28图图解Raft协议,so easy~~
大家好,我是三友~~ 在之前写的 当文章点赞量突破28个,就单独写一篇关于Raft协议的文章 既然现在文章点赞量已经超过28个,那我就连夜爆肝,把这个坑给填上 由于Nacos使用的是实现了Raft协议的JRaft框架,所以本文主要是基于JRaft框架来讲解 本文我大致分为了下面三个方面的内容: 第一个方面就是讲解在Raft协议中,一个请求在整个集群中的处理过程 第二个方面就是讲解Leader选举相关的内容 第三个方面就是讲一讲JRaft框架做的一些优化 在这个过程中我也会穿插一些Nacos跟JRaft框架整合相关的内容 好了,话不多说,让我们直接进入主题,去会一会这个Raft协议 Raft协议是用来保证服务中各节点数据强一致性的,也就是CAP定理中的CP 在Raft协议中,集群中的服务(也可以被称为节点,Peer)会有三种状态: 当一个节点启动的时候,需要将自身节点信息注册到集群中Leader节点 比如Nacos启动的时候,就会通过JRaft提供的API
《万字+20张图探秘Nacos注册中心核心实现原理》
这篇文章中我留了一个彩蛋
一个简单的介绍
唯我独尊
的地位
CliService#addPeer
将自己注册到Leader节点中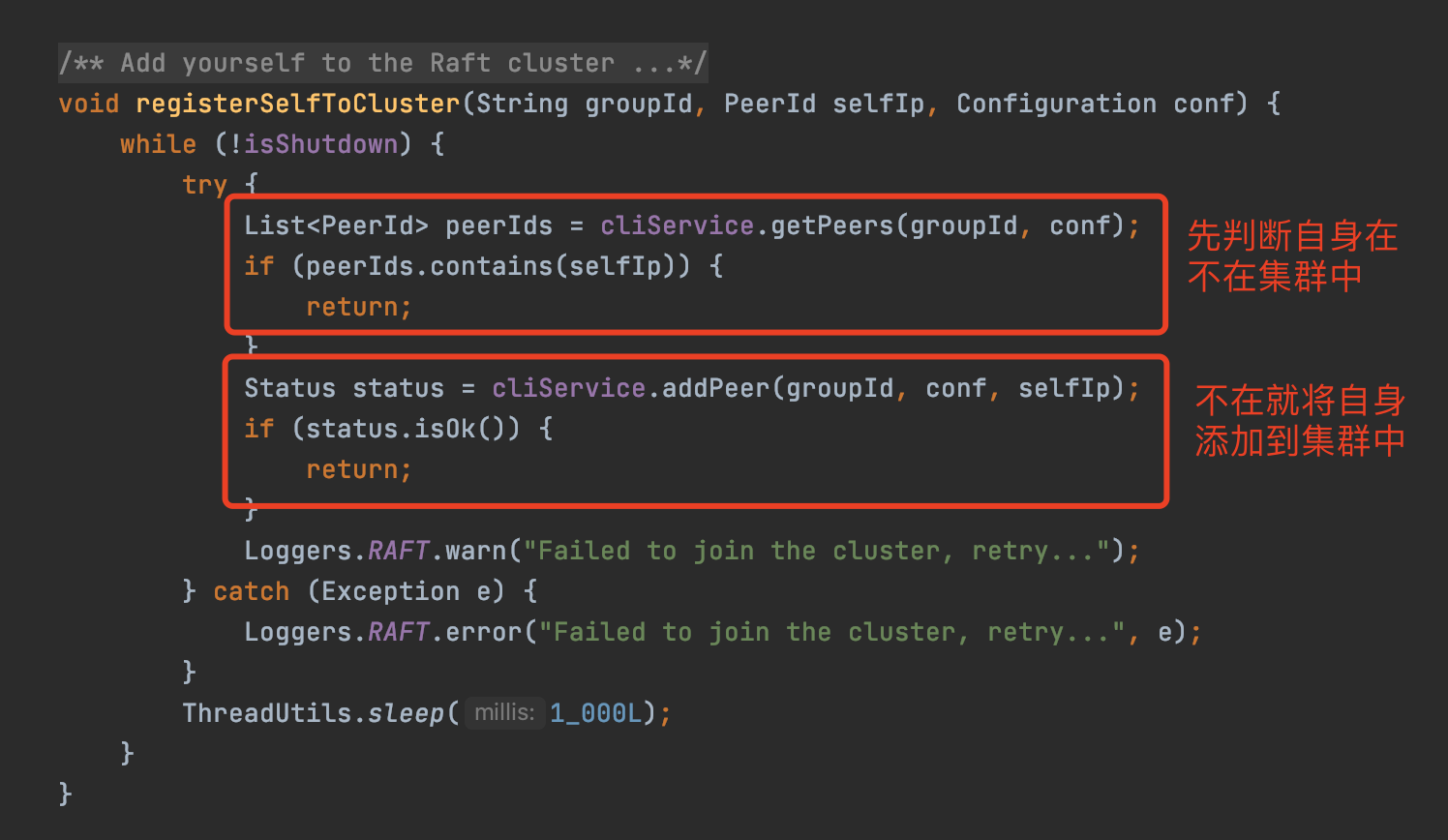
代码在Nacos的JRaftServer类
一个请求的一生
Raft协议中规定,对于一个请求,一定需要交由Leader节点来处理
服务在接收到用户请求的时候,必须得判断当前的节点是不是Leader节点
如果是Leader节点,那么就可以处理请求 如果不是Leader节点,必须将请求发送给Leader节点处理
如下是Nacos在处理请求时的代码,遵循这个规定
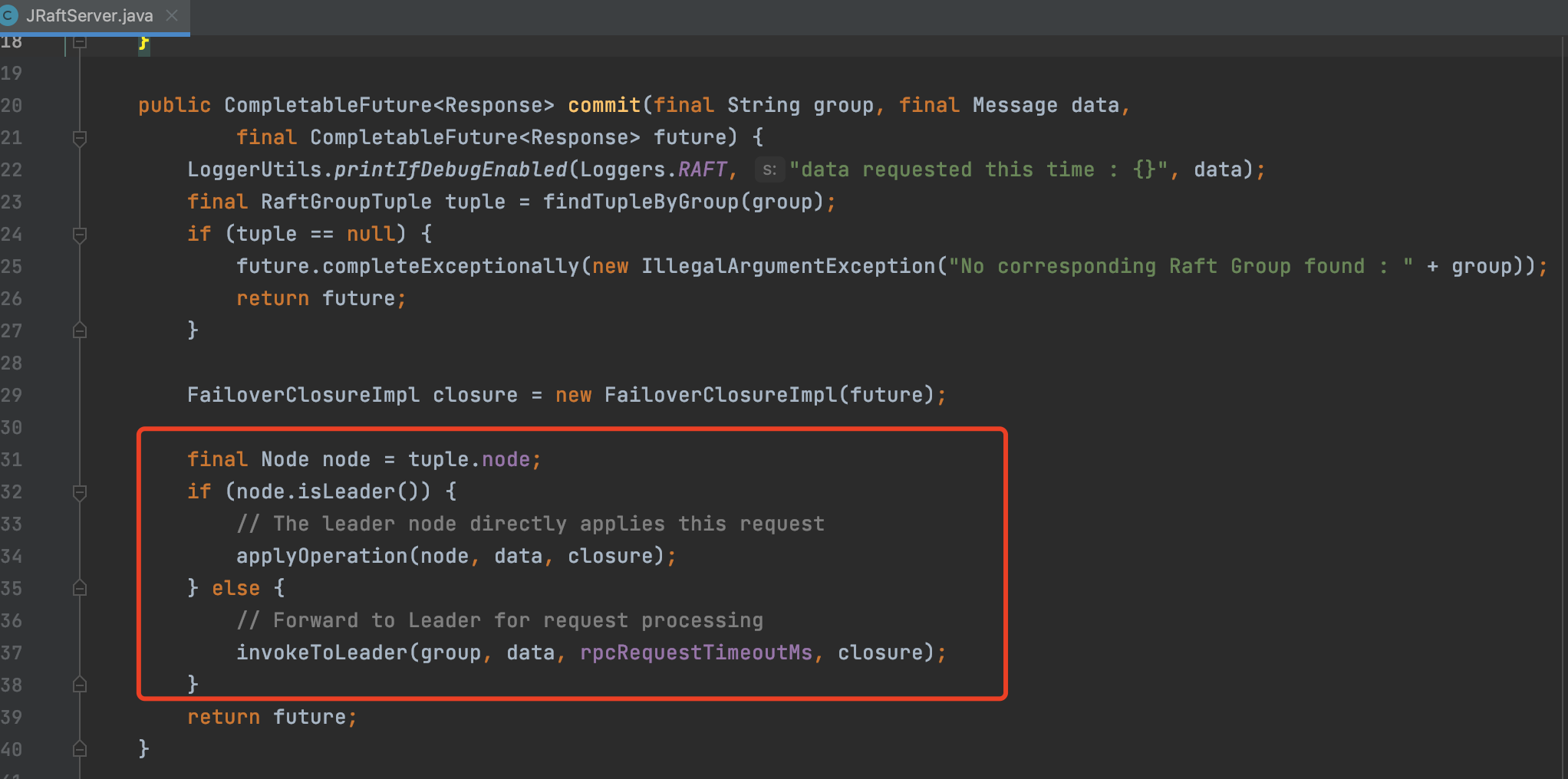
当Leader节点最终接收到请求时,这个请求才能开始被处理
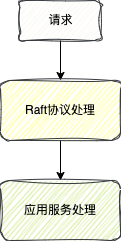
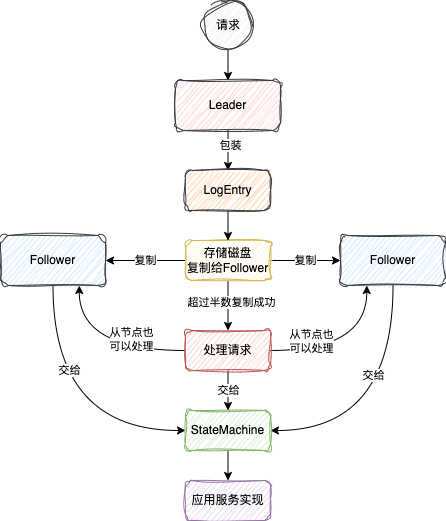
这个请求的处理过程主要分别两个部分:
Raft协议对请求的处理 应用服务对于请求的处理
Raft协议对请求的处理,是因为Raft协议是保证数据强一致性的,所以这个协议本身也需要去处理这个请求才能去保证数据强一致性
应用服务对于请求其实很好理解了,因为对于一个请求来说,肯定最终是要交给应用服务来做这个请求对应的操作
就拿Nacos注册永久服务实例举例,这个请求首先会经过Raft协议,最终有Nacos这个应用服务才会去处理这个注册服务的请求
总的来说,Raft协议其实就是本身对你应用服务的请求进行了一个前置的拦截操作,这个拦截恰恰就是用来保证数据强一致性的
