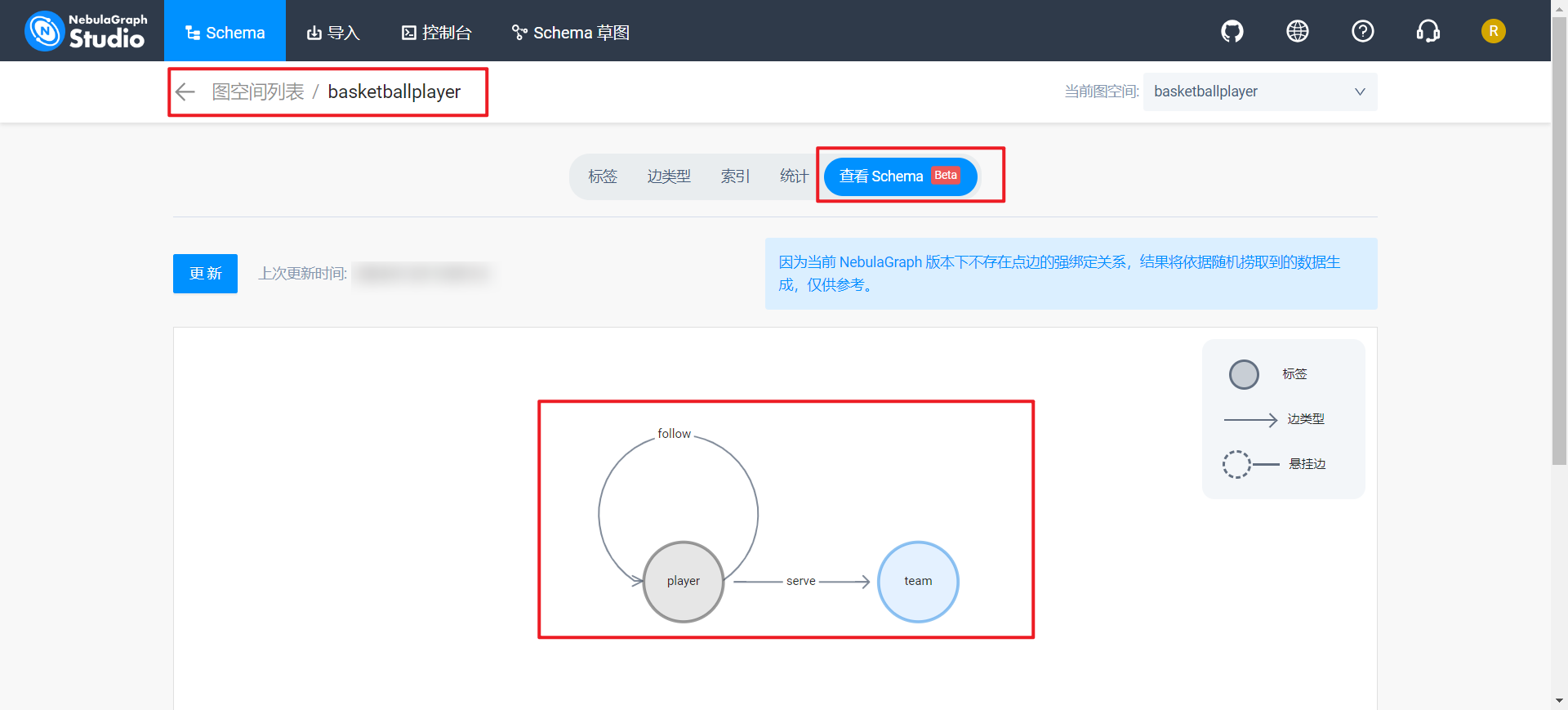
本文重点分析 Nebula Siwi 智能问答思路,具体代码可参考[2],使用的数据集为 Basketballplayer[3]。部分数据和 schema 如下所示:
一.智能问答可实现的功能 1.Nebula Siwi 源码整体结构 主要包括前段(Vue)和后端(Flask)代码结构,整体结构如下所示:
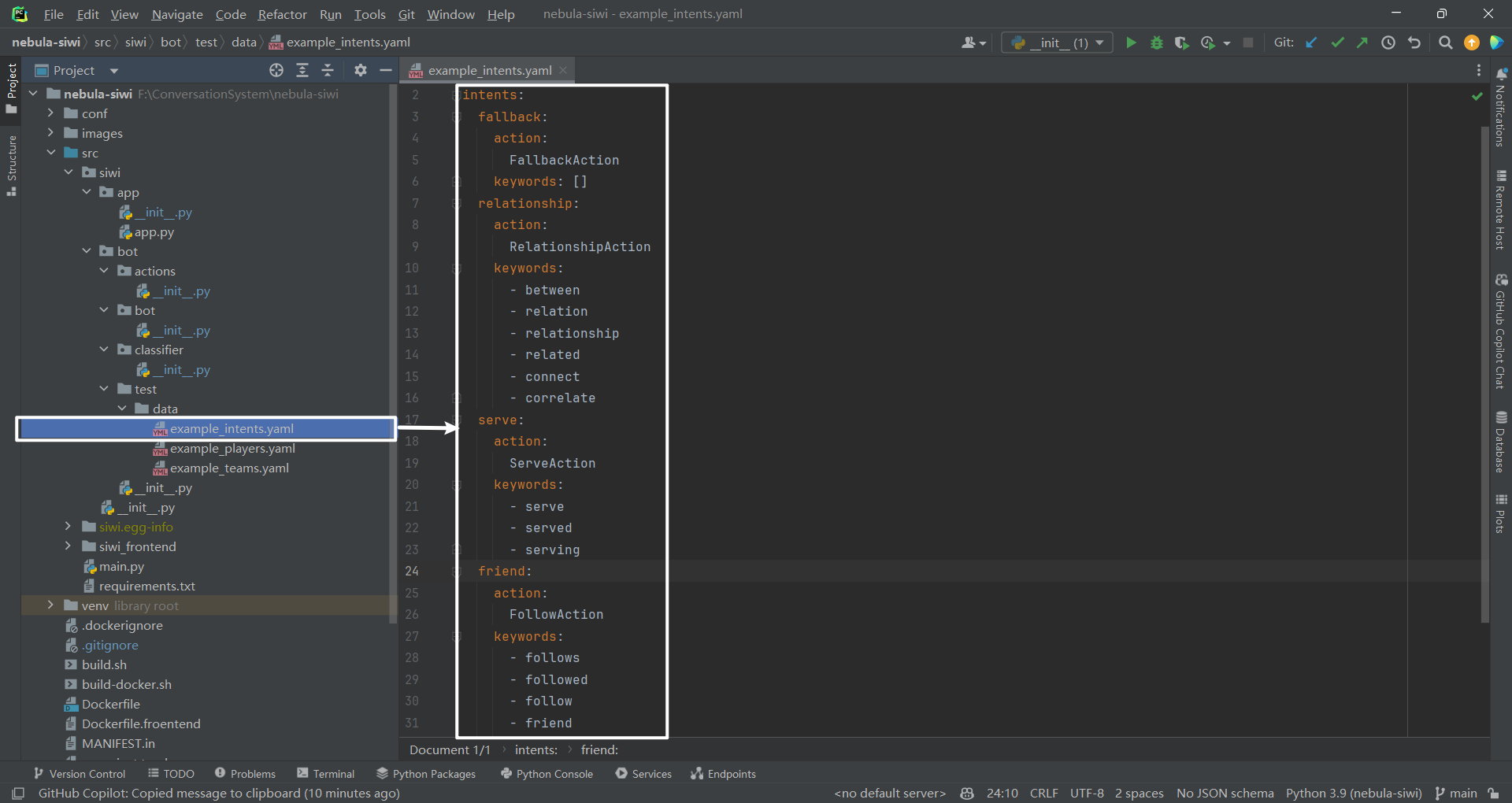
2.Basketballplayer 数据集介绍 Basketballplayer 数据集简介可参考文献[7]NebulaGraph 手工和 Python 操作
import_data.py
什么是 nGQL - NebulaGraph Database 手册
说明:因为本地数据库已经有了一个 basketballplayer 的图空间了,索引本次导入数据使用的是 basketballplayers 图空间。
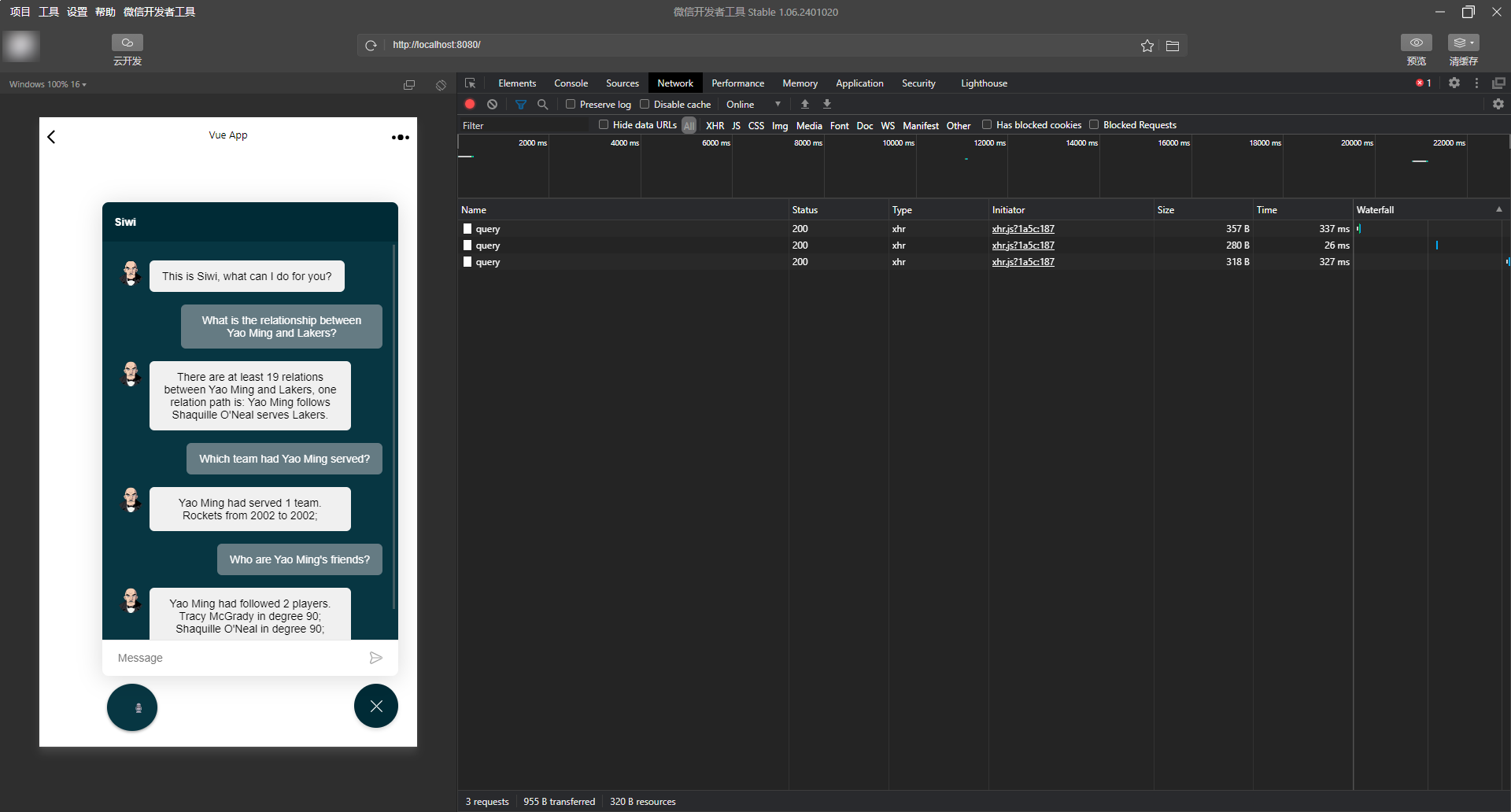
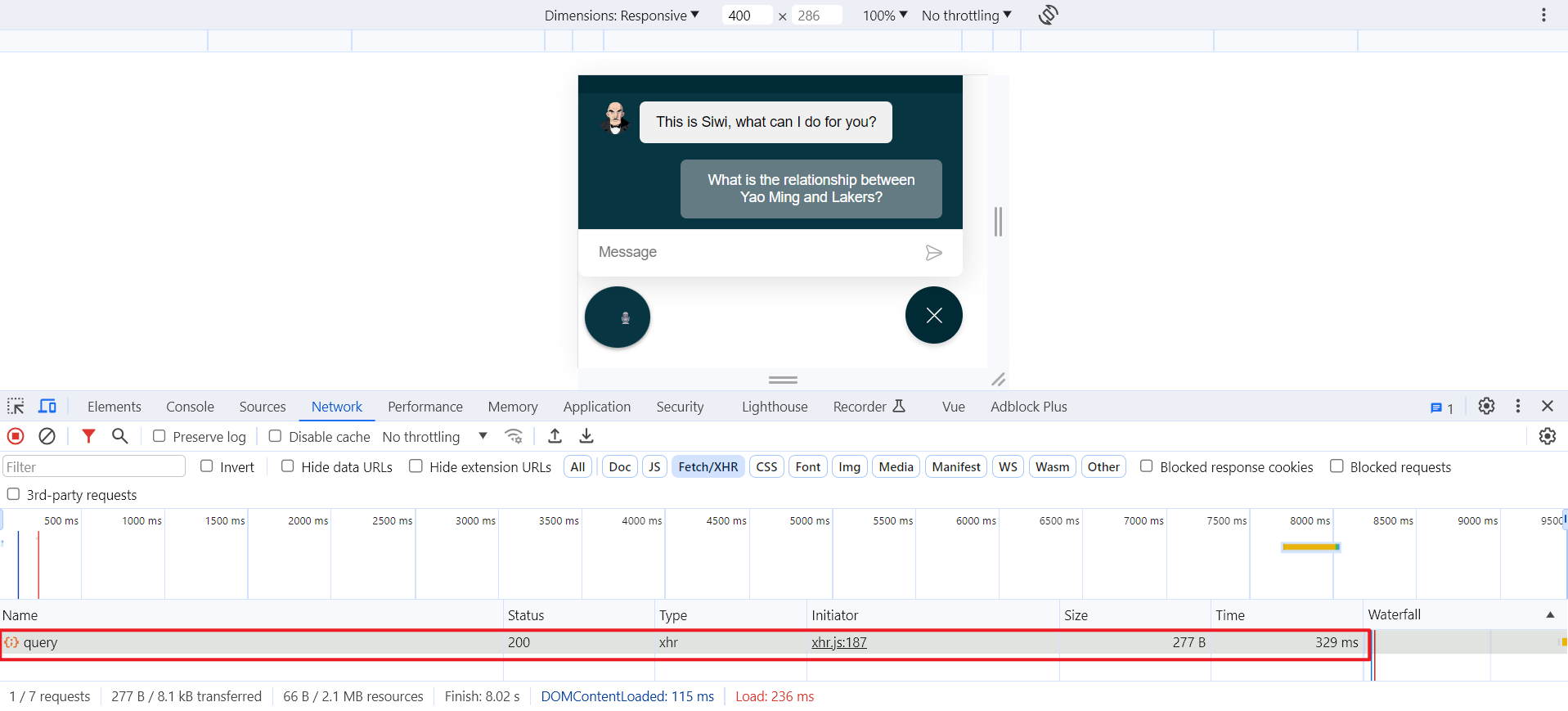
3.QA 可实现的功能 "" " "" 使用微信开发工具测试效果,如下所示:
二.智能问题功能实现思路 1.前端实现思路[4] 1.1安装依赖包 WebStorm 打开 Vue 项目后,执行命令安装包
npm install --save-dev @vue/cli-service
npm install
npm run dev
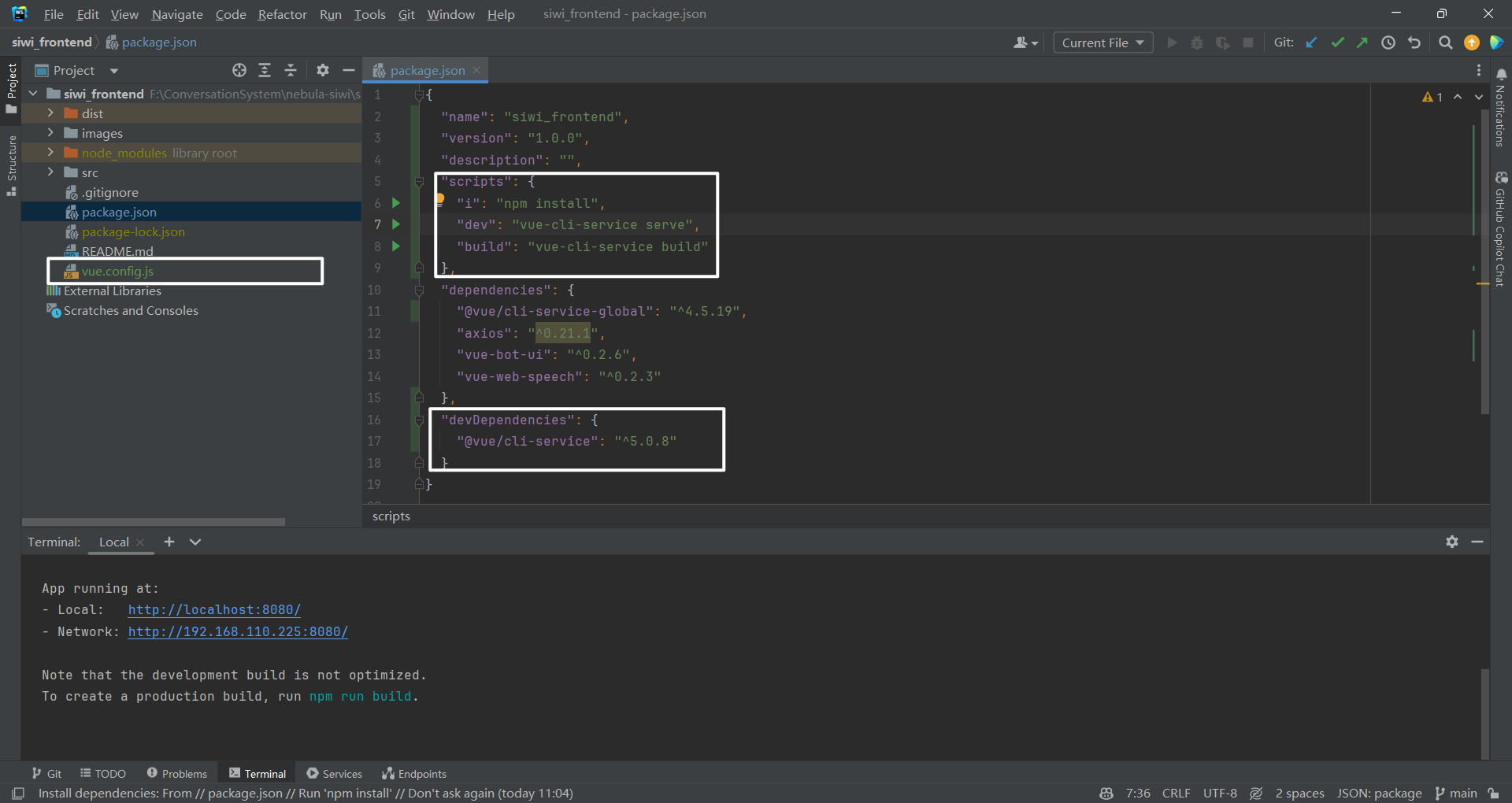
1.2修改 package.json 文件 需要说明的是需要修改 package.json,如下所示:
