Transformer从入门到精通(The Annotated Transformer翻译)
Transformer从入门到精通(The Annotated Transformer)

- v2022: Austin Huang, Suraj Subramanian, Jonathan Sum, Khalid Almubarak, and Stella Biderman.
- Original : Sasha Rush .
- 翻译: YeXuan Wu SDU
Transformer架构这五年来深受人们重视。 本文是以逐行代码的形式对原论文进行注释的版本。 本文对原论文一部分章节进行了重新排序和删除,并在整个文档中添加了注释。 本文本身是一个可以运行的笔记(ipynb),理论上完全可以直接复现。
注意:翻者在翻译过程中对尾部章节进行了删减,本文只涉及相应的理论部分。以及对部分代码进行了修改,增添注释。
代码在
这里
更好的阅读体验
# !pip install -r requirements.txt# # 以下代码在colab下不会被注释
# #
# !pip install -q torchdata==0.3.0 torchtext==0.12 spacy==3.2 altair GPUtil
# !python -m spacy download de_core_news_sm
# !python -m spacy download en_core_web_smimport os
from os.path import exists
import torch
import torch.nn as nn
from torch.nn.functional import log_softmax, pad
import math
import copy
import time
from torch.optim.lr_scheduler import LambdaLR
import pandas as pd
import altair as alt
from torchtext.data.functional import to_map_style_dataset
from torch.utils.data import DataLoader
from torchtext.vocab import build_vocab_from_iterator
import torchtext.datasets as datasets
import spacy
import GPUtil
import warnings
from torch.utils.data.distributed import DistributedSampler
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
# 设置为False以跳过测试示例 (例如用于调试)
warnings.filterwarnings("ignore")
RUN_EXAMPLES = True# 这是一些全局的便捷辅助函数
def is_interactive_notebook(): # 是否为交互式笔记本
return __name__ == "__main__"
def show_example(fn, args=[]): # 显示示例
if __name__ == "__main__" and RUN_EXAMPLES:
return fn(*args)
def execute_example(fn, args=[]): # 执行示例
if __name__ == "__main__" and RUN_EXAMPLES:
fn(*args)
class DummyOptimizer(torch.optim.Optimizer): # 虚拟优化器
def __init__(self):
self.param_groups = [{"lr": 0}]
None
def step(self):
None
def zero_grad(self, set_to_none=False):
None
class DummyScheduler: # 虚拟调度器
def step(self):
None引用块中文本都是我的评论注释。主要部分的文本都来自论文本身。 括号中的内容是译者为了便于理解加的,为了更好解释代码,翻译译者还增加了部分注释
背景
¶
为了减少RNN中顺序计算的情况(这会导致难以并行化,梯度爆炸等一系列问题)其他人同样提出了Extended Neural GPU, ByteNet 和 ConvS2S,这些模型为了使所有输入和输出位置数据都可以并行地计算对应的隐层表示,都使用了卷积神经网络作为构筑模型的基本模块。
在这些模型中,为了建立输入或输出中两个任意位置的元素间联系,所需的操作数量(网络的层数)随着两个元素间距增加而增加,对于ConvS2S是线性增长,对于ByteNet是对数增长。这使得学习远距离位置之间的依赖关系变得更加困难。在Transformer中,这被减少为一个常数级别的操作,尽管这样付出一定代价,即由于单一的注意力加权位置而导致有效分辨率降低(就是说一个注意力头只能关注到少量的元素间的关系),但我们可以通过采用多头注意力机制来抵消这种影响。
自注意力有时也被叫做内部注意力,是一种为一个序列中不同位置元素建立关联的注意力机制,目的是计算出该序列的特征。 自注意力机制成功的被用于多种任务,包括阅读理解,抽象概况,文本蕴含(判断两个文本描述的矛盾程度)以及无监督学习句子的特征。 端到端的记忆网络是基于循环注意力机制而不是依赖于顺序关系(RNN这种有前后关联的结构)的循环结构,这种结构被证明在简单语言问答和语言建模任务中表现良好。
尽我们所知,Transformer是首个完全基于自注意力机制而非循环神经网络或卷积神经网络来计算输入输出信息特征的序列到序列模型。
第一部分: 模型架构
¶
模型架构
¶
class EncoderDecoder(nn.Module):
"""
一个标准的编码器-解码器框架。作为Transformer及许多其他模型的基础。
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder # 编码器(尚未实现)
self.decoder = decoder # 解码器(尚未实现)
self.src_embed = src_embed # 源词嵌入层
self.tgt_embed = tgt_embed # 目标词嵌入层
self.generator = generator # 生成器(后面有解释)
def forward(self, src, tgt, src_mask, tgt_mask):
"输入并且处理带掩码的源序列与目标序列."
