老实说,分支预测,是高手过招的杀手锏,但是对写业务代码没啥帮助。
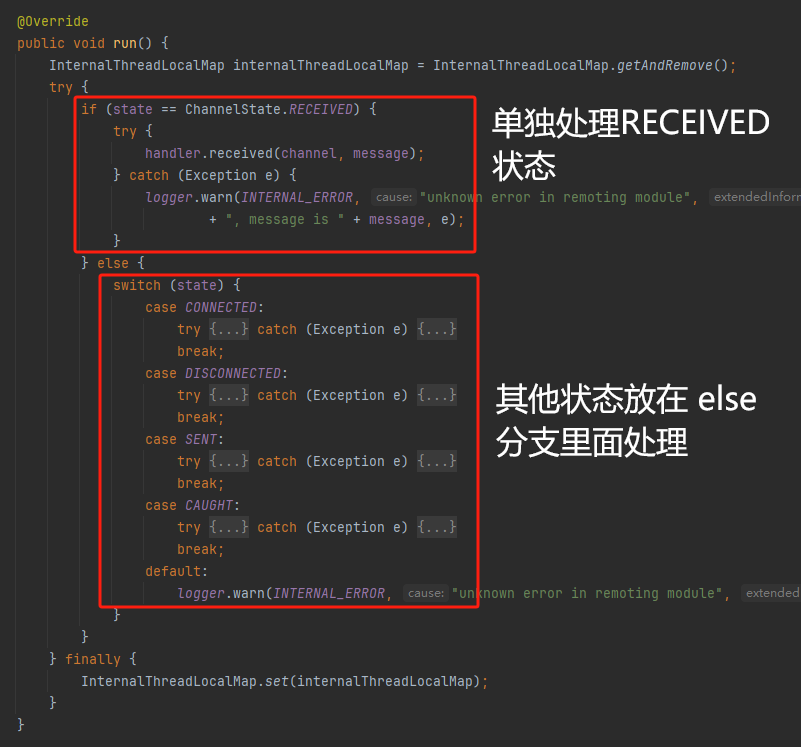
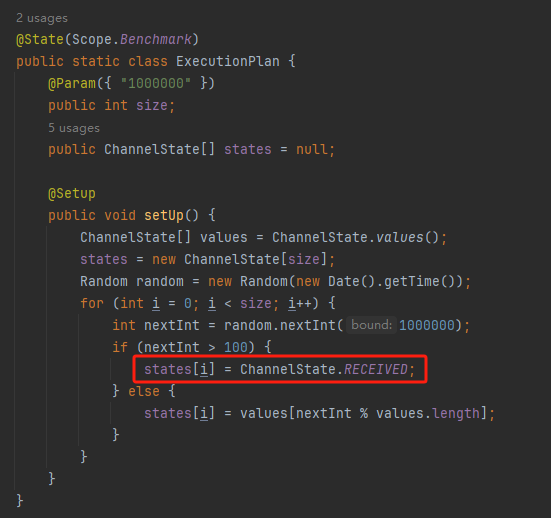
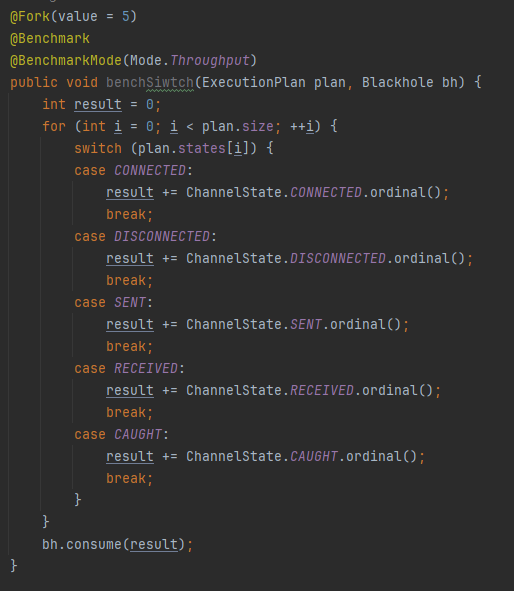
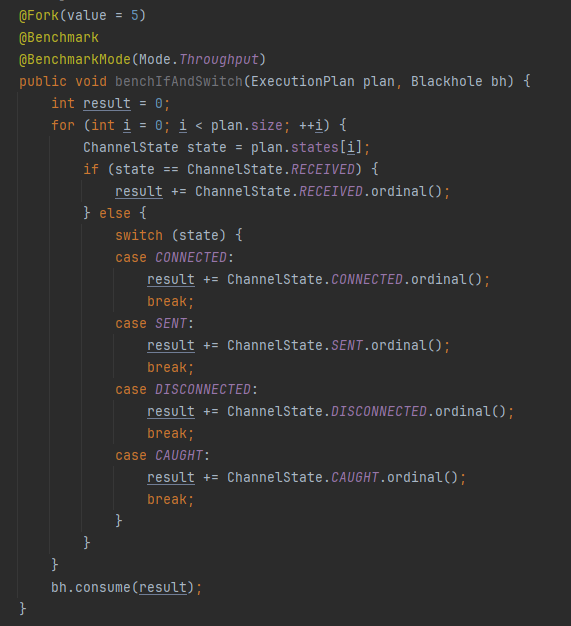
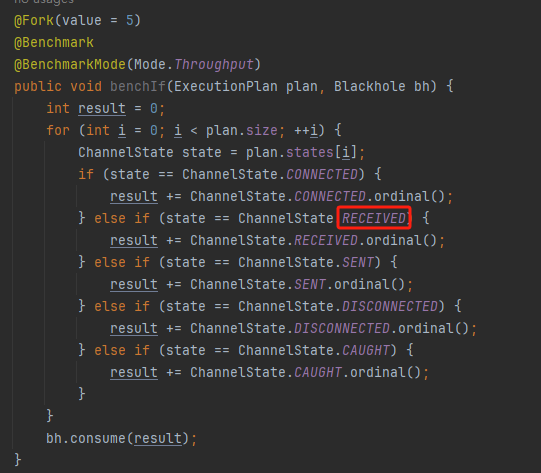
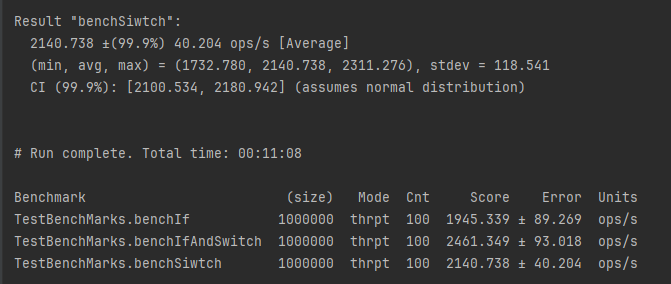
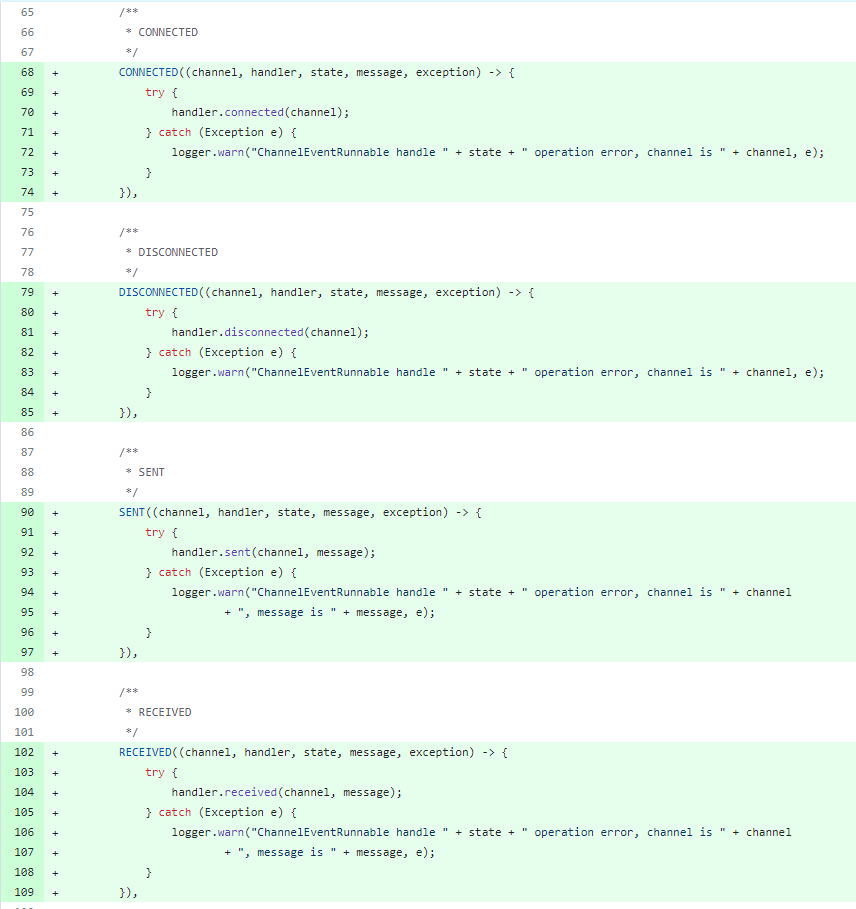
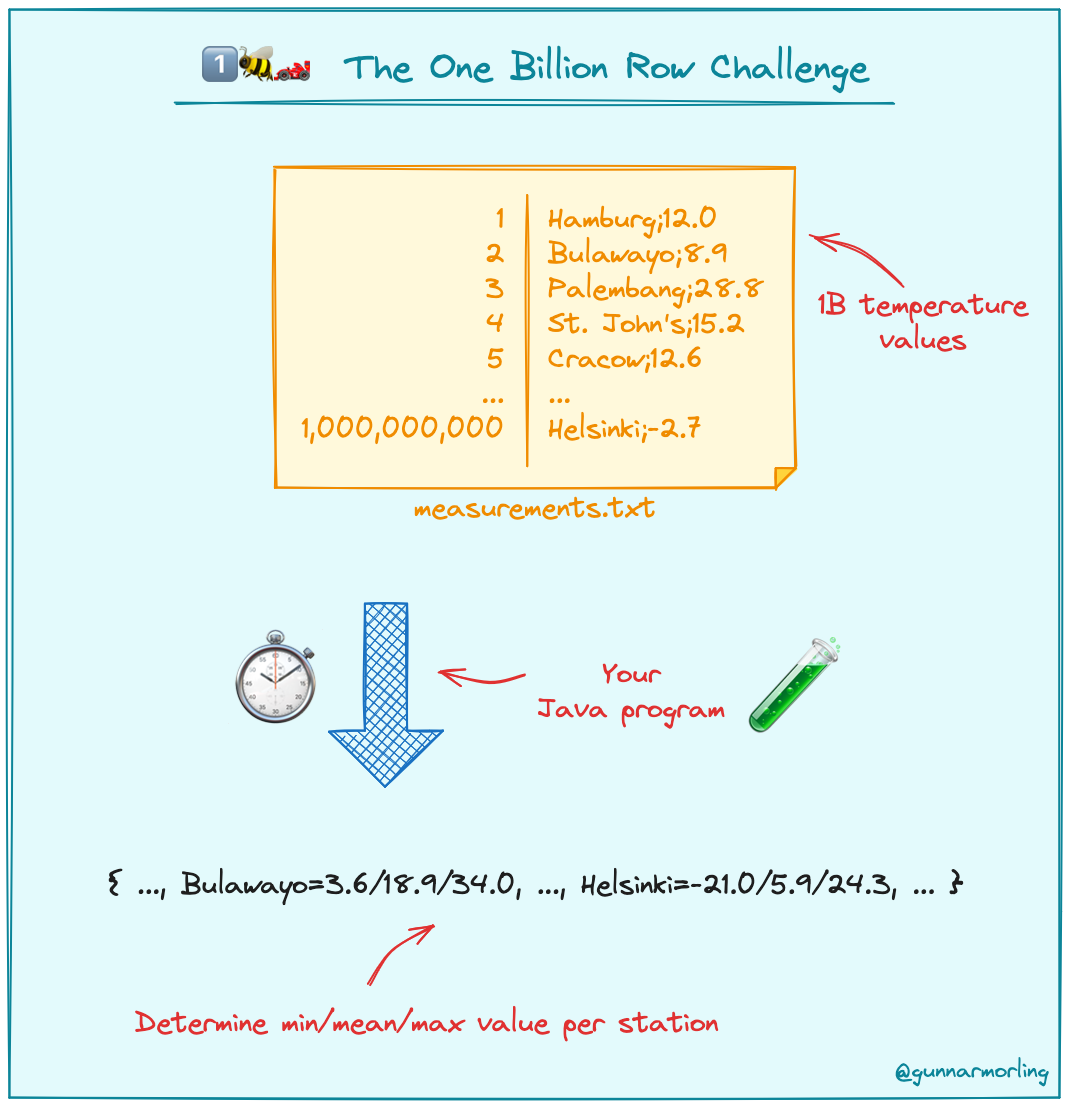
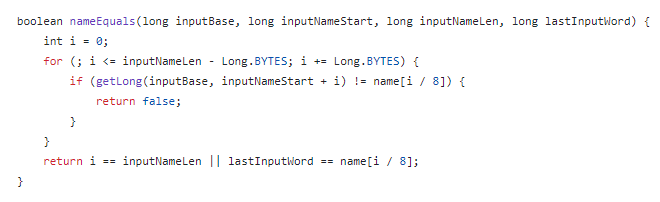
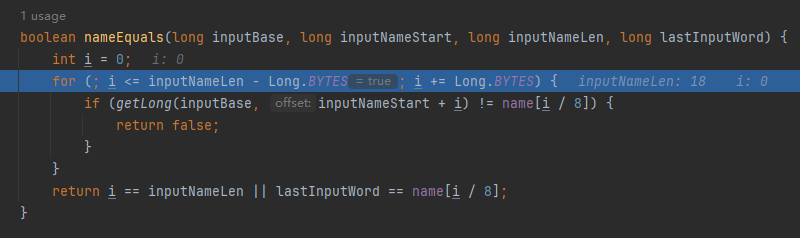
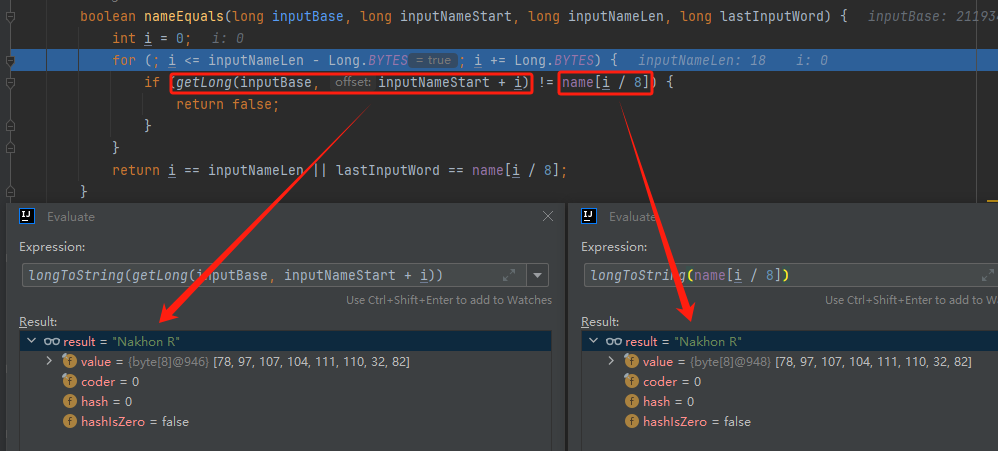
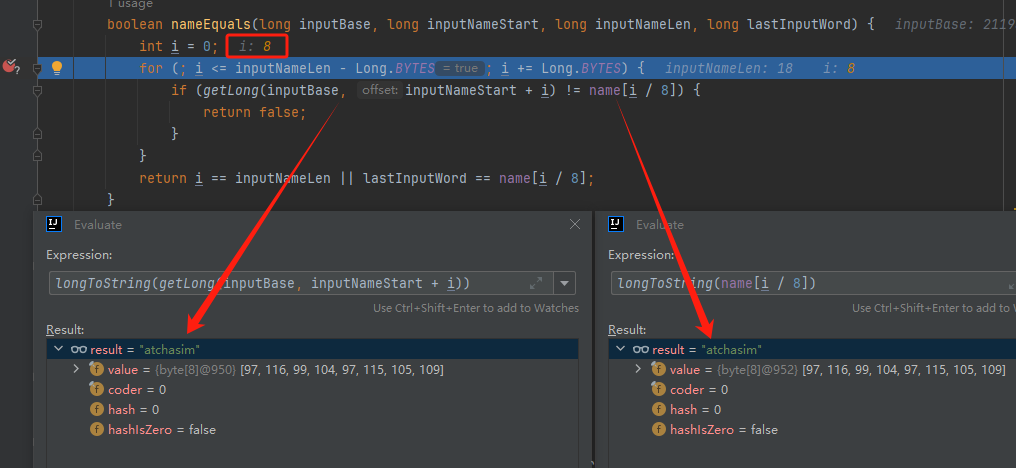
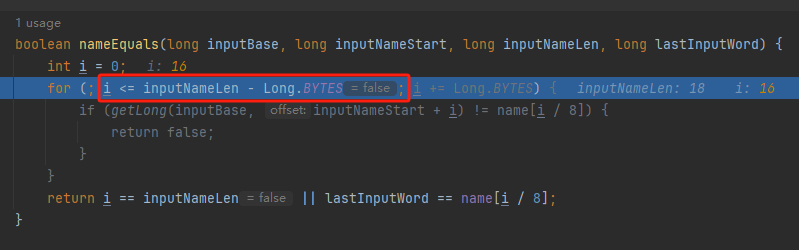
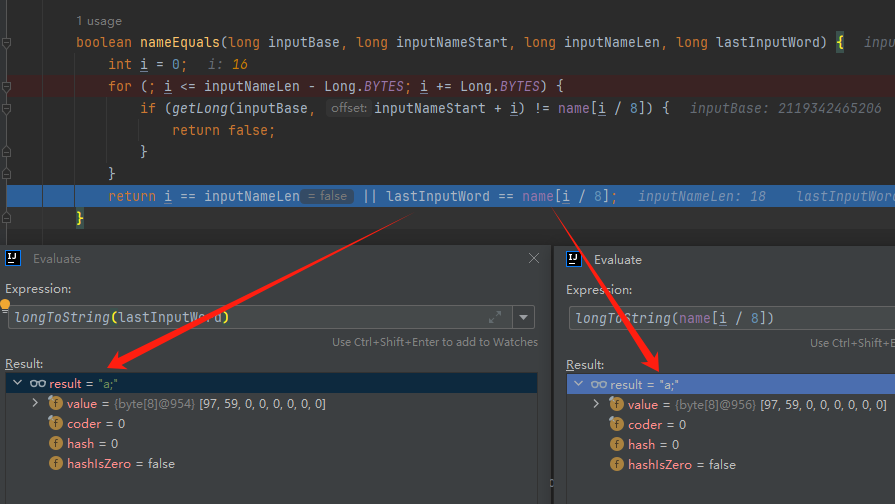
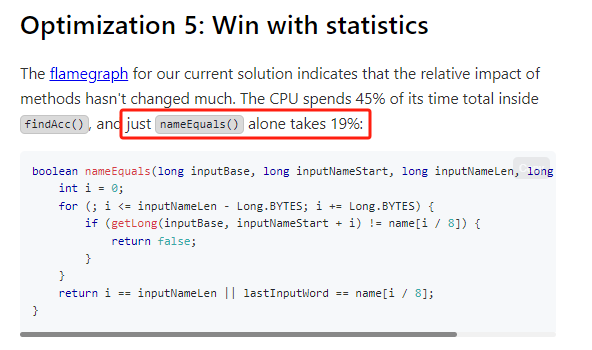
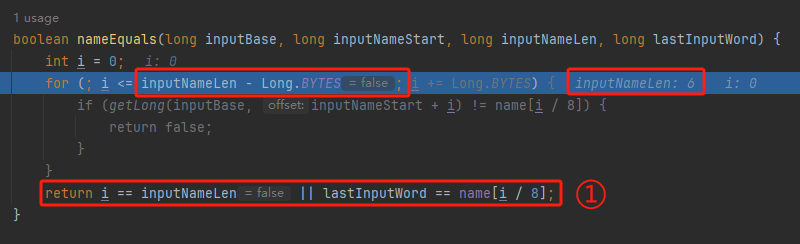
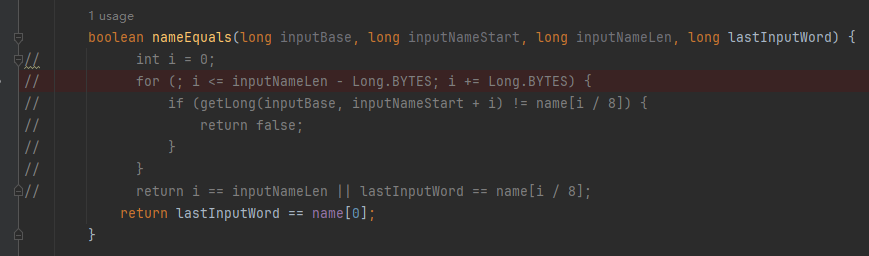
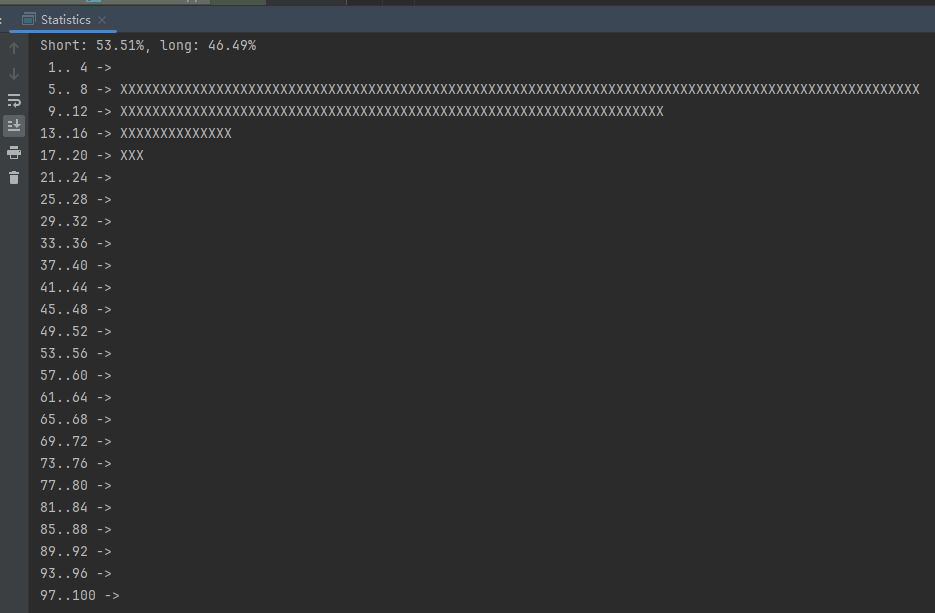
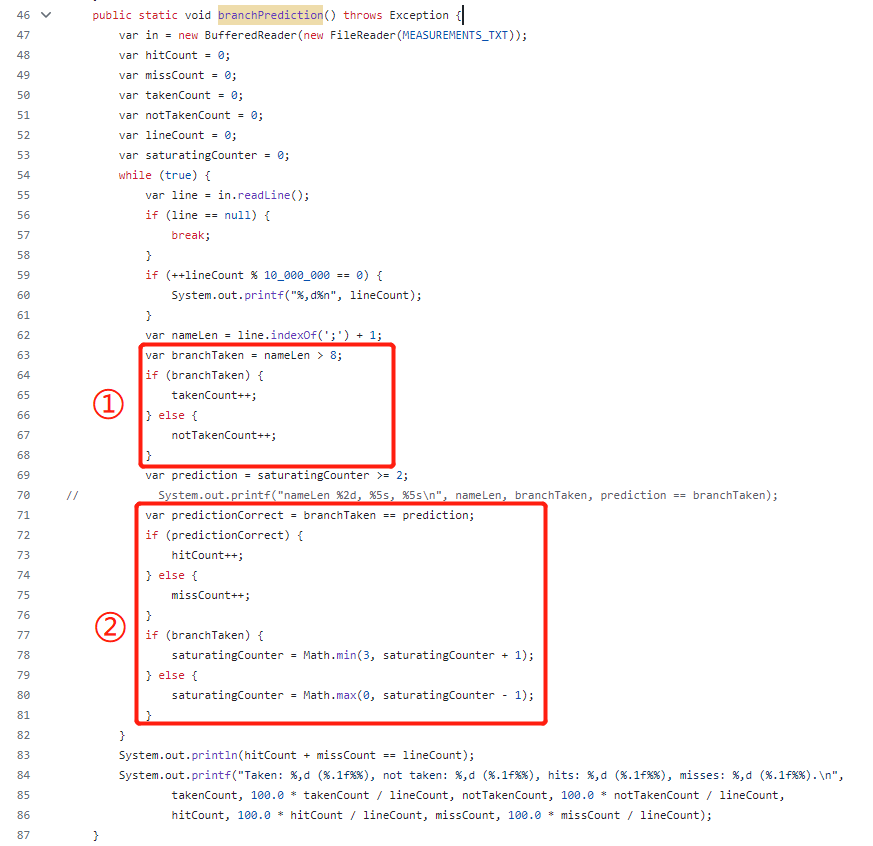
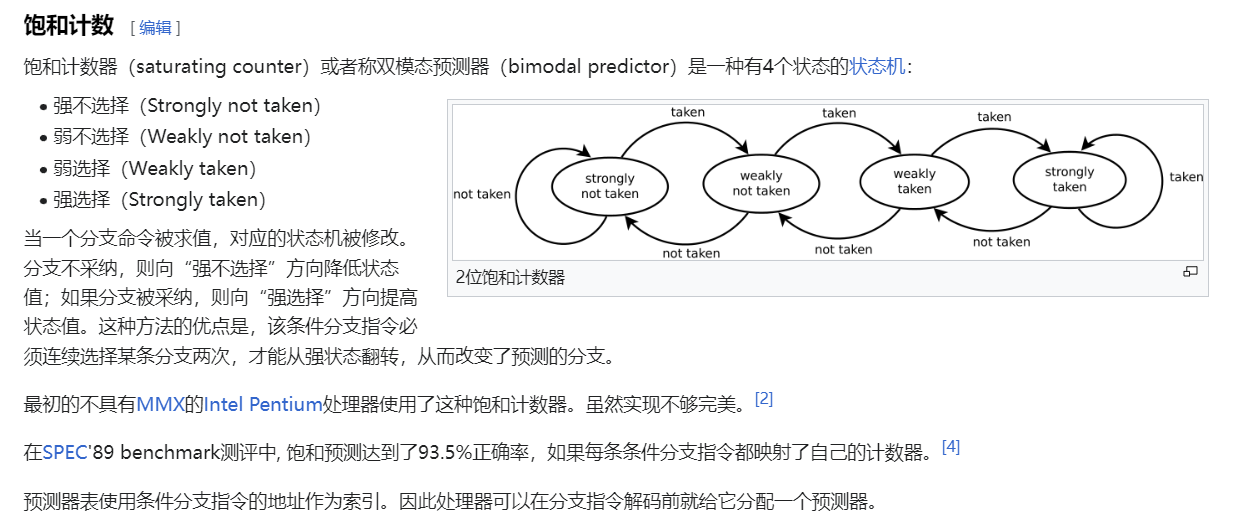
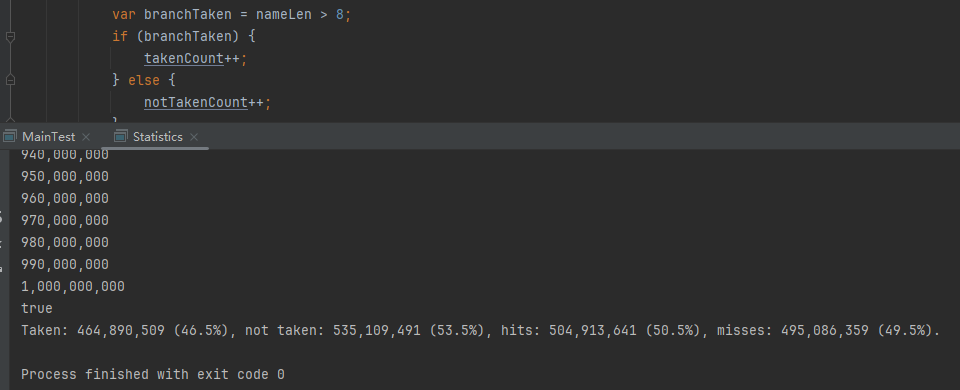
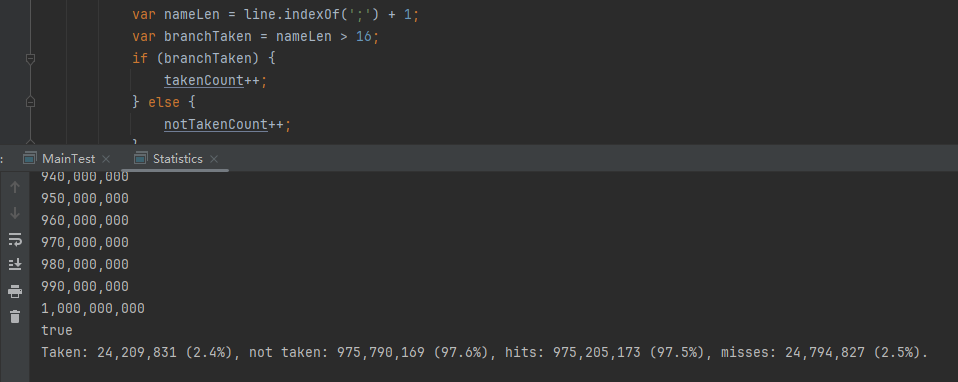
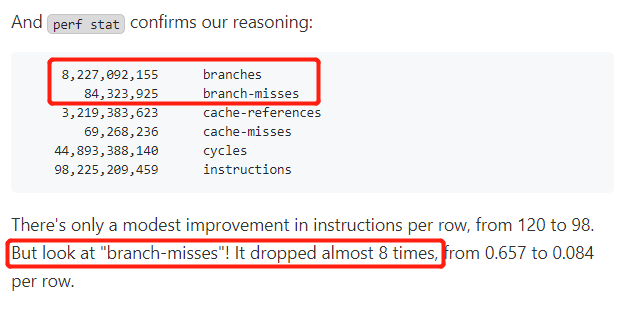
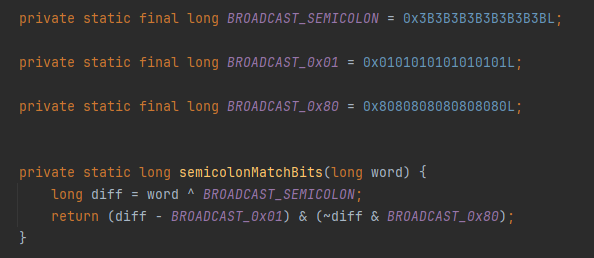
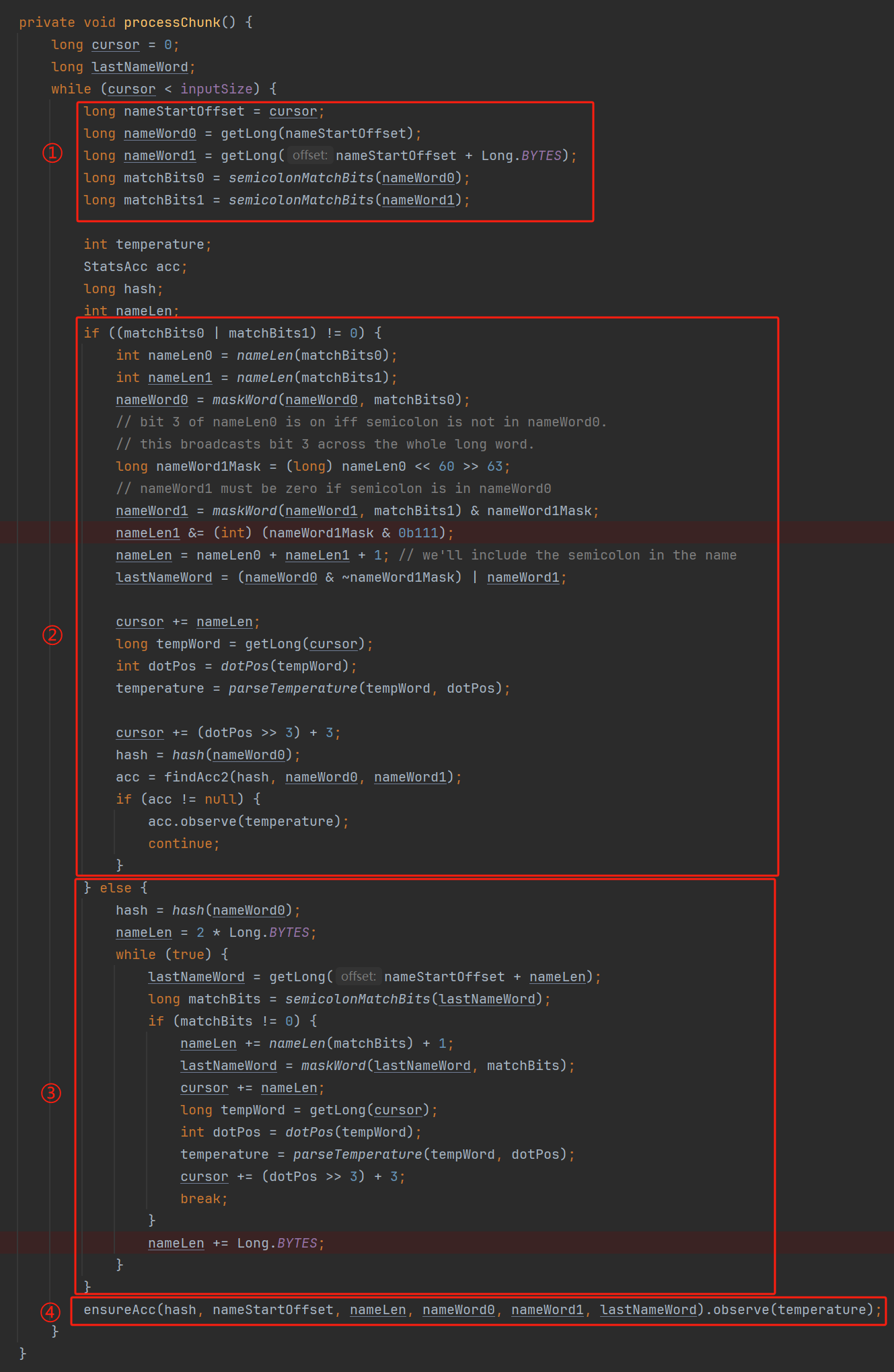
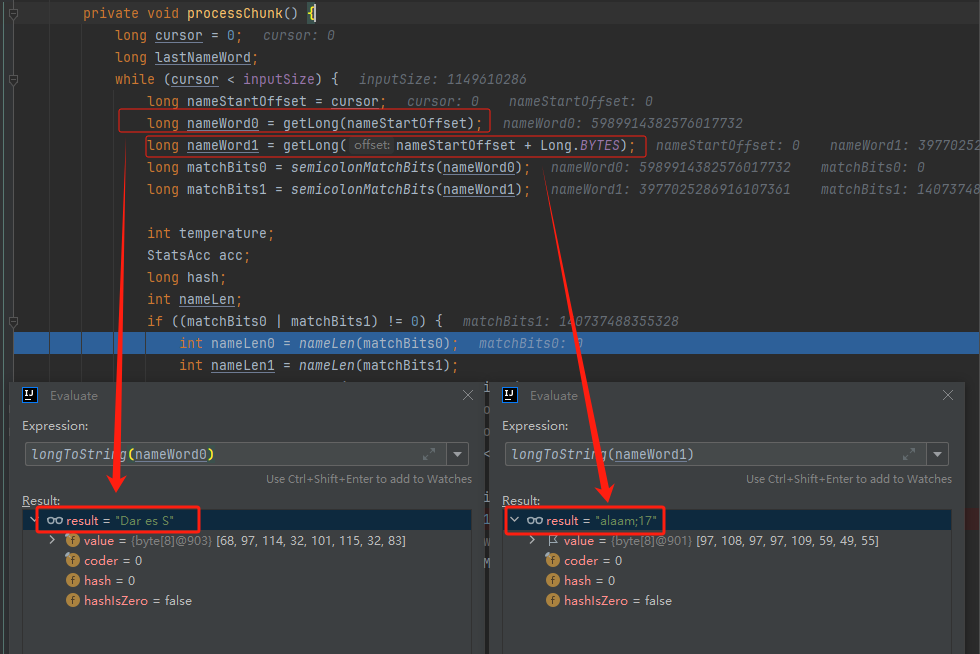
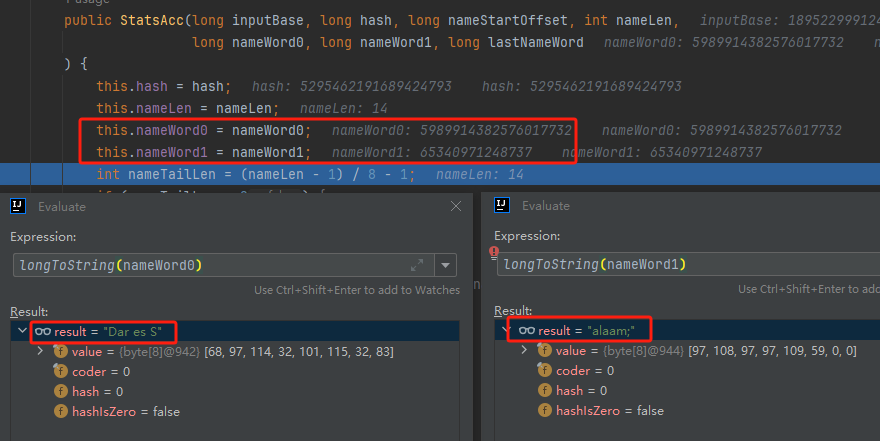
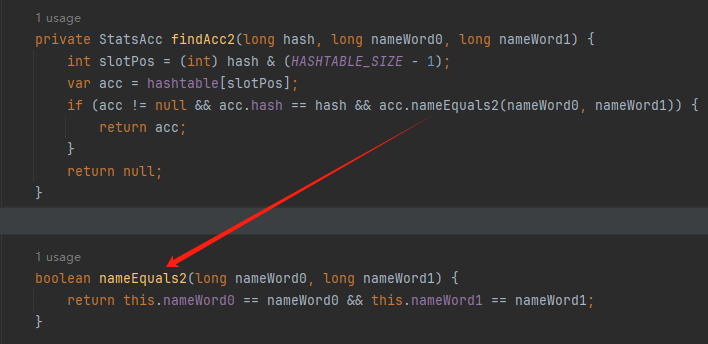
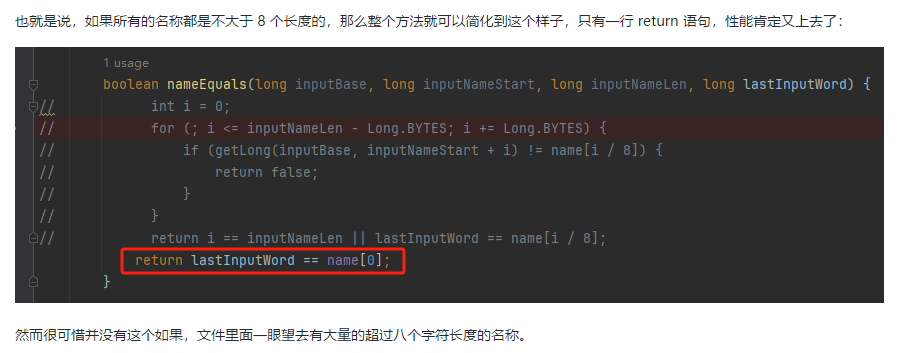
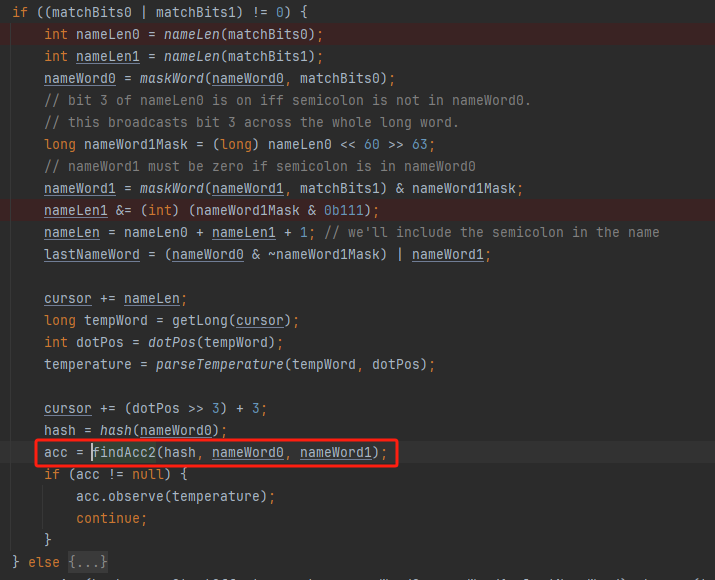
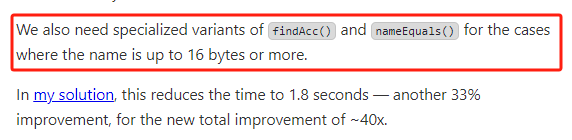
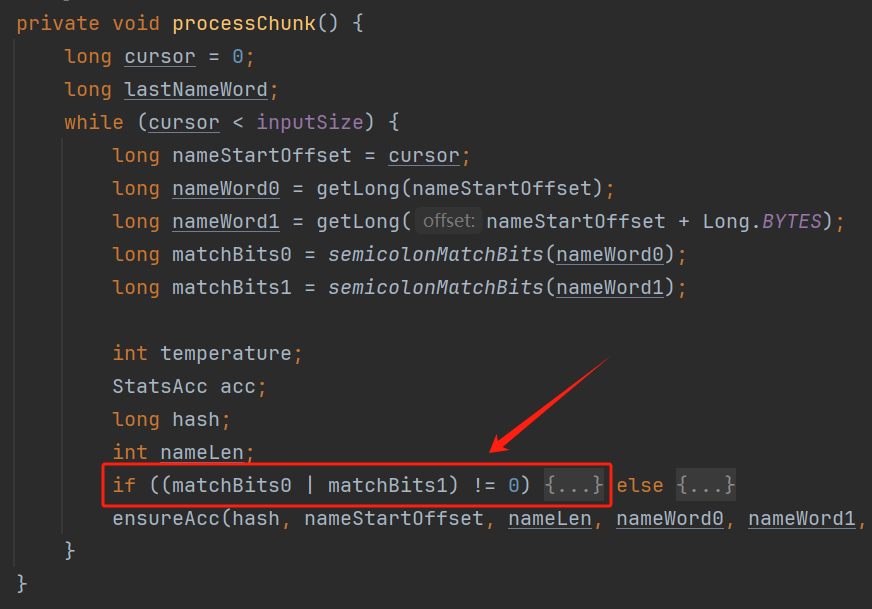
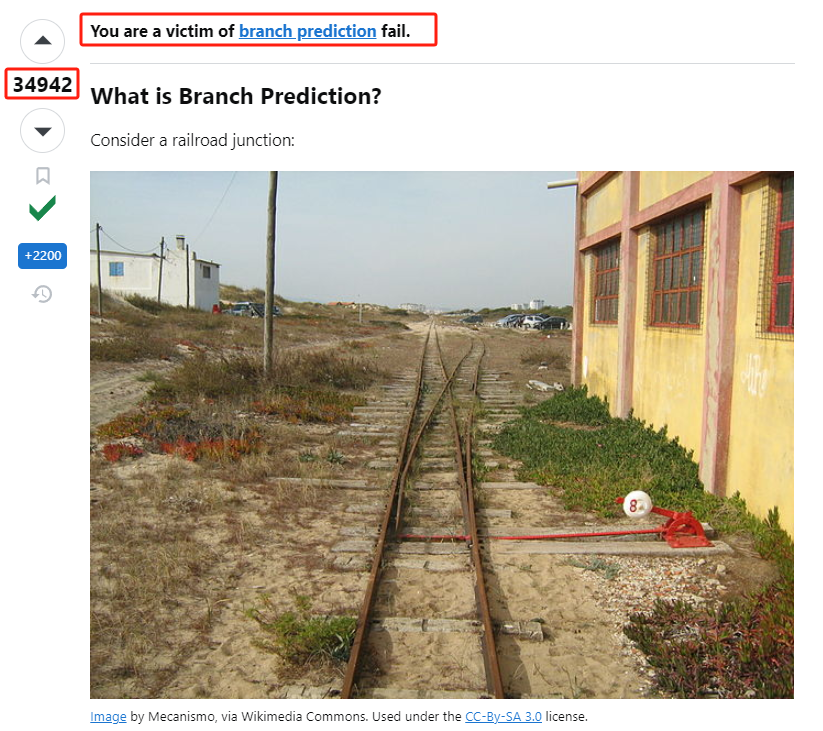