最后这个请求在
能保证数据强一致性的前提下
交给应用服务,之后该怎么处理就怎么处理
1、Raft协议对请求的处理
1.1、存储请求日志
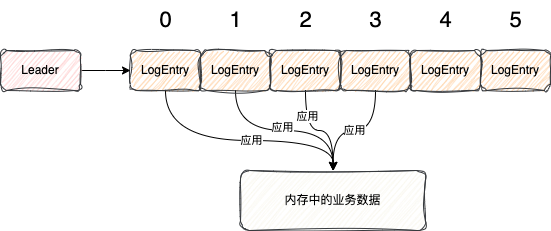
当Leader节点接收到请求,就会将请求交给Raft协议来处理
首先他会将每个请求的数据封装成一个一个LogEntry对象

同时也会给每个LogEntry设置一个index
这个index你可以
暂时
认为是LogEntry在整个集群中的唯一标识,从0开始,随着请求的顺序依次递增
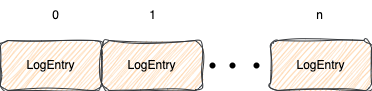
之后Raft协议会将LogEntry给存到磁盘中
这样所有请求就会按照顺序一个一个存储到磁盘中了
说到这里,我不知道你有没有想到Redis八股文中常背的AOF日志
Redis的AOF日志也是按照顺序存储所有的写操作
当Redis重启时,可以通过回放AOF日志中的命令来恢复数据
这里的LogEntry其实跟Redis的AOF日志也有相同的作用
当Raft节点重启的时候,可以通过回放LogEntry中请求来恢复数据
相信你在背八股的时候你还背过这么一句话:Redis为了防止AOF文件过大,会重写AOF日志,减小AOF文件大小。那么问题来了,Raft协议会重写LogEntry日志文件来减小日志的大小么?这个问题我们后面来说
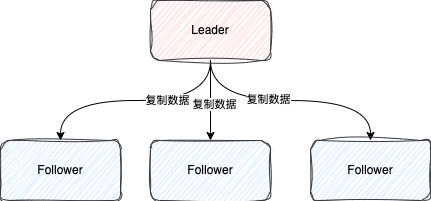
1.2、复制日志到所有Follower节点
前面说了,服务在启动时,需要向Leader注册节点信息
在JRaft中,当Leader节点接收到新的Follower节点信息的时候,会为创建一个Replicator,翻译过来就是复制器
这个Replicator会不停地向Follower节点发送请求,将LogEntry按照顺序批量复制给Follower节点
这个过程也被称为
AppendEntries
Follower节点接收到这些LogEntry之后,也会将LogEntry存到磁盘中
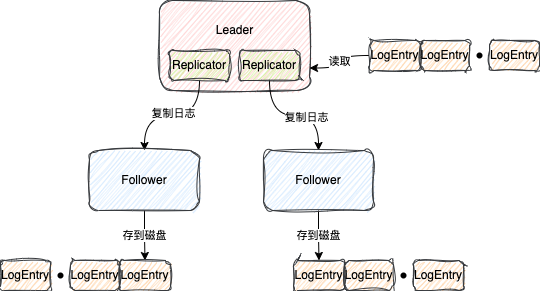
Follower与Follower之间复制LogEntry是互不影响的
1.3、提交超过半数复制成功LogEntry的index
Leader在每次批量复制成功之后都会对复制成功的LogEntry进行判断
去找到目前已经被超过半数节点都复制成功的最大LogEntry对应的index
什么意思呢,画张图你就明白了
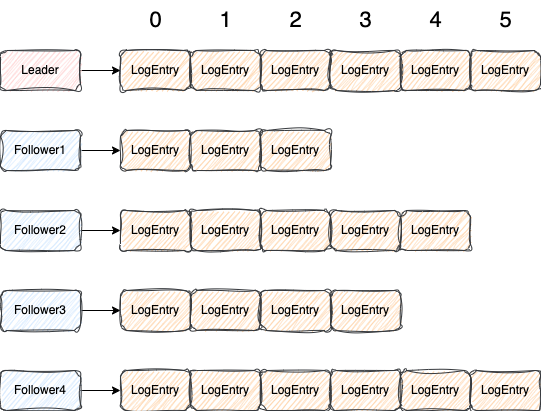
如上图,整个集群有5个节点,一个Leader,四个Follower