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)class Generator(nn.Module):
"定义标准的线性层与softmax层(用于处理每一步最后的结果,将隐状态转换为最终的词的编号)"
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
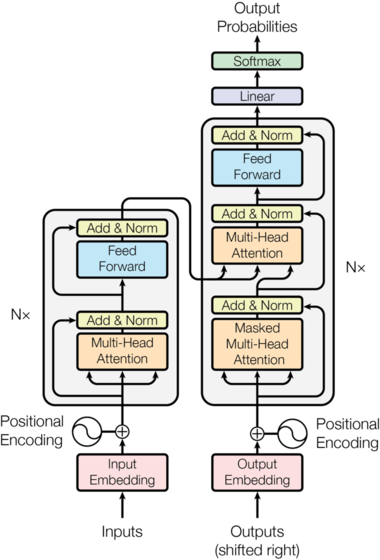
return log_softmax(self.proj(x), dim=-1)Transformer大体遵循这种架构,使用串联的自注意力层和点对点的全连接层,分别用于编码器和解码器,如图1的左半部分和右半部分所示。
def clones(module, N):
"创建 N 个相同的层"
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])class Encoder(nn.Module):
"核心的编码器是由N层的神经网络堆叠而来"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"逐层传递输入(和掩码)"
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)class LayerNorm(nn.Module):
"构建一个层归一化模块(详细信息请参见解释信息)。"
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2在这里,每个子层的输出是 $\mathrm{LayerNorm}(x + \mathrm{Sublayer}(x))$,其中 $\mathrm{Sublayer}(x)$ 是子层自身的向前传播函数。我们在每个子层的输出上使用了
(dropout)
处理,然后将其进行归一化并与子层结果相加。
为了方便进行残差连接,模型中的所有子层以及嵌入层的输出的词元都是$d_{\text{model}}=512$维。(对应的是size参数)
class SublayerConnection(nn.Module): # 对应图中的 Add & Norm
"""
一个残差连接,后面跟着一个层归一化。
为了简化代码,我们先进行归一化,然后再进行残差连接。
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"对于任何与输入数据相同词元大小的子层都应用残差连接。"
return x + self.dropout(sublayer(self.norm(x)))每个编码器层包含两个子层。第一个是多头自注意力机制,第二个是简单的位置相关的全连接前馈网络。
class EncoderLayer(nn.Module):
"编码器由自注意力和前馈网络组成"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn # 多头自注意力
self.feed_forward = feed_forward # 前馈网络
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"下面是图1(左)的连接方式"
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)解码器
¶
解码器也是一个由$N=6$个相同层堆叠而成的模型。
class Decoder(nn.Module):
"带掩码的N层解码器。"
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)除了每个编码器层中的两个子层外,解码器还插入了第三个子层(其实是图中夹在中间那层),该子层对编码器的输出执行多头注意力。 与编码器类似,我们在每个子层使用残差连接,然后进行层归一化。。
class DecoderLayer(nn.Module):
"解码器由自注意力,源注意力(就是新引入的那一层,不是完全的自注意力)和前馈网络组成"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"下面是图1(右)的连接方式"
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)我们还修改了解码器堆栈中的自注意力层,以防止后续位置的信息也参与运算(Transformer的解码器是自回归的,在训练过程中会将完整的目标输入解码器中进行训练,但是实际推理过程中我们无法提前获得目标序列,所以训练过程中使用掩码对还没推理出的元素的位置进行遮挡)。 除了使用掩码,输入的目标序列还会右偏一个位置,确保位置$i$的预测只能依赖于小于$i$的位置的已知输出。