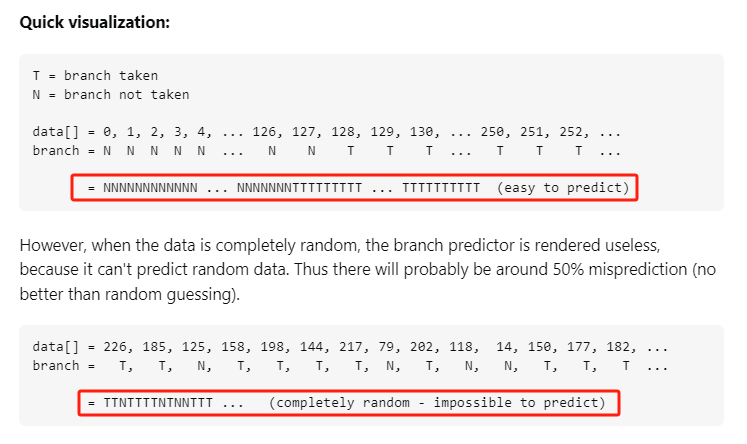
你好呀,我是歪歪。 这篇文章给大家盘一下“分支预测”这个听起来玄乎,但是对写业务代码没有任何卵用的小技巧。 上周不是发了这篇文章嘛: 这里面就提到了一嘴: 虽然对于写业务代码没啥卵用,但是高手过招的杀手锏我们还是了解一下。 我就还是顺着前面“十亿行数据”文章中的场景给大家继续讲,如果你没看过前一篇也没有关系,这两篇是相对独立的。 只要知道前一篇文章的赛题就行了,我再复述一遍。 赛题的内容非常简单,你只需要看懂这个图片就行了: 有一个十亿行数据的文件,文件的每一行记录的是一个气象站的温度值。气象站和温度用分号分隔,温度值只会保留一位小数。参赛者需要解析这个文件,然后并计算出每个气象站的最小、最大和平均温度,并按照字典序的格式输出就行了。 虽然有十亿行数据,但是一共只有 413 个气象站。 所以我们需要一个类似于这样的数据结构:哈希表<气象站名称,气象站对象> 当遇到 Hash 冲突的时候,对比一下两个“气象站名称”,来判断是不是同一个对象。 一般来说我们拿着 String 一对比,就算是搞定了,但是这是挑战赛,如果涉及到字符串,那么可能会在 GC 方面拉跨时间。 所以有个参赛者给出了这样的对比名称是否一致的代码: 首先能进这个方法说明发生了 hash 冲突。 如果 nameEquals 返回为 true,则说明冲突是因为这个气象站之前已经出现过,在 hash 表中维护过了。 如果 nameEquals 返回为 false,则说明确实是两个不同的气象站,发生了一个单纯的 hash 冲突,需要用“开放寻址”来解决 hash 冲突。 那 nameEquals 是怎么来判断到底是那种情況呢? 思路是在循环中,每次按照偏移量(inputNameStart)加上 8 字节读取文件,即一次读 8 个字符出来进行对比,在对比完整个字符串之后,如果都能匹配的上,则说明是同一个气象站。 比如,一个长度为 18 的气象站名称,那就需要对比 3 次,才能确定是否是同一个字符串。 这个逻辑,懂得起吧? 上面这个逻辑稍微有点麻烦,我给你 debug 一下,截几张图,你大概就能明白了。 首先,进入这个方法的时候 inputNameLen 为 18,表示当前是长度为 18 的气象站名称发生了 hash 冲突: 每次循环只对比 8 个字符长度,所以理论上这个循环要进行 3 次,才能确定对比的名称是否一致。 程序确实是对比了三次,但是这里作者还做了一个优化,先按下不表。 既然是对比,那么对比双方分别是谁呢? 一边是从文件中新读取的数据,一边是已经在 Hash 表中的数据。 首先,看一下第一次 8 个字符的对比: 通过上图可以看出,第一次循环,i=0,对比双方均是 “Nakhon R”。 第二次循环,i=8,对比双方均是 “atchasim”。 此时按理来说应该进入第三次循环,但是由于此时 i=16,inputNameLen=18,那么 for 循环是这样的: 不满足循环条件,循环结束了。 但是很明显不对啊,这才对比了 16 个字符呢,还有两个字符没对比呢? 别慌,这不是还有一行代码嘛: 最后一次循环,直接进行“不足额”对比,因为在另外的代码中解析数据时,已经解析出了“不足额”部分,也就是这里的 “a;”。 