按照图上复制进度我们可以看出,已经被超过半数节点成功复制的LogEntry就是index=4的那个LogEntry
因为Follower2和Follower4,再加上Leader节点,这三个节点都成功有了index=4的那个LogEntry,已经超过了集群节点数量的半数
所以超过半数节点都复制成功的最大LogEntry就是index=4的那个
此时也就表明这个index之前的LogEntry都可以交由应用服务所处理
因为超过半数都能成功复制这个LogEntry,那么表明这个集群基本上就是处于稳定状态
这个index也被称为
CommitIndex
,代表可以被应用服务所处理的最大的index
接下来Raft协议就会将这个index以及之前对应的LogEntry交给应用服务来处理
同时在下次进行复制日志和心跳(后面会说)的时候,会把这个index告诉Follower节点
这样Follower节点也可以处理这些LogEntry对应的请求了
总的来说,一个请求虽然能被Leader节点所接收,但是如果没有超过半数节点复制成功,应用服务就无法处理这个请求。
如果集群发生故障,导致超过半数节点无法复制成功,那么这个请求永远不会被应用服务处理,整个集群就处于不可用状态,很符合CP的概念。
2、应用服务对于请求的处理
上一节说到,当超过半数节点已经复制了LogEntry,此时Raft协议就会将这些LogEntry,也就是请求交给应用服务处理
对于应用服务来说,它必须得去实现一个Raft协议的
状态机
才能拿到这些请求数据
这个状态机在Raft协议中非常重要,
它是应用服务与Raft协议交互的重要桥梁
当Raft协议有什么状态变动的时候,都会调用状态机来通知我们的应用服务
所以状态机不仅仅可以拿到可以处理的请求数据,还可以拿到Raft集群变动的信息
在JRaft框架中,定义了一个
StateMachine
接口来代表状态机
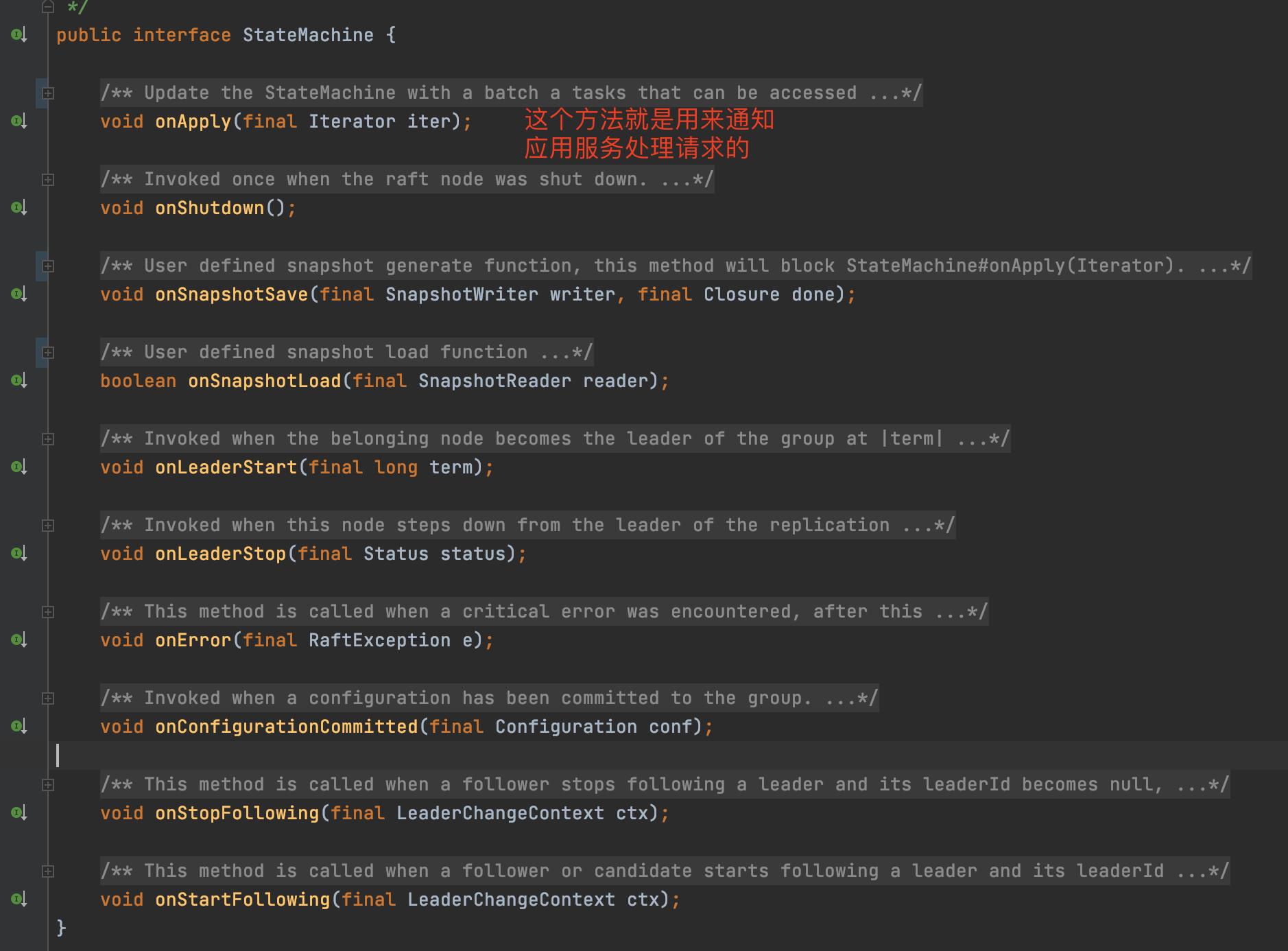
Nacos在整合JRaft框架的时候,自然而然也会(间接)实现这个状态机
当应用系统拿到这个请求数据之后,就可以做对应的业务处理了。
对于Follower节点来说,最终也是调用状态机来处理请求的。
到这,一个请求就算真正完成了
按照传统,这里画一张图来总结整个请求的一生
3、快照(Snapshot)
前面在说LogEntry留了这么一个问题
Raft协议会重写LogEntry日志文件来减小日志的大小么?
答案其实是不会的。
因为很简单,Redis的业务数据的格式Redis本身是知道的,所以他可以根据最新的数据来重新生成AOF文件
但是Raft协议本身肯定不知道你应用系统的业务数据的格式,所以无法重写LogEntry日志文件减小日志的大小