{"name" : "siwi_frontend" ,"version" : "1.0.0" ,"description" : "" ,"scripts" : {"i" : "npm install" ,"dev" : "vue-cli-service serve" ,"build" : "vue-cli-service build" "dependencies" : {"@vue/cli-service-global" : "^4.5.19" ,"axios" : "^0.21.1" ,"vue-bot-ui" : "^0.2.6" ,"vue-web-speech" : "^0.2.3" "devDependencies" : {"@vue/cli-service" : "^5.0.8" 1.3增加 vue.config.js 文件 同时还需要增加一个
vue.config.js
module.exports = {'http://localhost:5000' ,1.4通过浏览器进行对话 使用浏览器打开链接 http://localhost:8080/,如下所示:
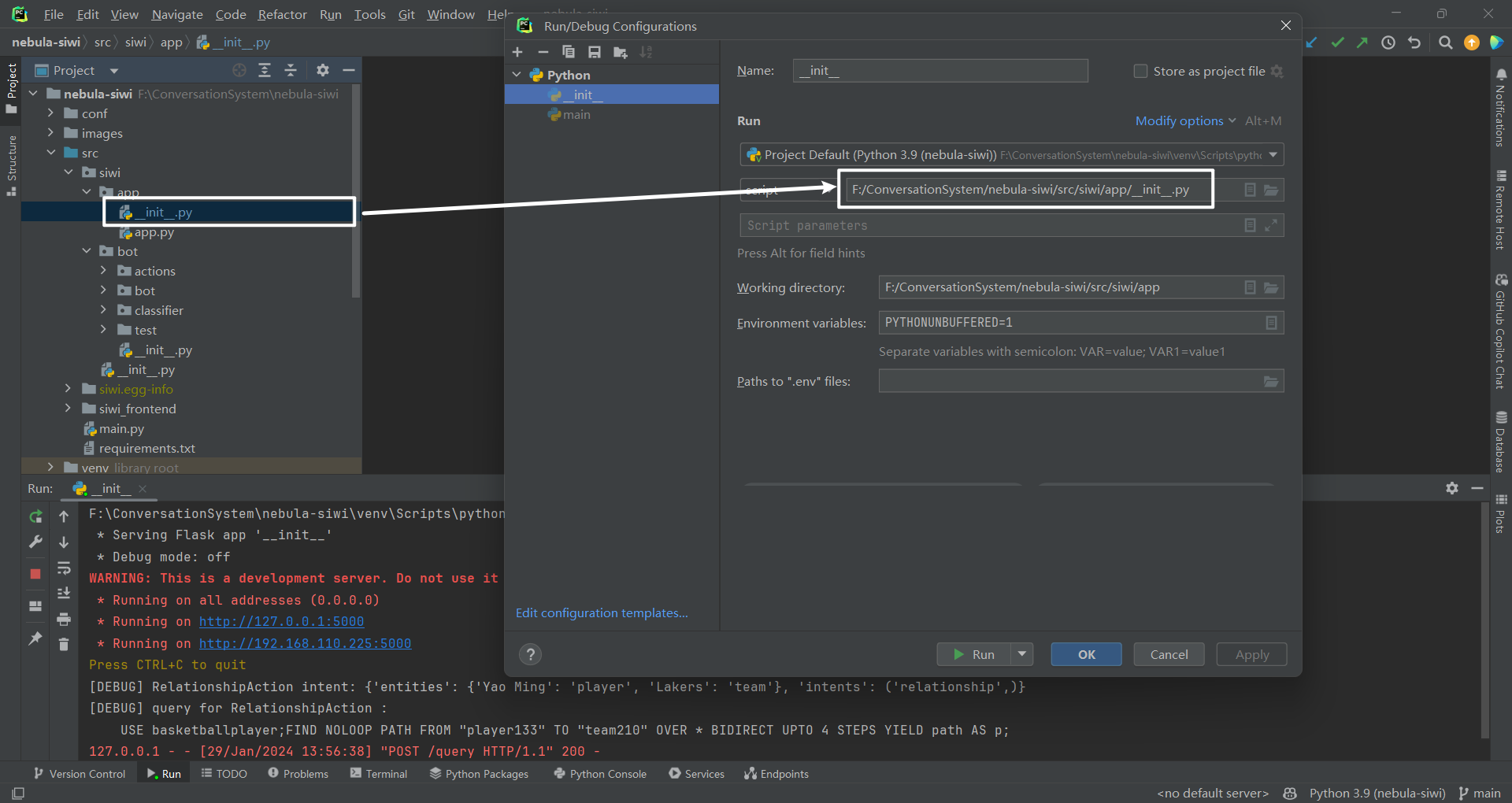
2.后端实现思路[2] PyCharm 打开 Flask 项目,直接运行
python F:/ConversationSystem/nebula-siwi/src/siwi/app/__init__.py
三.后端代码具体实现 1.整体思路 整体流程应该从
F:\ConversationSystem\nebula-siwi\src\siwi\app\__init__.py
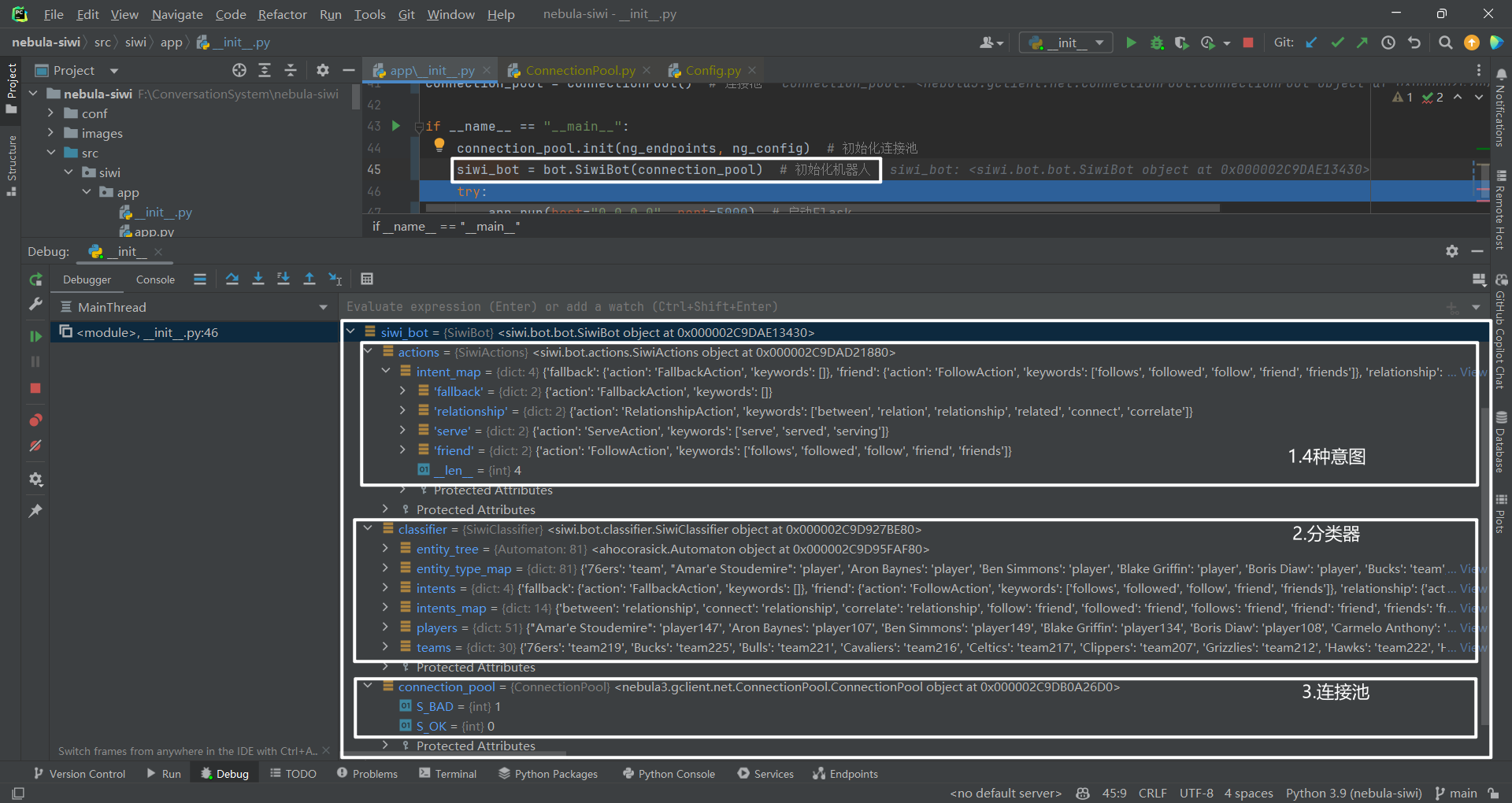
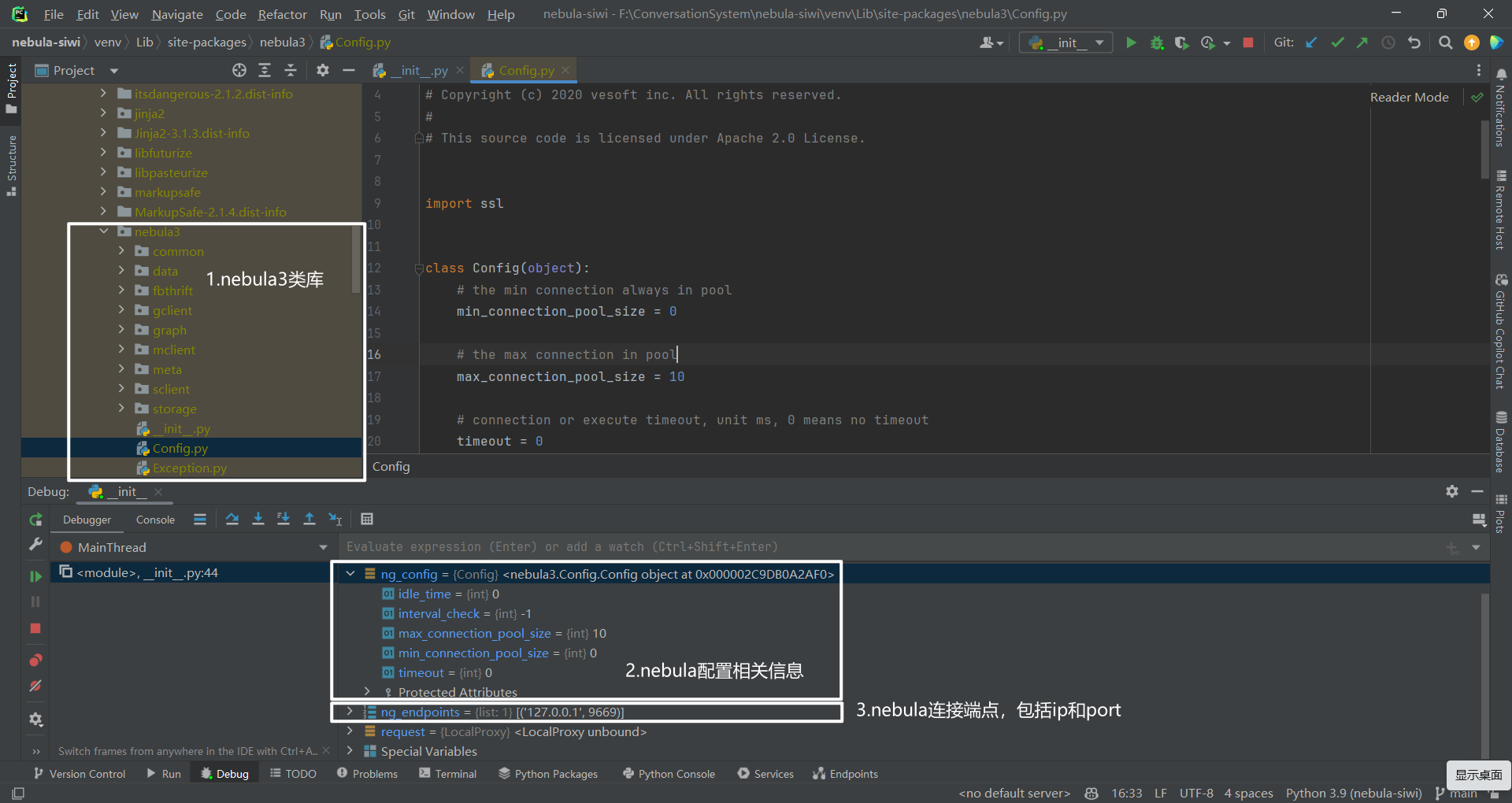
其中,初始化连接池使用的 Python 类库为 nebula3,目录结构如下所示:
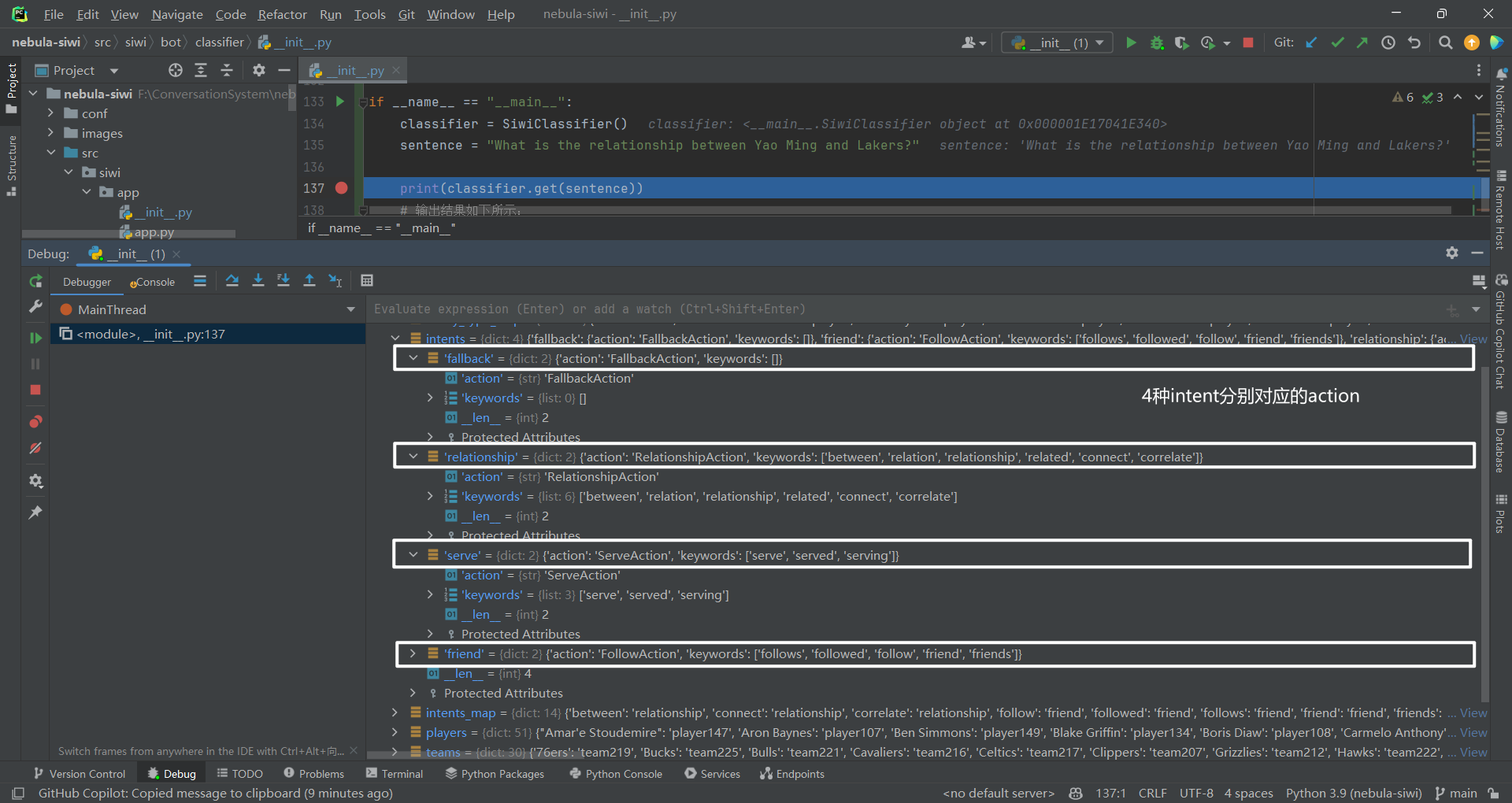
初始化机器人又包括初始化分类器(classifier)和动作(action)2 个部分。
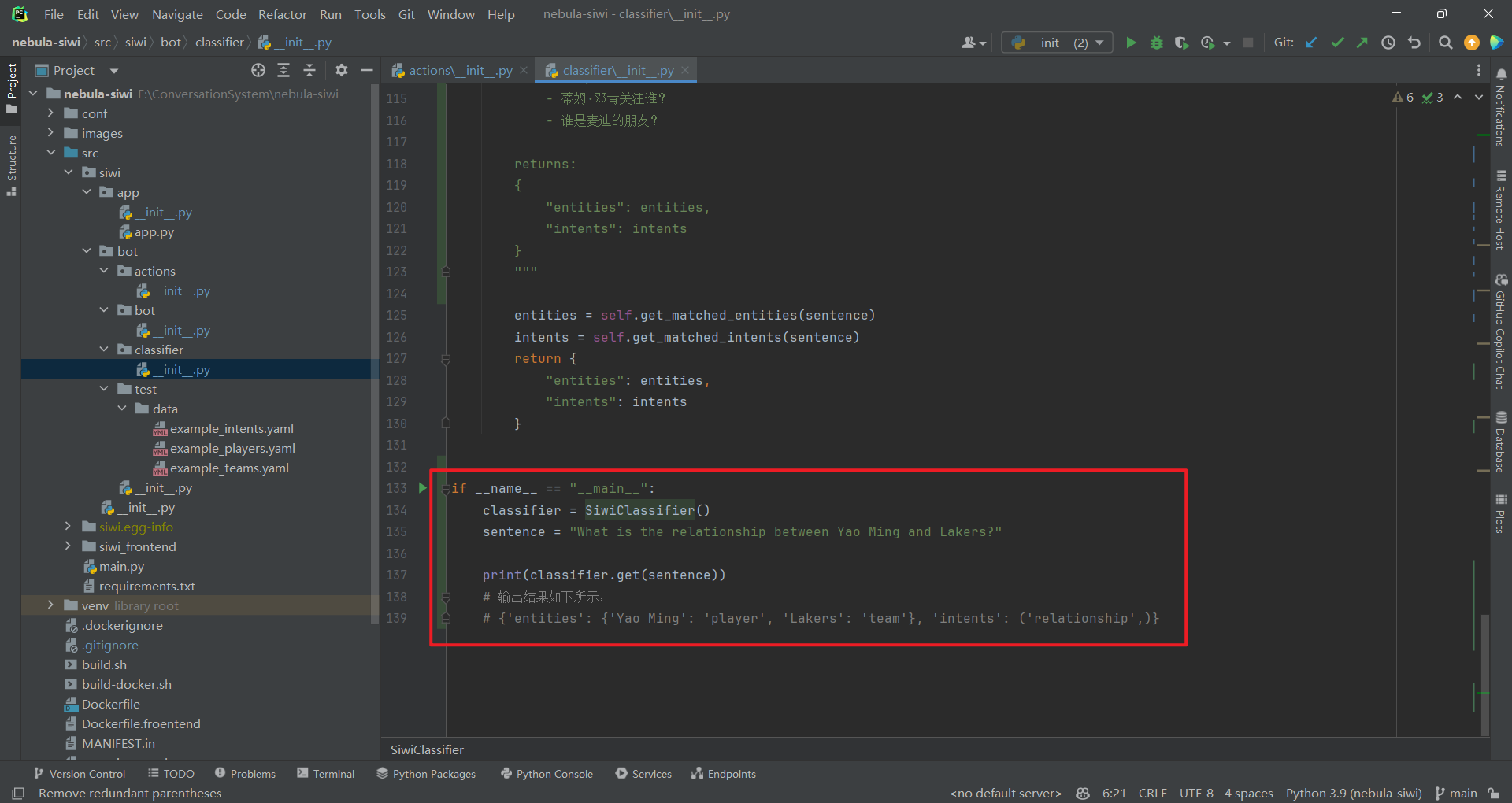
2.分类器(classifier)实现思路 2.1 增加 main()函数 加了一个 main()函数来测试分类器类,如下所示:
2.2 根据 sentence 识别 intent 分类器实现比较简单,主要是根据 sentence 识别 intent,实现代码如下所示:
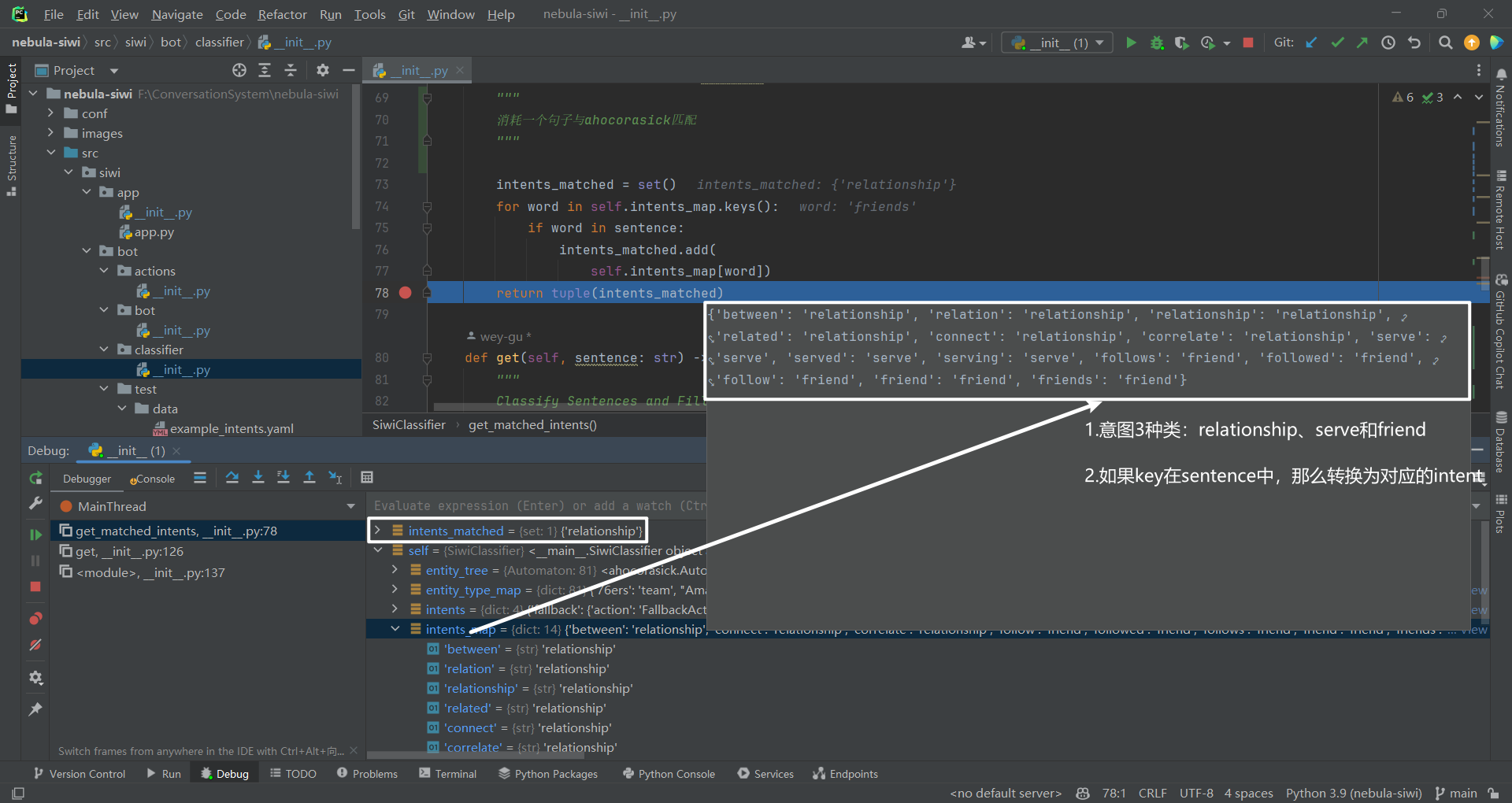
def get_matched_intents(self, sentence: str) -> tuple:"" " "" set ()for word in self.intents_map.keys():if word in sentence:
2.3 根据 sentence 返回 entity 除此之外,还有根据 sentence 返回 entity。如下所示:
def get_matched_entities(self, sentence: str) -> dict:"" " "" for item in self.entity_tree.iter(sentence):return {for entity in entities_matched
self.entity_tree.iter(sentence)
ahocorasick.Automaton()
self.entity_tree
sentence
iter()
sentence
sentence
add_word()
例如,如果在自动机中添加了单词 "apple",并将其值设置为
(0, "apple")
iter()
(13, (0, "apple"))
(0, "apple")
因此,
self.entity_tree.iter(sentence)
entities_matched
2.4 自动机实现过程 (1)self.entity_tree 自动机对象
重点详细介绍下 self.entity_tree 是实现过程,如下所示:
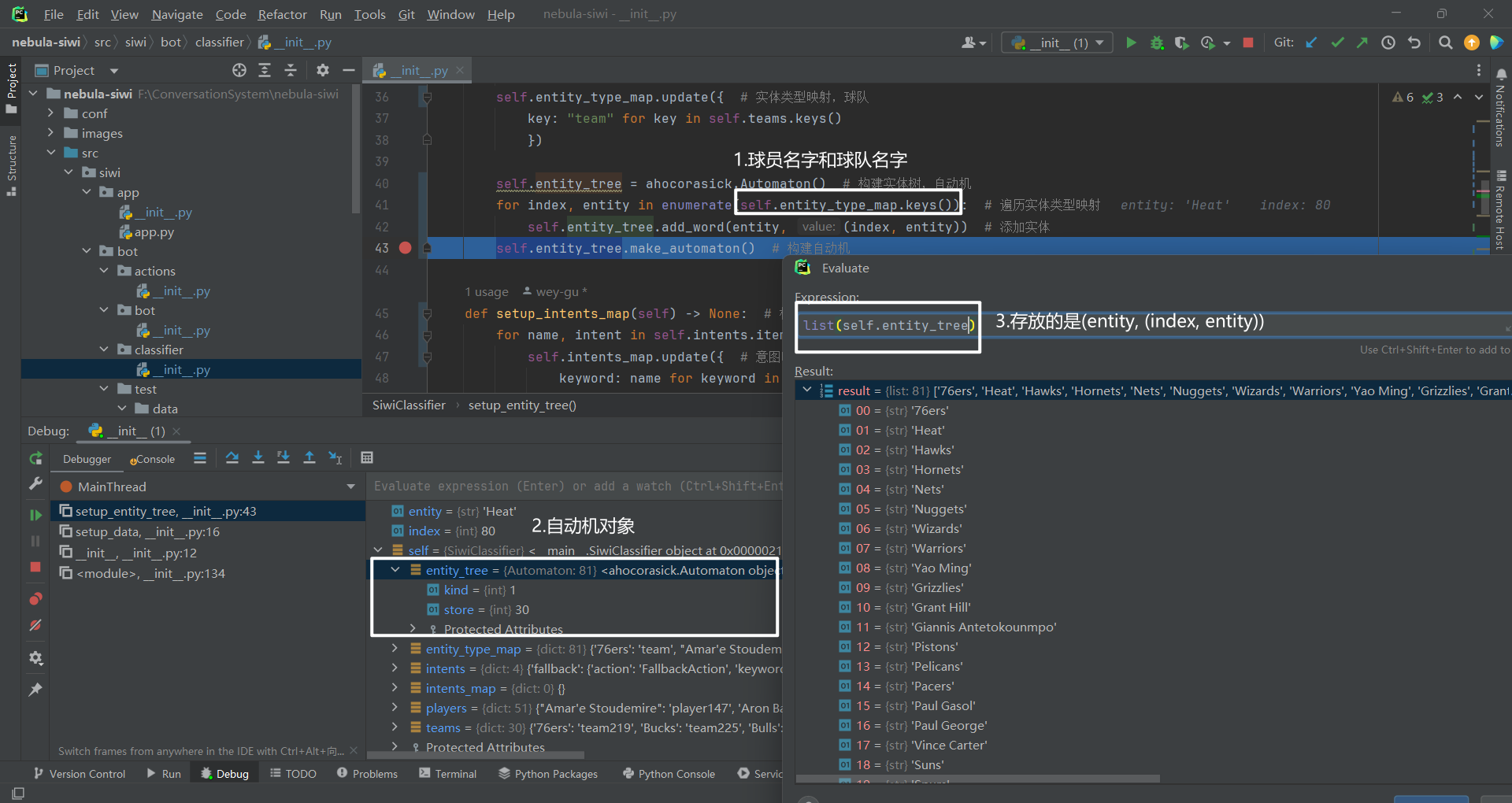
self.entity_tree = ahocorasick.Automaton() for index, entity in enumerate(self.entity_type_map.keys()):
