RAPTOR 一种基于树的RAG方法,RAG的准确率提高 20%
一种理解整个文档上下文的新颖的 RAG 方法
RAG 是当前使用LLM的标准方法,大多数现有方法仅从检索语料库中检索短的连续块,限制了对整个文档上下文的整体理解。
最近,一种名为 RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval)方法提出来,该方法核心思想是将doc构建为一棵树,然后逐层递归的查询,如下图所示: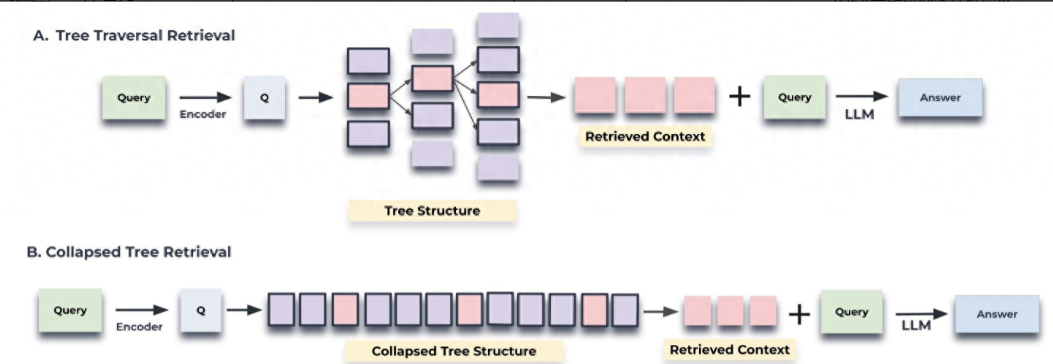
在推理时,RAPTOR 模型从该树中检索,在不同抽象级别的文档中找出匹配片段。
在涉及复杂、多步骤推理的问答任务中,通过将 RAPTOR 检索与 GPT-4 结合使用,可以将 QuALITY 基准的准确率提高 20%。
树的构建过程
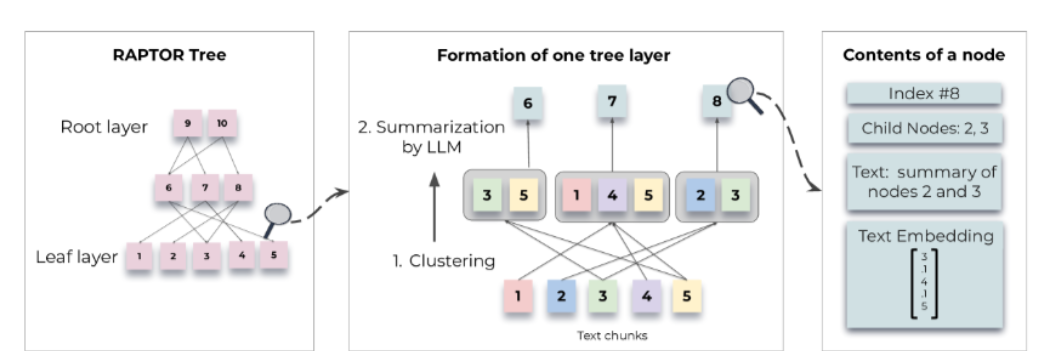
构建树的过程,RAPTOR 根据其语义embedding递归地对文本块chunk进行聚类,并生成这些聚类的文本摘要。
RAPTOR 根据向量递归地对文本块进行聚类,并生成这些聚类的文本摘要,从而自下而上构建一棵树。 聚集在一起的节点是兄弟节点; 父节点包含该集群的文本摘要。这种结构使 RAPTOR 能够将代表不同级别文本的上下文块加载到 LLM 的上下文中,以便它能够有效且高效地回答不同层面的问题。
树的聚类算法基于高斯混合模型 (GMM),聚类后,每个聚类中的节点被发送到LLM进行概括。在实验中,作者使用 gpt-3.5-turbo 来生成摘要。摘要步骤将可能大量的检索信息压缩(summarization)到一个可控的大小。
查询过程
查询有两种方法,基于树遍历(tree traversal)和折叠树(collapsed tree)
遍历是从 RAPTOR 树的根层开始,然后逐层查询
折叠树就是全部平铺,用ANN库查询。
查询方法的比较
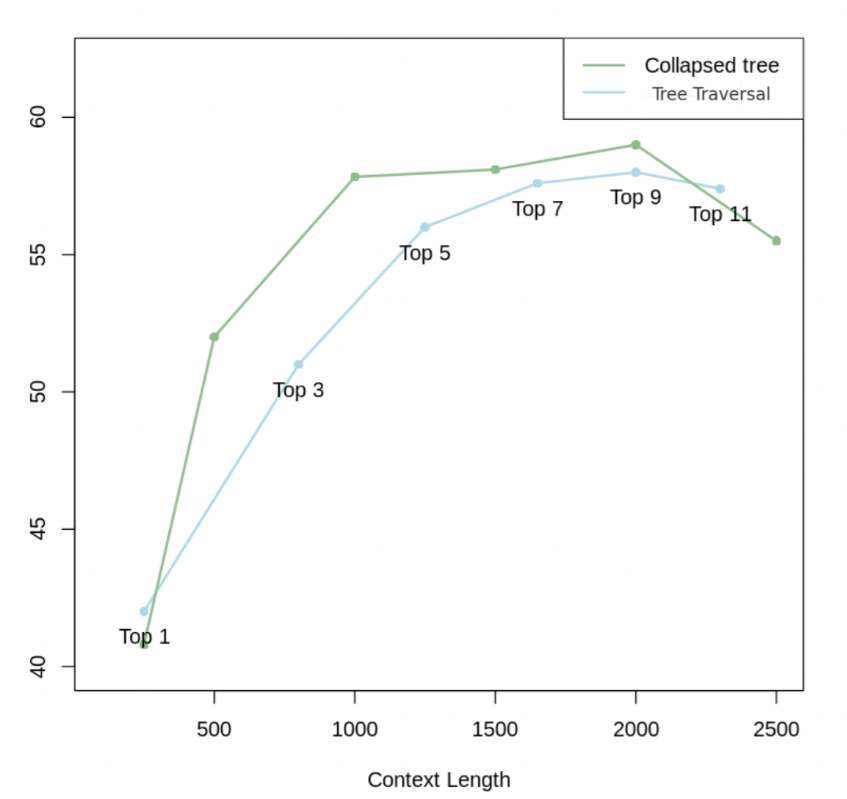
折叠树方法具有更大的灵活性,F1会更高。