但是无法重写就意味要忍受LogEntry日志越来越大,占有磁盘的空间变大么?
肯定是不会的,LogEntry日志越来越大不仅仅会占有磁盘空间变大,还会导致重启或者故障恢复越慢,因为重启需要一个一个重新处理LogEntry对应的请求
所以,为了解决上述问题,Raft就提供了优化的手段,也就是本节的标题:
快照(Snapshot)
所谓的快照,就是将某一时刻内存中的业务数据给存到磁盘中
这时,我相信你又又想到了Redis八股文中的RDB文件,RDB文件也是某一时刻内存中的数据,所以Raft快照的意思跟RDB文件是很相似的
由于只有应用服务知道内存中的业务数据,所以执行快照这个具体的操作是交给由应用服务来完成的
但是整个过程是由Raft协议去决定是否需要落磁盘
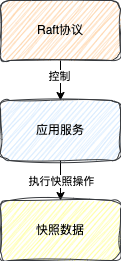
在JRaft框架中,所有的节点默认是每隔1小时执行一次快照任务
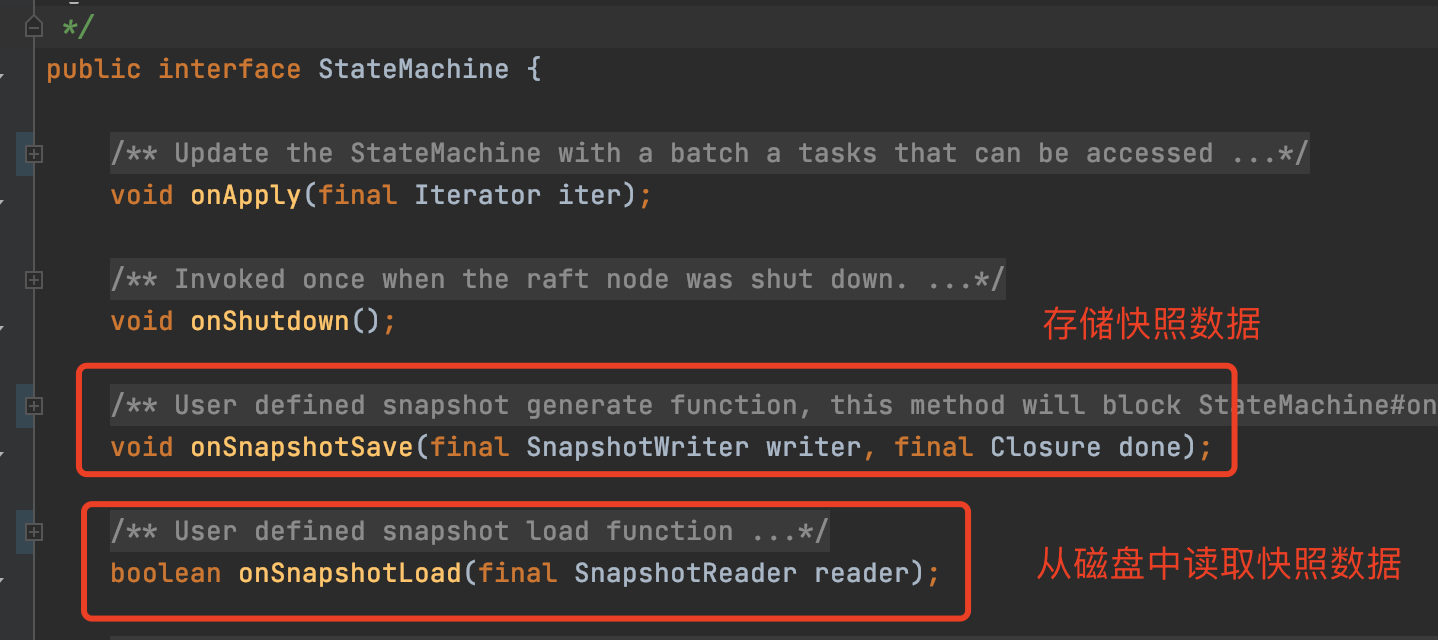
JRaft会调用状态机的
onSnapshotSave
方法,告诉应用服务去生成快照
当然Nacos也实现了这个方法
比如对于永久实例来说,Nacos最终会走到下面这个方法将实例数据存到磁盘
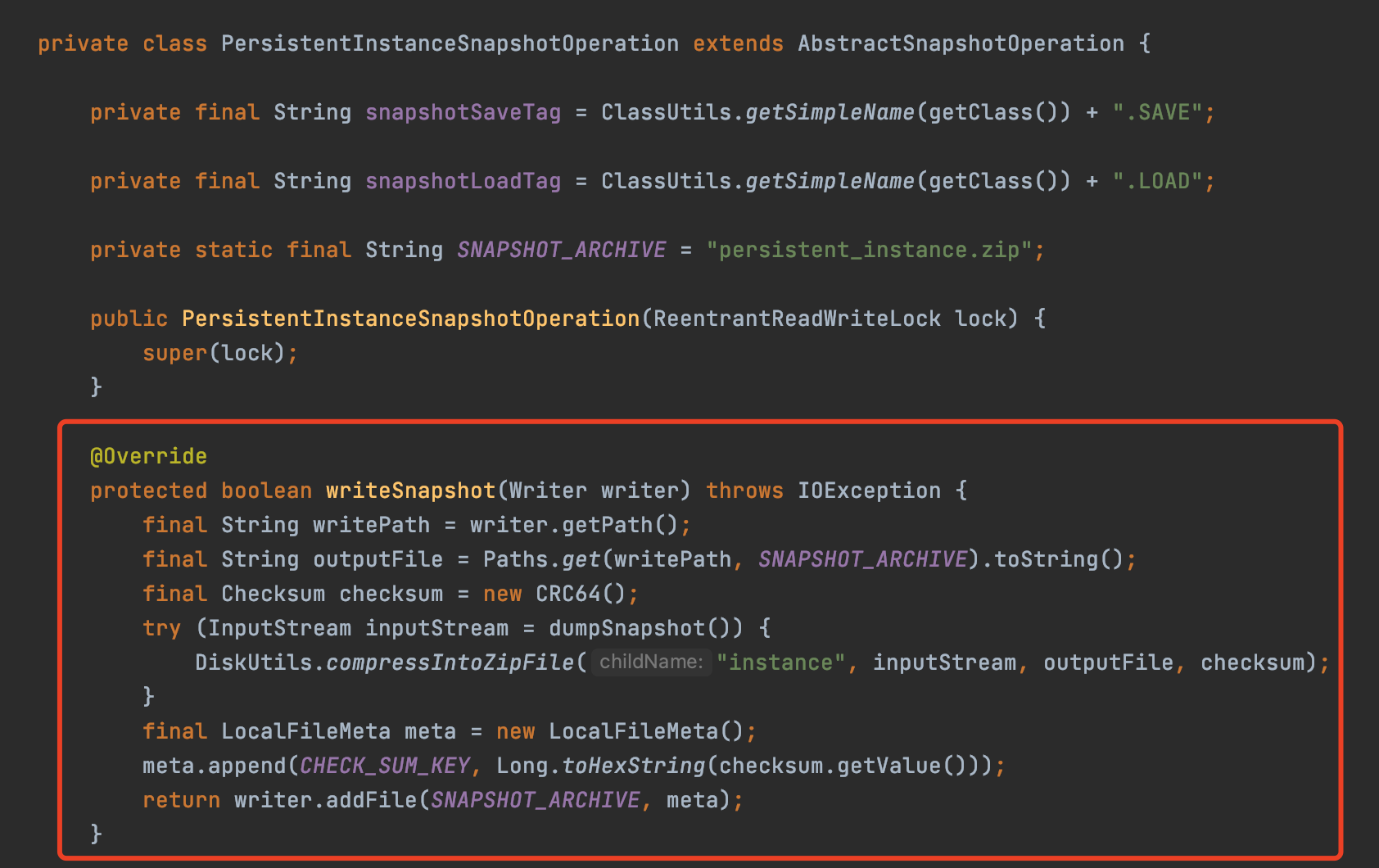
当执行完快照之后,此时应用到这个快照数据之前的LogEntry都可以被删除了
整个过程如下图所示
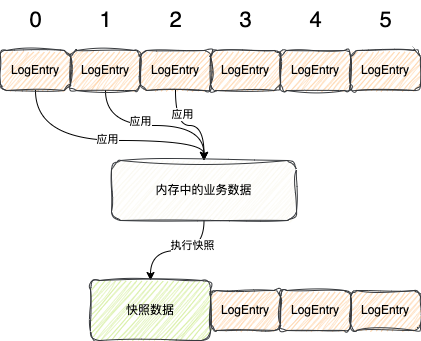
所以,对于Raft协议来说,他的真正数据是包括
快照 + LogEntry
两部分
重启恢复的时候,只需要读取快照数据,然后再处理生成快照之后所处理LogEntry,就可以快速恢复数据了
Redis在4.0版本之后支持混合RDB+AOF的日志来快速恢复数据,这其实就是跟Raft协议的快照+LogEntry恢复数据几乎是一样的原理,所以你看看,很多框架、中间件他们的一些原理都是相似的
快照除了能减少磁盘,快速恢复之外,还有一个很重要的功能,能够提高Follower复制LogEntry的速度,比如下图的这种情况
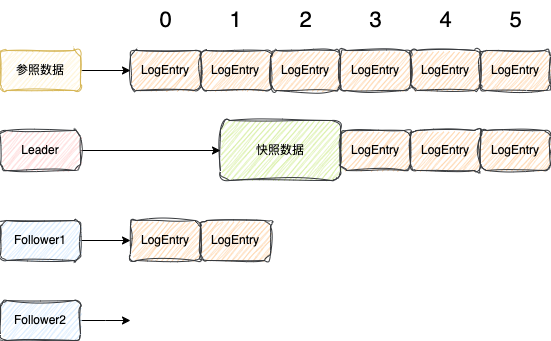
某一时刻,Leader生成快照之后,之后最小的日志索引就是index=3了,其余的日志都删了
Follower1由于复制的慢,才复制到了index=1的位置,接下来要复制index=2的位置
Follower2新加入的节点,没有数据,接下来要从index=0开始复制
Leader节点在复制数据给Follower的时候,发现Follower接下来要复制的index都已经小于我本身最小的日志了,已经没有办法复制给Follower