(2) ahocorasick.Automaton() 自动机介绍
ahocorasick.Automaton()
pyahocorasick
在这段代码中,
self.entity_tree = ahocorasick.Automaton()
self.entity_tree
Aho-Corasick 自动机的工作原理是,首先构建一个有向图(通常称为 "trie" 或 "前缀树"),其中每个节点代表一个模式串的前缀。然后,对于输入文本中的每个字符,自动机都会沿着图的边移动,匹配尽可能长的模式串。
这种方法的优点是,无论模式串的数量或长度如何,匹配过程的时间复杂度都是线性的,即与输入文本的长度成正比。这使得 Aho-Corasick 算法非常适合于处理大量模式串和大量输入文本的情况。
(3) add_word() 方法介绍
add_word()
ahocorasick.Automaton()
在
add_word()
word
value
word
value
add_word()
for index, entity in enumerate(self.entity_type_map.keys()): 在这段代码中,
entity
(index, entity)
(4) make_automaton() 方法介绍
make_automaton()
ahocorasick.Automaton()
make_automaton()
在本文的代码中,
make_automaton()
self.entity_tree.make_automaton() 这段代码将构建一个完整的 Aho-Corasick 自动机,该自动机可以用于在输入文本中高效地查找实体。
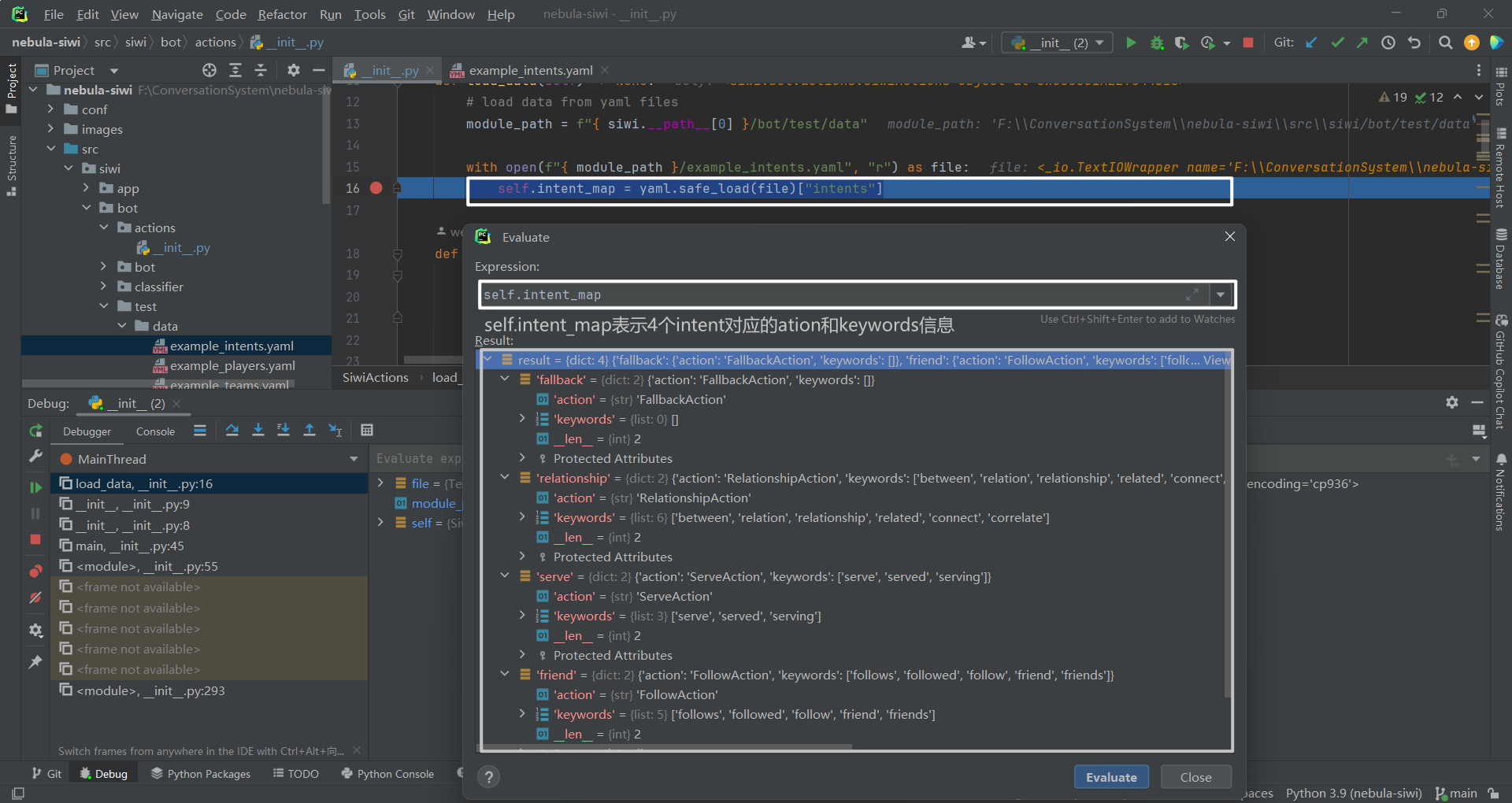
2.5 意图(intent)到动作(action)映射
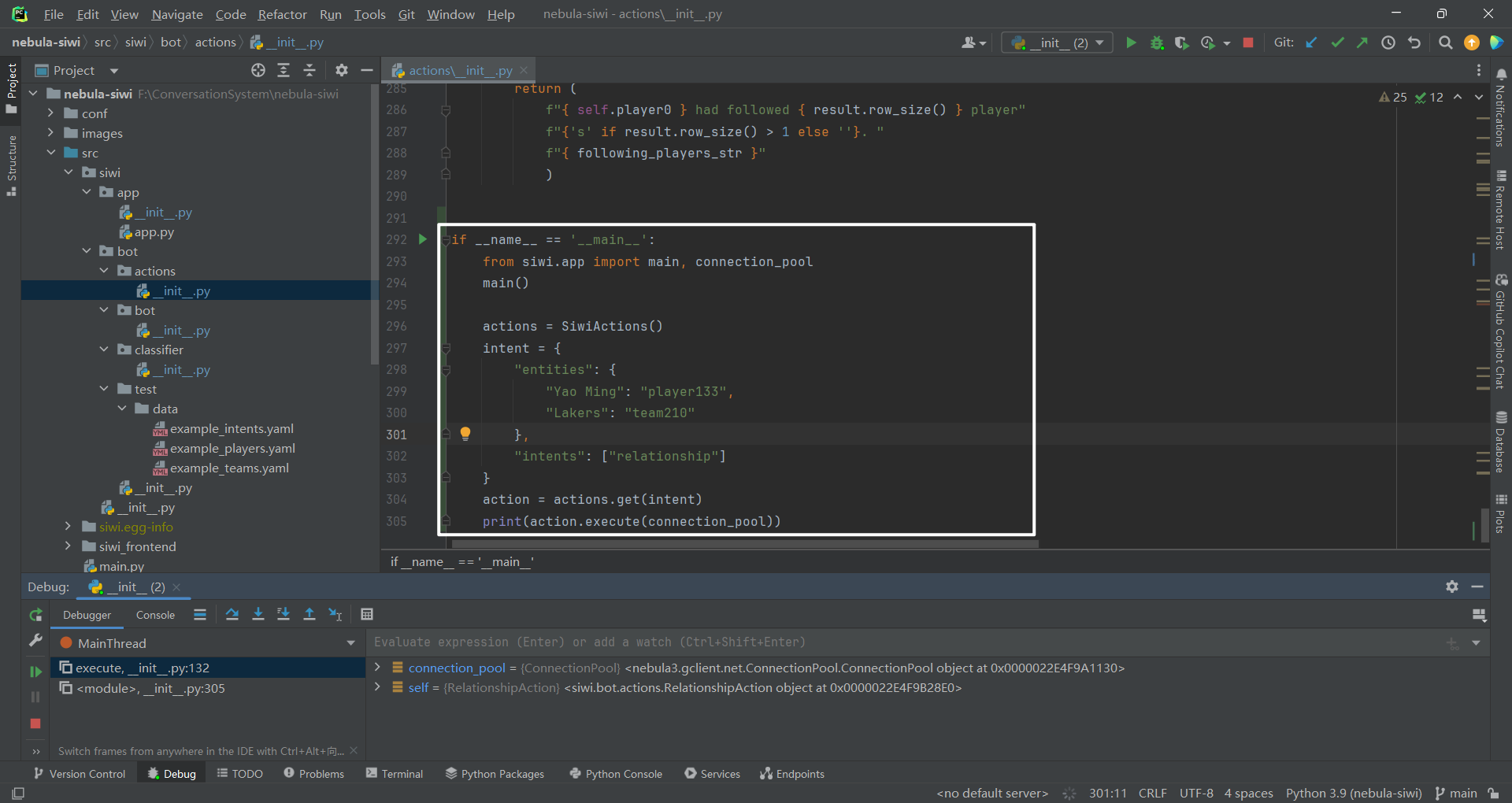
3.动作(action)实现思路 3.1 增加 main()函数 加了一个 main()函数来测试各种动作类,如下所示:
然后就是根据意图(intent)+ 实体(entity)得到动作(action)的类型,包括
FallbackAction(SiwiActionBase)、RelationshipAction(SiwiActionBase)、ServeAction(SiwiActionBase)和FollowAction(SiwiActionBase)
其中,
self.intent_map
3.2
FallbackAction(SiwiActionBase)
class FallbackAction(SiwiActionBase):"" " "" return "" " "" 这个是 fallback 对应的动作 FallbackAction,就是当 intent 不在 relation、serving 和 friendship 中时,要提示用户应该怎么提问。
3.3
RelationshipAction(SiwiActionBase)
以"Yao Ming 和 Rockets 的关系是什么?"为例进行介绍,核心代码如下所示:
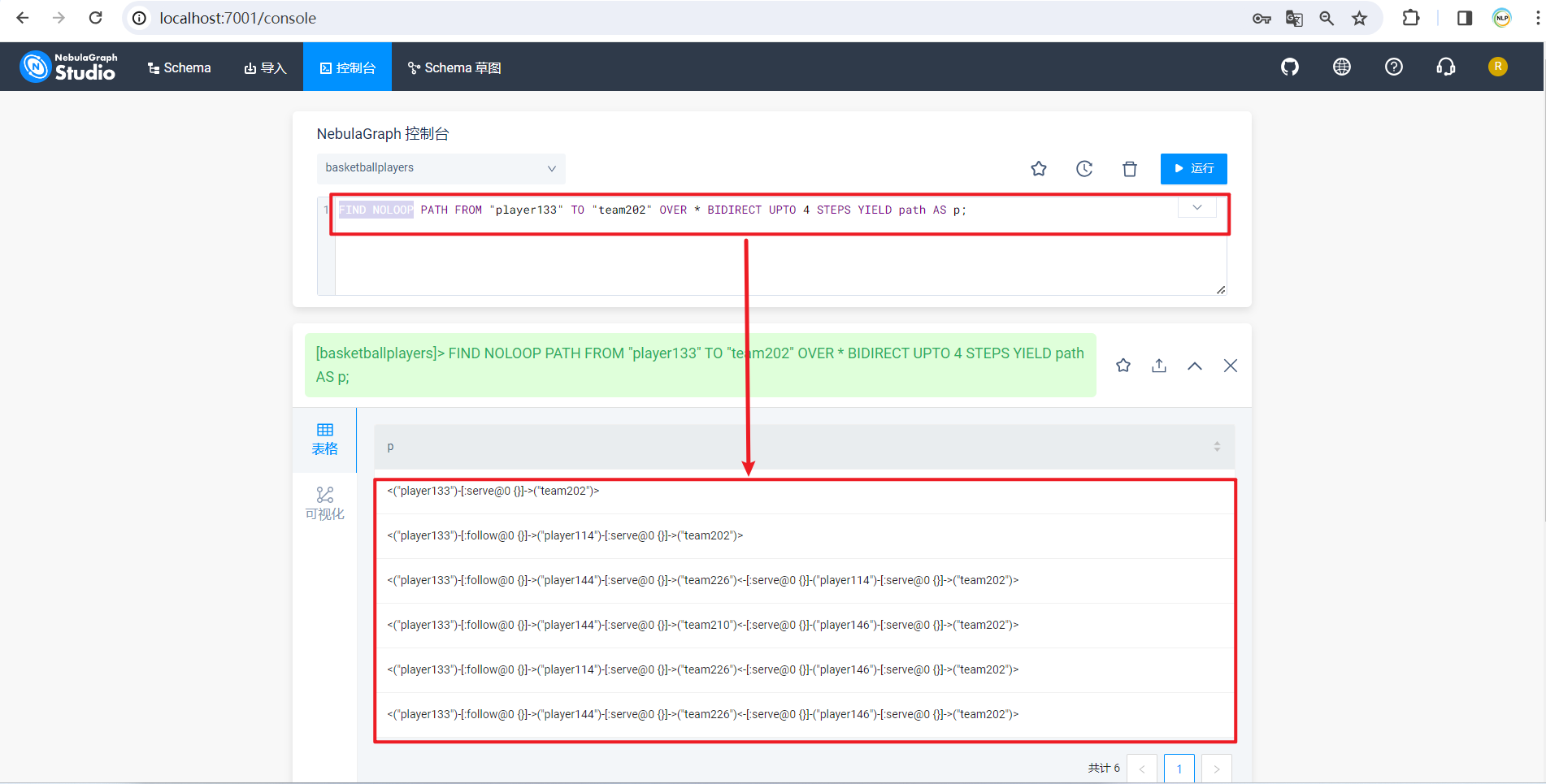
query = ( 'USE basketballplayer;' 'FIND NOLOOP PATH ' 'FROM "{self.left_vid}" TO "{self.right_vid}" ' 'OVER * BIDIRECT UPTO 4 STEPS YIELD path AS p;' "player133" TO "team202" OVER * BIDIRECT UPTO 4 STEPS YIELD path AS p;在图中查找从球员"player133"到球队"team202"的最长 4 步内无循环路径,并将路径存储在变量"path"中,以别名"p"返回。详细命令解释如下所示:
命令
解释
FIND NOLOOP PATH
这部分指定了查询的类型,即查找无循环路径的图查询。
FROM "player133" TO "team202"
指定了查询的起始点和终点,即从"player133"(球员编号为 133)出发,找到通往"team202"(球队编号为 202)的路径。
