此要把上面实现里的浮点运算全部改成定点的,主要包括bias以及各种scale的量化。考虑到模型中bias参数个数较少以及保证精度,我用INT32对bias以及scale做量化。看了这几种值的绝对值最大值后,简单起见,确定Q格式均为Q6.25。在卷积函数中,input_scale和weight_scale总是相乘后使用,因此可以看成一个值,相乘后再去做量化。最终一个纯定点的depthwise 卷积函数如下:

再去用那个大数据集(有两万五千多音频文件)上对INT8纯定点实现做全面的评估,看唤醒率和误唤醒率的变化。跟不是纯的INT8实现比,唤醒率和误唤醒率均没什么变化。再把这个纯定点的模型在ADSP上跑,做完一次推理用了不到400ms的时间。这样一个纯定点的INT8实现就完成了。然而这只是一个base,后面还需要继续优化,把运行时间降下来。事后想想如果模型运行在主频高的处理器上(如ARM),推理中有少部分浮点运算是可以的,如果运行在主频低的处理器上(如我上面说的ADSP,只有200M),且没有FPU,模型推理一定要是全定点的实现。