此时他就会向Follower发送一个
安装快照
的请求
Follower接收到请求之后,会向Leader发送一个请求,拉取快照数据,将快照数据存到磁盘文件中
之后Follower会调用状态机的
onSnapshotLoad
方法,让应用服务加载这些快照数据到内存中
之后Follower节点只需要复制这个快照之后的LogEntry就可以了,如下图所示
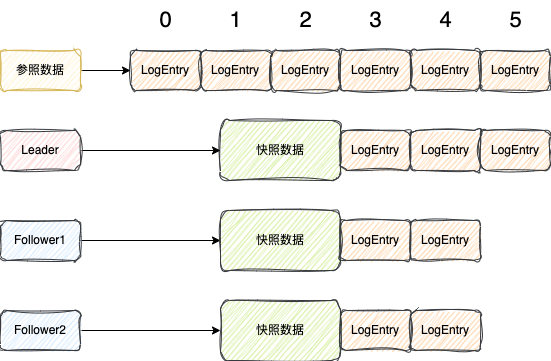
总的来说,快照主要有两个用途,一是减少LogEntery文件大小,帮助重启快速恢复数据,二是可以加快Follower节点的复制进度
选举算法
好了,说完一个请求是怎么在Raft协议中处理之后,接下来讲一讲Raft协议是如何选举Leader节点的
1、选举周期与选举时机
在说选举之前,有两个东西得说一下
选举周期(term) 选举时机
1.1、选举周期
选举周期,也可以叫任期,这个东西非常重要,那么怎么理解呢
举个例子,比如说,在上学的时候,要选择课代表
总共有3个名候选人,要班里的同学投票,规定得票超过半数的人竞选成功
第一次投票,没人得到超过半数票
接下来进行第二次投票、第三次投票...
这里面每一轮投票在Raft协议中就代表一次选举周期,选举周期也会随着选举次数一直递增
Raft协议规定,
在同一个周期中
每个节点只能投一次票 最多只能有一个节点成为Leader节点,当没选出Leader节点时,此时就会进入下一个周期选举
周期会保存在每个节点的内存中,在一个已经选举稳定运行的集群中,每个节点的周期是一样的
前面在介绍LogEntry的时候,我说过暂时可以认为index全局唯一的
之所以这么说,主要是因为真正的可以判断一个唯一的LogEntry,需要通过周期(term)和index一起判断
当生成LogEntry,其实会将当前的集群的周期和index一起写入到LogEntry中
为什么要通过两个一起判断呢?举个例子,如下图所示
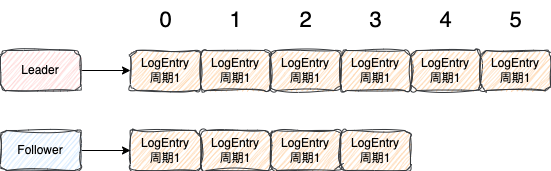
集群中有很多节点,我只画了两个
某一时刻出现了上图,在周期1时,Leader节点的index已经到了5,而Follower值复制到了index=3
假设此时Leader网络出现故障,于是集群开始重新选举
此时选举出图上的Follower作为新的Leader节点,选举周期增加到了2
此时新的Leader(原先Follower)会接收新的请求,写LogEntry,此时他会接着本身的最大的index=3继续按顺序写日志

所以从这可以看出,仅仅只根据同一个index并不能确定是同一个LogEntry
如果此时原Leader恢复了网络,就会成为Follower,接收新的Leader的LogEntry