OVER *
这部分表示沿着所有类型的边进行遍历。通常,"*"用于表示所有边的类型(follow 和 serve)。
BIDIRECT
表示查询是双向的,即可以沿着边的两个方向进行遍历。
UPTO 4 STEPS
限定了路径的最大步数为 4 步,即查找包括最多 4 个边的路径。
YIELD path AS p
这部分定义了查询结果的输出格式,将路径存储在一个名为"path"的变量中,并使用别名"p"返回。
输出结果如下所示:
[DEBUG] RelationshipAction intent: {'entities': {'Yao Ming': 'player133', 'Rockets': 'team202'}, 'intents': ['relationship']}USE basketballplayers;FIND NOLOOP PATH FROM "player133" TO "team202" OVER * BIDIRECT UPTO 4 STEPS YIELD path AS p;使用 NebulaGraph Studio 查询结果,如下所示:
3.4
ServeAction(SiwiActionBase)
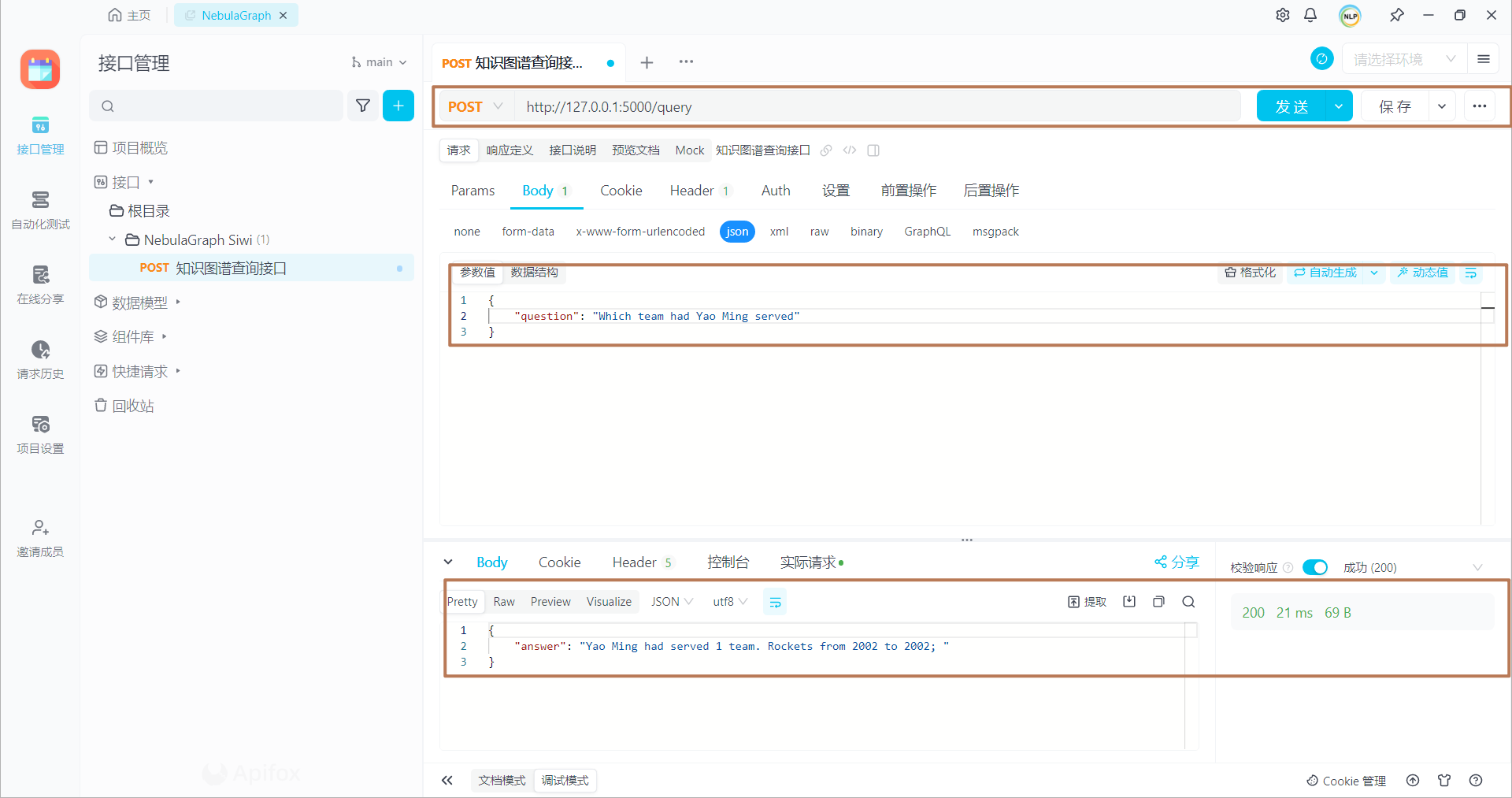
以"姚明曾经效力过哪些球队?"为例进行介绍,核心代码如下所示:
query = (USE basketballplayers;'USE basketballplayers;这个 Nebula Graph 查询的目的是查找从指定球员节点(ID 为"player133")出发,通过"serve"边到达其他节点的路径,并返回这些路径。查询结果将包含路径信息,其中路径由节点 v、边 e 和节点 v1 组成。这个查询最多返回 100 条符合条件的路径。详细命令解释,如下所示:
命令
解释
MATCH p=(v)-[e:serve*1]->(v1)