def subsequent_mask(size): # 生成一个上三角矩阵,对角线及其右上角元素为1,其余为0
"用掩码遮挡掉后续位置"
attn_shape = (1, size, size)
subsequent_mask = torch.triu(torch.ones(attn_shape), diagonal=1).type(
torch.uint8
)
return subsequent_mask == 0下面的注意力掩码显示了每个目标词(行)可以查看(建立联系)的位置(列)。在训练期间,被阻止查看未来词的单词。
def example_mask():
LS_data = pd.concat(
[
pd.DataFrame(
{
"Subsequent Mask": subsequent_mask(20)[0][x, y].flatten(),
"Window": y,
"Masking": x,
}
)
for y in range(20)
for x in range(20)
]
)
return (
alt.Chart(LS_data)
.mark_rect()
.properties(height=250, width=250)
.encode(
alt.X("Window:O"),
alt.Y("Masking:O"),
alt.Color("Subsequent Mask:Q", scale=alt.Scale(scheme="viridis")),
)
.interactive()
)
show_example(example_mask)注意力机制
¶
注意力函数可以将“询问”和一组“键值对”映射到"输出",其中“询问”、“键"、"值"和"输出"都是向量。"输出"是"值"的加权和,其中分配给每个"值"的权重是由"询问"与相应(序号位置相同的)"键"的相关性函数(Transformer里用的是点积,本质上就是余弦相似度)计算的。
我们称我们的特殊注意力为“缩放点积注意力”。输入由维度为$d_k$的"询问"和“键”以及维度为$d_v$的”值“组成。我们计算"询问"与"键"的点积,将每个点积除以$\sqrt{d_k}$,并应用softmax函数以获得值的权重。
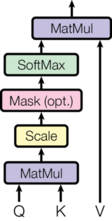
在实践中,我们同时对一组"询问"进行注意力计算,将它们打包成一个矩阵$Q$。"键"和"值"也被打包到矩阵$K$和$V$中。我们计算输出矩阵如下:
$$ \mathrm{Attention}(Q, K, V) = \mathrm{softmax}(\frac{QK^T}{\sqrt{d_k}})V $$
def attention(query, key, value, mask=None, dropout=None):
"计算 '缩放点积注意力'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = scores.softmax(dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn两个最常用的注意力函数是
加性注意力
和点积(乘性)注意力。
除了使用到了缩放因子$\frac{1}{\sqrt{d_k}}$,我们的算法与点积注意力相同。加性注意力使用具有一个隐藏层的前馈网络计算相关性函数。
在理论复杂度上,这两种注意力机制是相似的,但是在实践中,点积注意力更快,更节省空间,因为它可以使用高度优化的矩阵乘法代码实现。
当$d_k$的值较小时,这两种机制的表现相似,但是对于较大的$d_k$值,加性注意力在没有缩放的情况下优于点积注意力
(参考资料)
.。
我们猜测是因为$d_k$的值较大,点积的值也会变得很大,这会导致softmax函数的梯度很小(softmax在值绝对值较大处较为平缓)(为了说明为什么点积的值会变得很大,假设$q$和$k$的分量是独立的随机变量,均值为$0$,方差为$1$。那么他们的点积$q \cdot k = \sum_{i=1}^{d_k} q_ik_i$,均值为$0$,方差为$d_k$)。为了抵消这种影响(其实就是为了归一化),我们将点积乘以$\frac{1}{\sqrt{d_k}}$ (乘以这个值,方差就会回到 1)。