由于Leader
唯我独尊
的地位,此时这个Follower需要丢弃之前周期1的index=4位置的LogEntry,复制Leader的日志
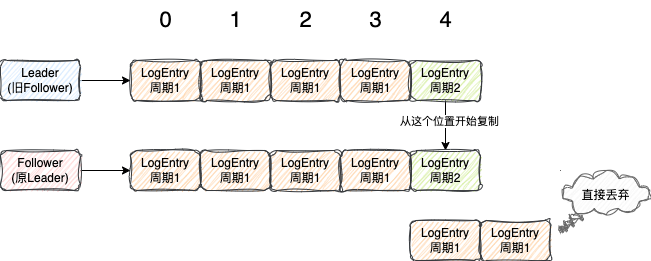
所以从这可以看出,比较两个日志谁的更新,需要先判断周期,周期越大越新,周期相同再判断index,index越大越新
记住这句话,选举的时候有用
1.2、选举时机
就是当Follower超过一定时间没有接收到Leader节点的心跳,这个Follower节点就会开启选举
在一个集群中,Leader会不停地向每个Follower节点发送心跳保持自己的领导地位
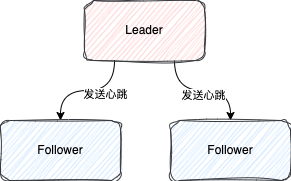
并且这个心跳机制的实现是通过复用
日志复制接口
的
Leader会构建一个LogEntry,这个LogEntry中并没有携带什么用户的请求数据,但是会携带
CommitIndex
信息,方便Follower及时将可以处理的LogEntry交由应用服务处理
当Follower发现LogEntry没有请求数据,就知道是心跳信息,就不会将LogEntry给落到磁盘了,仅仅只是更新Leader节点的心跳时间
其实,只要通过日志复制接口来的数据,都会更新心跳时间,不仅仅是心跳包,复制真正日志的时候也更新心跳时间
在JRaft框架中,
每个Follower
会开启一个定时任务,每隔1~2s去判断最后一次心跳时间,如果发现超过1s没接收到心跳信息就会开启选举
所以每个Follower都可以发起选举,只要超过一定时间没收到心跳信息
2、StepDown
在说选举之前,再讲一个很重要的
StepDown
操作,可以翻译为
下台
的意思
这个操作规定,集群中所有的节点,
一旦发现集群中有更大的周期
请求和响应数据都需要携带自身节点的周期,所以每个节点都可以知道集群中其它节点的周期
那么此时这个节点必须进行
StepDown
操作
这个
StepDown
操作包含下面三步:
将自身的周期设置成其它节点这个更大的周期 状态重新设置成Follower 重新开启选举倒计时,检查心跳,一旦又超过1~2s没接收到新,就基于这个更大的周期再次递增,再次开始选举
所以这个
StepDown
操作说白了就是让周期更低的节点去等待其它周期更高的节点成为Leader节点(不一定会成)
这一节很重要,如果接下来选举如果有什么想不通的,多读这一节
3、预选举
当Follower可以发起选举的时候,并不会直接选举,而是先进行一波预选举
在原始的Raft协议中是没有预选举机制,预选举是JRaft框架做的优化
所谓预选举就是在正式选举之前去判断一下自己是不是有潜质,很大几率成为Leader
那么为什么JRaft框架要加入预选举机制?