这部分指定了查询的模式。它创建了一个模式 p,其中包含了一个从节点 v 出发、经过边 e(带有 serve 标签,*1 表示 1 跳,即一步)到达节点 v1 的路径。这表示查询从一个球员节点(v)通过"serve"边到达另一个节点(v1)的路径。
WHERE id(v) == "player133"
这部分是一个过滤条件,限定了节点 v 的 ID 必须等于"player133"。这用于筛选起始节点是"player133"的路径。
RETURN p
这部分指定了要返回的结果。在这里,返回整个路径 p。
LIMIT 100
这是一个可选的限制条件,用于限制返回的结果数量,防止返回太多结果。
接口调用如下所示:
3.5
FollowAction(SiwiActionBase)
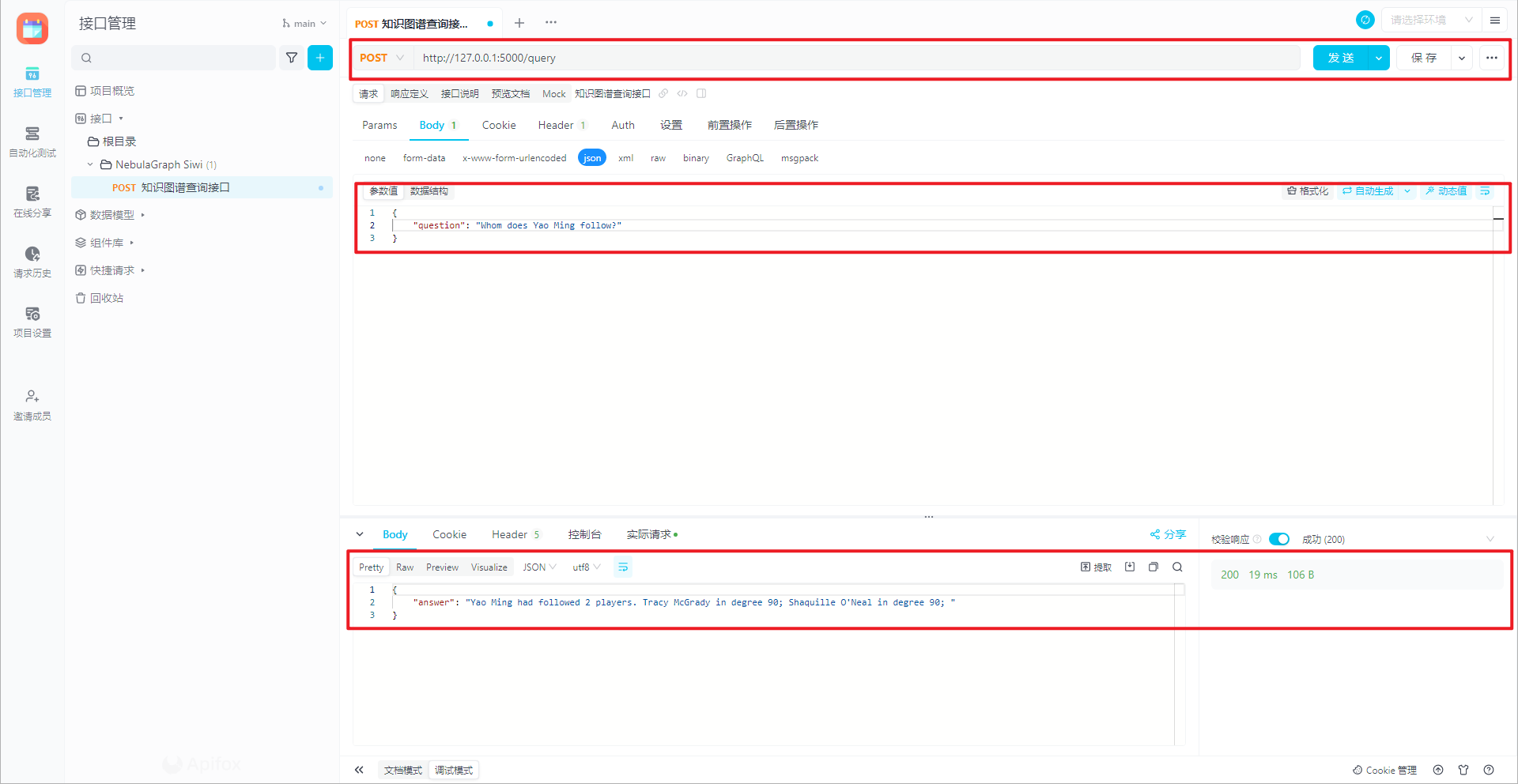
以"姚明的朋友有哪些?或姚明关注了哪些人?"为例进行介绍,核心代码如下所示:
query = (USE basketballplayers;'USE basketballplayers;这个 Nebula Graph 查询的目的是查找从指定球员节点(ID 为"player133")出发,通过"follow"边到达其它节点的路径,并返回这些路径。查询结果将包含路径信息,其中路径由节点 v、边 e 和节点 v1 组成。这个查询最多返回 100 条符合条件的路径。详细命令解释,如下所示:
命令
解释
MATCH p=(v)-[e:follow*1]->(v1)
这部分指定了查询的模式。它创建了一个模式 p,其中包含了一个从节点 v 出发、经过边 e(带有 follow 标签,*1 表示 1 跳,即一步)到达节点 v1 的路径。这表示查询从一个球员节点(v)通过"follow"边到达另一个节点(v1)的路径。
WHERE id(v) == "player133"
这部分是一个过滤条件,限定了节点 v 的 ID 必须等于"player133"。这用于筛选起始节点是"player133"的路径。
RETURN p
这部分指定了要返回的结果。在这里,返回整个路径 p。
LIMIT 100
这是一个可选的限制条件,用于限制返回的结果数量,防止返回太多结果。