少了一次 for 循环处理,这个就是我前面按下不表的“一个优化”。 反正就是令人叹为观止的优化手段。 如果你还是没看懂,没有关系,很正常,我也是反复调试之后才理解到了他的思路。 你只要抓住一个点: 在 for 里面每次读取了 8 个字节进行判断。当字符串的名称大于 8 个字节的时候,就要对比多次。 但是,注意我要说但是了。 就这么牛逼的优化之下,作者通过火焰图发现,这个方法还是一定程度上拉胯了的性能: 然后他接着咂摸了一句: 我得老天爷呀,要是大多数名称都少于 8 个字节长度就好了呀。这样的话,进入 if 分支的条件将始终为 false,我就可以 predictable branch instruction 了,又可以优化一波了呀。 啥是 predictable branch instruction? 我也不知道,但是为什么不问问神奇的 GPT 呢: 上面这段话,对应到代码的部分就是这样的: 假设气象站的名称长度为 6,那么是不是直接都不会进入 for 循环,因为不满足上图中框起来的 for 循环条件。 那么就不会涉及到 if 判断,直接到标号为 ① 这部分的代码。 也就是说,如果所有的名称都是不大于 8 个长度的,那么整个方法就可以简化到这个样子,只有一行 return 语句,直接进行对比,性能肯定又上去了: 然而很可惜并没有这个如果,文件里面一眼望去有大量的超过八个字符长度的名称。 但是既然都想到这里了,我们是不是可以统计一下十亿行数据中气象站名称长度的分布到底是怎么样的呢,分析一波数据情况,万一有意外收获呢? 于是,那个哥们就掏出了这样一份代码: https://github.com/mtopolnik/billion-row-challenge/blob/main/src/Statistics.java 这个代码中的 distribution 方法就是在统计十亿行数据中气象站名称长度的分布情况,对应的代码很简单,可读性很高,我就不细说了,你感兴趣就自己去看一眼。 需要特别说明的是: 这里统计的气象站的名称长度是包含了分号的,所以后面我提到气象站的名称长度时,也都是包含了最后的分号。 这是我本地跑出来的结果,十亿数据中有 53.51% 的气象站名称长度小于等于 8,有 46.49% 的数据长度大于 8: “X” 代表大概的占比,需要注意的是,如果某一行没有 “X” 并不代表没有这样的数据,而是占比过小,通过代码缩放比例之后,连一个 “X” 都占不到。 同时从结果上看,可以分析出长度在大于 16 这个区间的数据非常非常的少。 那么这个数据可以帮助我们干啥事呢? 这就得结合代码中的 branchPrediction 方法分析了,你看这个方法的名称就很有意思啊,branch Prediction,分支预测。 逻辑有很简单: 首先标号为 ① 的地方是在统计名称长度小于等于 8 和大于 8 的数据情况。 标号为 ② 的地方,代码很简单,维护了一个 hisCount 和 missCount,一开始我也摸不清楚作者具体在干啥。 但是他提到了一个叫做“2-bit saturating counter(2 bit 饱和计数器)”的东西: 搜了一波,学习了一下,发现标号为 ② 的地方,就是实现了一个 2 bit 饱和计数器。 