主要是因为如果在选举过程中出现网络问题,很多节点同时发生选举,导致选举冲突,无法正确选出Leader节点,造成多次无效的选举尝试,进而影响集群的稳定性和可用性
所以为了保证稳定性,只有当当前节点在预选举中可以成为Leader节点,当前节点才会开启真正的选举
预选举的过程并不会改变当前节点的各种状态,仅仅只会向所有的其它节点发送预投票请求,携带下面这些数据
当前周期+1,说明准备在下个周期开始选举了 当前复制最后一条LogEntry对应的term和index,为了比较谁的日志更新
当其它节点接收到请求的时候,在投票的时候遵循下面几个原则:
当前节点与Leader节点的心跳正常,说明Leader节点每什么问题,投否定票 发起预投票的节点的周期比自己的小,说明其它节点可能都已经发生好几轮正式选举了,那么你就别凑选举的热闹了,直接投否定票 发起预投票的节点复制的日志没有当前节点复制的日志新,直接投否定票
当前面都判断条件都过了之后,那么就会给这个节点投赞成票
当超过半数节点都投了赞成票,那么当前节点就可以正式发起选举了
4、正式选举
当正式选举开始的时候,当前节点会进行一些准备操作:
选举周期加1,比如原来是2,现在就为3 将当前状态从Follower转换成Candidate,表明这个节点成为候选者 将当前这个周期的票投给自己,自己发起选举的,这个票优先投给自己
当这波操作完成之后,就开始构建请求,携带的信息跟预投票是一样的,包括:当前递增后周期、当前节点复制的最新的LogEntry对应的周期(term)和index,然后向所有的节点发送请求
当其它节点接收到请求之后,也会进行一系列判断
发起预投票的节点的周期比自己的大,投赞成票,并且会StepDown操作 发起预投票的节点的周期比自己的小,则直接投反对票 周期相等,如果已经投票给自己或者别人,则投否定票;否则判断日志谁的更新,如果自己的日志更新则直接投反对票,否则就投赞成票
其实正式投票判断条件跟预投票的判断很像
当收到超过半数的节点的赞成票之后,当前节点就可以成为Leader节点了
之后这个节点就会接收请求,将LogEntry复制给其它从节点,同时维护与从节点之间的心跳
JRaft的一些优化
JRaft的优化很多,比如几乎全链路异步、批量并行复制LogEntry、预投票机制等等
这点我再说几点功能性的优化
1、线性一致读
前面说到请求的一生的时候我说过,所有请求都需要交给Leader节点来处理
但是你可以思考个问题
对于
读请求
来说,真的有必要都交给Leader节点来处理么?
其实是没有必要的
因为虽然Leader节点可以处理,但是Leader节点在处理这个读请求时也会走一遍Raft协议
将读请求的数据封装成LogEntry,然后复制到Follower,最后过半复制成功再处理这个读请求
由于读请求来说并不涉及到数据修改,不会造成数据不一致性
所以走上面这段逻辑并没有任何好处,反而对提高Leader节点处理请求的压力
所以,为了减轻Leader节点的压力,提出了一种叫线性一致读的方式来处理读请求,可以让从节点处理
读请求
线性一致读是Raft协议提出的优化,JRaft框架实现了这个逻辑
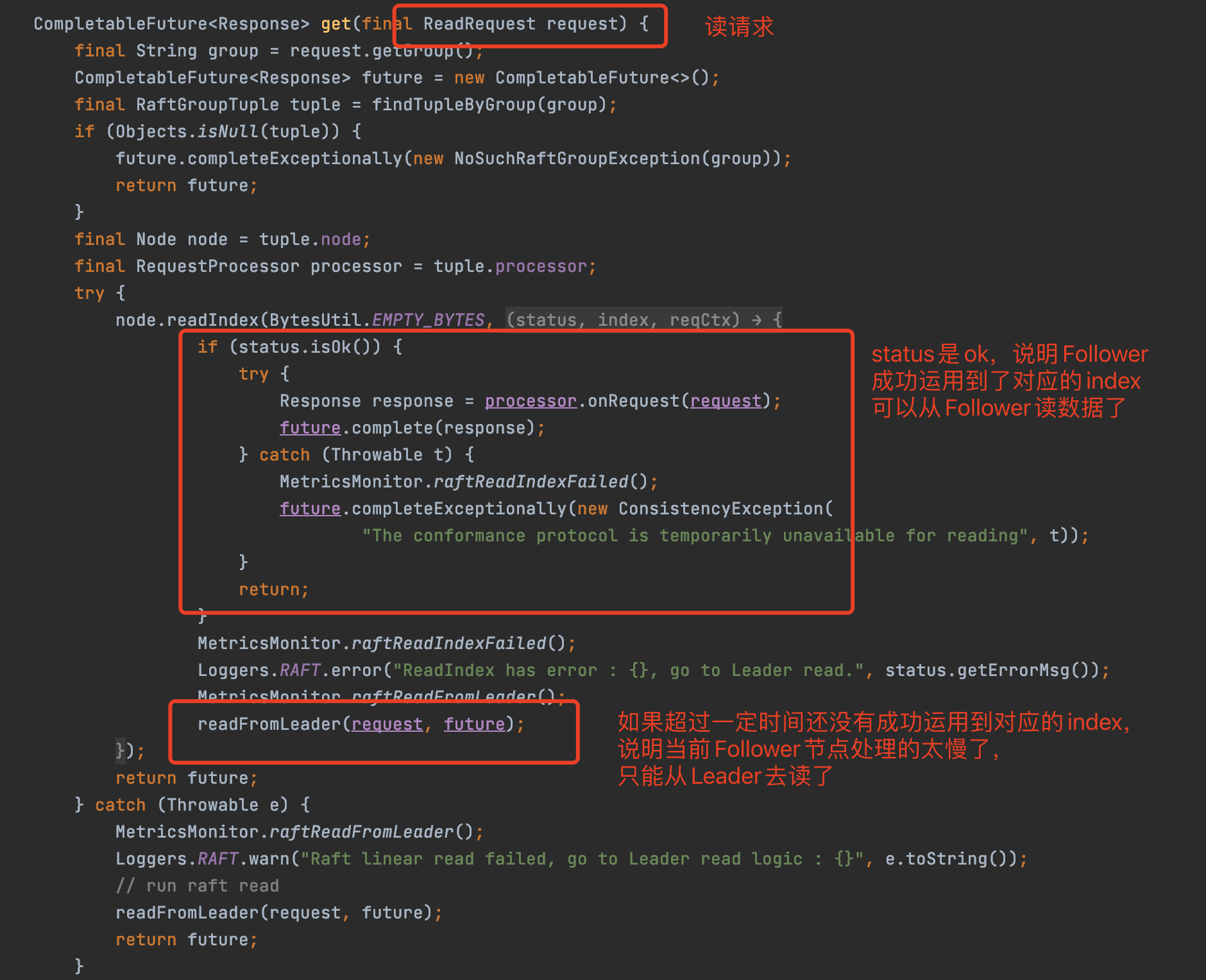
如上图,假设
t时刻
去读数据,此时Leader节点已经将index=3的LogEntry应用到状态机
由于Follower节点和Leader节点都是一样的,按照顺序处理LogEntry请求的数据,也就是线性处理
所以只要等到Follower节点也处理到index=3的LogEntry,那么此时Follower节点就和