接口调用如下所示:
参考文献 [1] Nebula Siwi 基于图数据库的智能问答助手:https://siwei.io/nebula-siwi/
[2] Nebula Siwi GitHub:https://github.com/wey-gu/nebula-siwi/
[3] 示例数据 Basketballplayer:https://docs.nebula-graph.com.cn/2.6.2/3.ngql-guide/1.nGQL-overview/1.overview/#basketballplayer
[4] Siwi Frontend:https://github.com/wey-gu/nebula-siwi/tree/main/src/siwi_frontend
[5] pyahocorasick:https://pyahocorasick.readthedocs.io/en/latest/#aho-corasick-methods
[6] NLP 模式高效匹配技术总结:https://hub.baai.ac.cn/view/22048
[7] NebulaGraph 手工和 Python 操作:https://z0yrmerhgi8.feishu.cn/wiki/YnYDwyU05iT0SAkZNtocArffniM
[8] 什么是 nGQL:https://docs.nebula-graph.com.cn/3.6.0/3.ngql-guide/1.nGQL-overview/1.overview/
[9] Nebula Siwi:基于图数据库的智能问答助手思路分析(源码链接):
https://github.com/ai408/nlp-engineering/tree/main/``知识工程-知识图谱/NebulaGraph实战/19-Nebula Siwi:基于图数据库的智能问答助手思路分析
NLP工程化 1.本公众号以对话系统为中心,专注于Python/C++/CUDA、ML/DL/RL和NLP/KG/DS/LLM领域的技术分享。
NLP工程化(公众号)
NLP工程化(星球号)