它的运行机制是可以分析分支预测的成功率,如果有兴趣,你可以用相关关键词查一下,这是维基上相关的介绍: 你搜的时候如果看到了上面那个状态机对应的图,就说明找对地方了。我这里就不展开了,提一句是为了表达这个程序最终输出的数据是有科学依据的,不是胡来的。 从作者的描述看,他分别以 nameLen>8 和 nameLen>16 跑了一把,运行结果很不一样: 这是我本地 nameLen>8 时的运行结果: 这是 nameLen>16 时的运行结果: 拿出来对比一波: 主要看 “misses” 这一项的输出,从 49.5% 降低到了 2.5%。 misses 这个指标,代表的是分支预测错误情况占比。 在 pref 这个性能分析工具的输出中: 在作者的描述中,经过这波优化之后,他的 branch-misses 下降了八倍,也就是说提高了分支预测成功率: 从而导致成绩从 2.4s 提升到了 1.8s。 在分析“这波优化到 1.8s”之前,我们得先看看 2.4s 这个成绩的时候,核心的循环逻辑在干啥: https://github.com/mtopolnik/billion-row-challenge/blob/main/src/Blog4.java 如果只关注我框起来的部分,那么就是每次以 8 个字节为长度进行读取。 循环结束的条件是第 108 行 matchBits != 0 为 true 的时候。 那么 matchBits 是个啥玩意呢? 是 semicolonMatchBits 方法的返回值,这个方法是这样的: 这个方法我只是看了一眼,眼睛就开始疼了,窒息感就上来了。 我直接放弃理解,把它扔给了这个哥们: 它说了这么大一堆,你就记住它的第一句话就行了:semicolonMatchBits,这个方法用于在一个长整型中查找分号的位置。 如果返回的 matchBits 不是 0,则说明当前读取到的 8 个字节里面有一个分号,然后就进入到 if 循环中,开始解析数据,最后 break 当前循环,处理下一波数据。 伪代码大概是这样的: 按理来说,这个代码里面全是操作的内存地址,没有实际操作字符串,也有大量的位运算,处理十亿行数据只需要 2.4s 了,性能已经很高了。 那么 1.8s 对应的“这波优化”到底是什么呢? 对应代码在这里: https://github.com/mtopolnik/billion-row-challenge/blob/main/src/Blog5.java 我们还是关注这个循环: 为什么要重点关注循环,我也简单的提一句。是因为循环相关的代码,是处理每一行数据都用的到的,相当于是最核心逻辑,所以要关注它。 但是这个代码可读性真的不高,我调试了大概几十次,终于懂了他在干啥事儿了。 我不会一行行去撕代码,主要是理一下思路。 我挑和本文相关的重点部分给你撕。 首先是在每一次循环的时候,都会走到标号为 ① 的部分。 这个部分是直接读取了 2 个 8 字节长度出来,即 nameWord0 和 nameWord1。 然后再分别判断 nameWord0 和 nameWord1 里面包不包含分号。 如果有,则说明 nameWord0 和 nameWord1 里面有一个完整的气象站名称,则进入标号为 ② 的代码,开始解析数据。 