t时刻
的Leader节点的数据是一样的了
之所以是
t时刻
Leader节点数据,是因为Leader节点可能会继续应用LogEntry,但是由于读发生在
t时刻
,所以只要Follower节点运用到的index是
t时刻
Leader节点的index就可以了
这样就可以处理从Follower节点处理这个读请求了,读到数据了
线性一致读底层实现也比较简单,就是每次读得时候都去从Leader节点去查找此时Leader节点运用到的index大小
然后当Follower节点应用到的index跟Leader节点是一样的,此时就可以从Follower节点读数据了
所以前面说的那句所有的请求都一定要交给Leader处理,其实可以改成所有的写请求一定要交给Leader处理,读请求可以通过线性一致读交给Follower节点处理
Naocs在读数据的时候就使用到了线性一致读
代码在Nacos的JRaftServer类
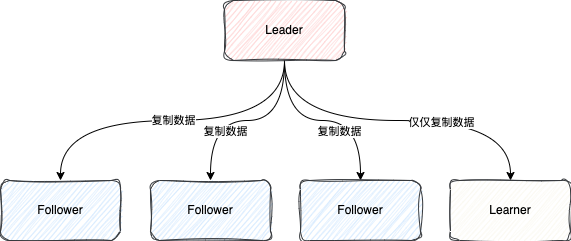
2、Learner
在JRaft会有一个Learner的概念,翻译过来就是学习者的意思,也被称为
只读成员
所以从名字也可以看出,当一个节点是Learner节点,那么这个节点仅仅只从Leader节点复制数据,并不参与选举、投票和日志复制成功确认
如果当前节点想表明自己是一个Learner的话,在向Leader节点注册的时候,可以通过
CliService#addLearners
这个API就可以了
这个Learner节点的作用可以用来创建一个只读的服务,通过线性一致读实现类似读写分离效果
3、Multi-Raft-Group
Multi-Raft-Group也是JRaft中一个重要的特性
由于所有的写请求都需要交给Leader处理,一个Leader由于只在一台机器,所以就会导致Leader所在的机器压力很大
基于这个问题,就提出了Multi-Raft-Group
所谓的Multi-Raft-Group,你可以理解的是多租户隔离,通过一个分组(Group)进行隔离
每个组都是有自己的Leader,有自己的单独选举,完全相互不影响
就有点像上学时课代表的意思,每个课代表处理不同的学科的任务,互不影响
举个例子,假设现在有三台机器

我们可以根据系统功能或者数据进行分组,分为A、B、C三个组
此时A组的Leader可能是机器1,B组的Leader可能是机器2,C组的Leader可能是机器3
这样对于不同的组,对应的写请求就可以交给不同的机器处理,这样就解决了一个Leader只在一个机器导致压力大的问题
这就是Multi-Raft-Group
由于有分组,这就导致所有的请求都得携带group的信息,表明这个请求属于哪个组,所以前面提到的所有请求参数其实都得携带group名称
既然有这个分组的功能,Nacos也肯定使用了,对于不同的功能有不同的分组
Nacos目前有4个分组,名称如下图所示

总结
到这就讲完了Raft协议大致内容以及它的实现JRaft框架
这篇又又又是洋洋洒洒写了近万字,根本停不下来
由于Raft协议这种技术栈可能没那么受众
所以不知道有多少人能坚持看到这里
如果你坚持看到这里,觉得本篇对你有点帮助,欢迎点赞、在看、收藏、转发分享给其他需要的人
你的支持就是我更新的最大动力,感谢感谢!
好了,本文就讲到这里,让我们下期再见,拜拜。
往期热门文章推荐
扫码或者搜索关注公众号
三友的java日记
,及时干货不错过,公众号致力于通过画图加上通俗易懂的语言讲解技术,让技术更加容易学习,回复 面试 即可获得一套面试真题。