对应的具体的例子是这样的: 第一个 8 字节转化为字符串之后读出来是这样的:Dar es S 第二个 8 字节转化为字符串之后读出来是这样的:alaam;17 第二个 8 字节包含分号,则进行数据解析。最终解析出来的气象站名称,就是这样的:Dar es Salaam; 把 nameWord0 和 nameWord1 保存到 StatsAcc 对象中: 我知道,这个 StatsAcc 对象是突然冒出来的,但是它不重要,你可以把它理解为一个气象站对象,里面封装的是气象站名称、最低、最高、平均气温相关的字段。 好,现在我问你一个问题:如果后面又解析出来一个名称为“Dar es Salaam;”的气象站,是不是会出现 hash 冲突? 这个时候我们怎么判断到底是名称一样带来的冲突还是真的就冲突了? 是不是涉及到名称对比了? 于是这里作者专门写了一个 findAcc2 和 nameEquals2 方法: 你看这个 nameEquals2 方法,和我们前面刚刚分析过的“我得老天爷呀,要是大多数名称都少于 8 个字节长度就好了呀”对应的 nameEquals 方法是不是很像,最后只保留了一个 return 语句: 是的,他们就是同一个逻辑。只不过在 nameEquals2 方法这里,它一次性对比了两个 8 字节,或者准确的说:对于长度小于等于 16 个字节的气象站名称,它在这个方法里面一次性对比完成了,并没有任何的 if 分支判断。 注意,我说的是“长度小于等于 16 个字节”,这个条件又是从哪里冒出来的? 因为 nameEquals2 方法是 findAcc2 方法在调用,而 findAcc2 方法只有在前面标号为 ② 的部分在调用: 能进入标号为 ② 的部分,前提条件我刚刚说的是什么来着? 直接读取了 2 个 8 字节长度出来,即 nameWord0 和 nameWord1,然后分别判断后发现 nameWord0 和 nameWord1 里面至少有一个包含分号。 如果分号在 nameWord0 的第二个字节,说明气象站的名称长度为 1。 如果分号在 nameWord1 的最后一个字节,说明气象站的名称长度为 16。 所以,能进这个方法里面的,说明这个气象站的长度是小于等于 16 个字节的。 这个 nameEquals2 就是作者为长度小于等于 16 个字节的气象站定制的,和 nameEquals 对比起来,就是在出现 hash 冲突的时候,可以少走一个 for 循环和 if 分支判断。 十亿行数据,只有 416 个气象站名称,你想想“对比名称是否相等”的频率有多高,在这么高的频率下,节约了 for 循环和一个 if 判断,收益还是很可观的。 那作者为什么要为长度小于等于 16 个字节的气象站定制一个方法呢? 为什么不给长度小于等于 8 个字节的气象站定制一个方法呢? 是时候让这个“平平无奇”的数据再次出现了: 因为长度小于等于 16 个字节的气象站在整个数据中的占比是 97.6%。 这个数据决定了应该给谁定制方法。 所以作者说,他要给名称长度小于等于 16 个字节的情况专门写一个 findAcc 方法和 nameEquals 方法: 理解了标号为 ② 的地方,标号为 ③ 的地方就很好理解了:这里面专门处理长度大于 16 个字节的少数情况。 标号为 ④ 的地方就是维护哈希表的动作。 相对于 2.4s 的版本,1.8s 的版本最大的优化就是优先处理了长度小于等于 16 个字节情况。 对应到具体的代码,就是这个 if 分支判断: 结合前面的数据分析,我们知道绝大部分数据都是小于 16 个长度的,所以绝大部分情况下都会满足这个 if 分支。 优先处理绝大部分情况,这样就会提高分支预测的成功率。 好了,现在你大概知道 2.4s 到 1.8s 这之间的主要优化就是基于分支预测来的。 也再一次印证了,这种到了 CPU 指令级别的优化手段,对于写业务代码确实没啥卵用。 前面分析了“十亿行数据”比赛中一个参赛大佬,众多优化实思路中的一个。 现在我们换个视角,跳出这个比赛。 提到分支预测,你在网上搜索相关资料的时候,大概率是绕不开 stackoverflow 上这个问题的: https://stackoverflow.com/questions/11227809/why-is-processing-a-sorted-array-faster-than-processing-an-unsorted-array 提问者在问题里面附了一份 Java 代码。我放在这里,你粘过去就能跑: 代码逻辑很简单,随机生成一个 32768 大小的数组,数组内的数值的数据范围为 (-256,256)。 然后对其中大于等于 128 的数据进行求和,求和的动作循环了 10w 次。 在我的电脑,上如果没有 Arrays.sort(data) 这一行代码,运行结果要 7.66s。如果加上排序的逻辑,则只需要 2.4s。 那么问题就来了:为什么处理已排序数组比处理未排序数组更快? 经过前面的铺垫你肯定知道了,这不就是分支预测在搞鬼嘛。 在这个 if 判断中: 如果 data 数值是排好序的,那么在判断完所有的 127 之后,剩下的数值全是符合条件的数据,分支预测成功率咔咔就上去了。 这部分性能的提升完全抹去了数组排序的那点消耗。 然后我们看一下这个问题下的高赞回答: 一上来没废话,开口就知道是老江湖了:You are a victim of branch prediction fail。 victim,看起来有点陌生哈,是个考研词汇: 然后高赞回答举了一个很贴切的例子,就是上面这个火车轨道交叉口的图,我给你搬运一下。 假设你现在是老老年间的一个交叉口操作员,又一辆列车来了。但是你不知道它要走哪个方向。为什么要强调老老年间呢? 因为那个时候没有电话、无线电啥的,反正就是别人不能提前告诉你他要怎么走。 所以,你就要让列车停下来,问老司机他要往哪个方向走,然后你去扳对应的方向。 老司机每次停车也觉得烦,你每次去问也觉得烦。 那有没有更好的方法? 有,你可以去猜测这趟车要去哪个方向,反正不是 A 路线就是 B 路线嘛,你先给他掰到 A 路线上去。 如果你猜对了,老司机直接就开走了。 如果你猜错了,司机还是会将停车,你重新给他扳一下就行。 所以,如果你每次都猜对,老司机就永远不必停下来。 如果你经常猜错,老司机还是要花费大量时间停车、倒车、重新启动、骂娘。 具体到提问者的这个问题: N 代表不满足 if 条件,T 代表满足 if 条件。 如果排好序之后,CPU 基于“历史经验”来分析 N 和 T 的结果是好预测的,未排序,则反之。 接着老司机这个案例,回到我们前面的赛题部分。 对于这个 if 分支: 你可以理解为,有十亿辆车,其中 98% 的车都要走 A 路线,只有 2% 的车要装怪去走 B 路线。 所以我作为一个交叉口操作员,我就一直猜你要走 A 路线,这样我猜中的概率是 98%。 和一个个的停下来,然后去问的方式比起来,这个效率蹭蹭蹭、蹭蹭蹭、蹭蹭蹭的就上去了。 道理,就是这个道理。 歪师傅在这里继续给你换个视角。 在 Dubbo 官网中,有这样的一个链接: https://cn.dubbo.apache.org/zh/blog/2019/02/03/%E6%8F%90%E5%89%8Dif%E5%88%A4%E6%96%AD%E5%B8%AE%E5%8A%A9cpu%E5%88%86%E6%94%AF%E9%A2%84%E6%B5%8B/ 这个链接里面也提到了我们刚刚说到的 stackoverflow 上的问题。 类似的分支预测的优化,在 Dubbo 的源码里面也有。 就是这个部分: org.apache.dubbo.remoting.transport.dispatcher.ChannelEventRunnable 来,我问你一个问题。 如果在没有任何铺垫的情况下,你看到这样的代码,是不是会觉得很奇怪,感觉是两个不同的人写的。一个喜欢用 if,一个喜欢用 switch。 纯看代码逻辑的话,针对这些状态的判断,都用 if 或者都用 switch 是更优雅的。 混用看起来有一种不伦不类,感觉想要装逼,但是又不知道具体是装什么逼的感觉。 但是官网上有这样的一句话: 一个 channel 建立起来之后,超过 99.9% 情况它的 state 都是 ChannelState.RECEIVED,那么可以考虑把这个判断提前。 结合我们前面的分析,再加上这一句话,你是不是开始品出点什么味道来了? 是的,就是分支预测的味道。 同时链接里面还提供了一个 benchmark 验证。 测试了跑 100w 次,其中极大部分状态都是 RECEVIED 的情况: 验证了只有 switch 的情况: 也验证了 if+switch 混用的情况: 歪师傅还额外加了一个只用 if,但是 if 的第一个条件不是 RECEIVED 的情况: 在我本地跑出来的结果是这样的: 确实是 if+switch 的模式对应的吞吐量更大一点,性能更好一点。 所以,曾经有人看到 Dubbo 这部分代码后,提了一个优化版本: https://github.com/apache/dubbo/pull/7486/files 把这段 if+switch 代码删除了: 然后提交了一版基于枚举的代码实现: 我看了一下,枚举的实现方式优雅,确实优雅,但是被拒绝了。 在中间件的定位下,在性能的优势面前,优雅,不值一提。 另外,关于 Dubbo 的这个案例对应到我们前面赛题中就更加类似了,我给你放在一起,你自己品一品: 好了,本文写到这里就打算收尾了。 本来在我最开始的构思的时候,还应该有一部分关于“为什么分支预测正确了之后性能就提高了”的描述,打算是从 CPU 指令流水线的角度切入的。 但是我没时间写了。 而且这样的文章其实网上也不少了,我就在这里提一嘴,如果你感兴趣的话自己去找找吧,就当是个课后作业吧。 什么,你问为什么没有时间写了? 这篇文章是我在有道云笔记里面写的,之前一直用的好好的,不知道为啥,写这篇文章的时候出现了两次数据丢失的情况,就是写着写着整篇文章突然被清空了,也不支持撤回。 这个“显示历史版本”的功能真的搞得我很迷,不知道这个产品它啥逻辑: 比如 20:15 分到 23:23 分之间,我一直不停的在打字,但是它只有五个版本: 五个版本就算了,关键是它最后两次版本之间,虽然差了半小时,但是内容只差了一两行。 关键这种“突然被情况的情况”还出现了两次,所以有一部分段落,我写了三次,实在是有点搞心态了,打断了思路。 本来周末就只有一天时间的,结果还浪费了一些。 气得我当场... 什么,你问我为什么周末只有一天时间? 因为我和以前不一样了,以前两天都要卷,现在我长大了,我要留一天时间出去玩。
《十亿行数据,从71s到1.7s的优化之路。》
再看代码


还是拉胯


数据分析


这波优化
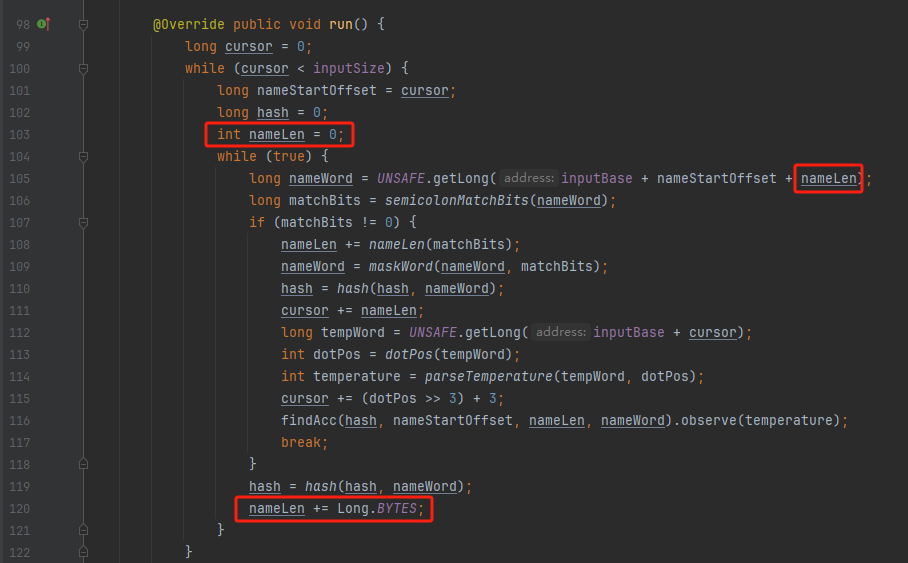

//读取位置偏移量
long nameLen = 0;
while(true){
//从给定的内存地址中读取一个长整型数;
long nameWord = UNSAFE.getLong(偏移量 + nameLen);
if(长整型数对应的字符串里面有分号){
解析数据
if(hash冲突){
1.调用前面分析过的nameEquals方法判断名称是否相等
2.相等则说明是同一个
3.不相等则用开放寻找法解决hash冲突
}
break;
}
//没有分号,说明名字还没拿完,需要继续读取下 8 个字符
nameLen += 8;
}


换个视角
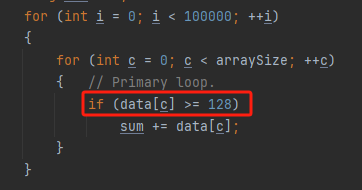
为什么处理已排序数组比处理未排序数组更快?import java.util.Arrays;
import java.util.Random;
public class Main
{
public static void main(String[] args)
{
// Generate data
int arraySize = 32768;
int data[] = new int[arraySize];
Random rnd = new Random(0);
for (int c = 0; c < arraySize; ++c)
data[c] = rnd.nextInt() % 256;
// !!! With this, the next loop runs faster
Arrays.sort(data);
// Test
long start = System.nanoTime();
long sum = 0;
for (int i = 0; i < 100000; ++i)
{
for (int c = 0; c < arraySize; ++c)
{ // Primary loop.
if (data[c] >= 128)
sum += data[c];
}
}
System.out.println((System.nanoTime() - start) / 1000000000.0);
System.out.println("sum = " + sum);
}
}
再换个视角