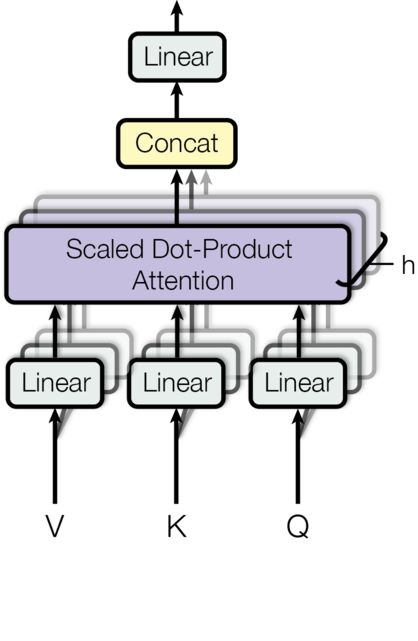
多头注意力允许模型同时关注不同位置的元素间的不同特征。使用单个注意力头,会抑制这种效果。
$$ \mathrm{MultiHead}(Q, K, V) = \mathrm{Concat}(\mathrm{head_1}, ..., \mathrm{head_h})W^O \\ \text{where}~\mathrm{head_i} = \mathrm{Attention}(QW^Q_i, KW^K_i, VW^V_i) $$
其中 $W^Q_i \in \mathbb{R}^{d_{\text{model}} \times d_k}$, $W^K_i \in \mathbb{R}^{d_{\text{model}} \times d_k}$, $W^V_i \in \mathbb{R}^{d_{\text{model}} \times d_v}$ and $W^O \in \mathbb{R}^{hd_v \times d_{\text{model}}}$.
在我们代码中,我们使用了$h=8$个并行的注意力头。对于每一个头,我们让$d_k=d_v=d_{\text{model}}/h=64$(其实就是把512维的词元分成8份,用8个不同的头计算,最后再把结果拼接在一起,很多代码和博客认为是复制8份,误导了我很久)。由于每个头的维度减小,总的计算成本与完全维度的单头注意力相似。
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"输入模型大小和注意力头的数量"
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# 我们假设 d_v 总是等于 d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4) # 4个线性层 Q, K, V, O
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"图2的实现"
if mask is not None:
# 所有的注意力头都使用相同的掩码
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) 将所有(前三个)的线性层拆分进批处理中 d_model => h x d_k
query, key, value = [
lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for lin, x in zip(self.linears, (query, key, value))
]
# 2) 在所有batch中的向量上应用注意力机制
x, self.attn = attention(
query, key, value, mask=mask, dropout=self.dropout
)
# 3) 使用view进行“拼接”,然后应用最终的线性层(第四个)
x = (
x.transpose(1, 2)
.contiguous()
.view(nbatches, -1, self.h * self.d_k)
)
del query
del key
del value
return self.linears[-1](x)注意力机制在我们模型中的应用
¶
Transformer在三个不同的地方使用多头注意力:
在"编码器-解码器连接部分"中使用的多头注意力,"询问"来自于前一个解码器层,"键"和"值"来自于编码器的输出。这使得解码器中的每个位置都可以关注输入序列中的所有位置。这模拟了序列到序列模型中的典型编码器-解码器注意力机制,
例如
。编码器中使用的多头自注意力。在自注意力层中,所有的"键"、"值"和"询问"都来自同一个地方,也就是编码器中前一层的输出。编码器中的每个位置都可以关注到编码器前一层的所有位置。
相同的,多头自注意力在解码器让解码器中的每个位置都可以关注到解码器中截止到该位置的所有位置。我们需要阻止解码器中的信息向左流动(即尚未生成的元素影响到现有元素的生成),以保持自回归性质。我们通过在缩放点积注意力中实现这一点,通过将所有与非法连接对应的softmax输入值屏蔽掉(设置为$-\infty$)。
位置相关的前馈神经网络
¶
除了多头注意力层外,我们的每一个编码器和解码器还包含一个全连接的前馈网络,它对每个位置进行相同的操作。这个网络由两个线性变换和一个ReLU激活函数组成。
$$\mathrm{FFN}(x)=\max(0, xW_1 + b_1) W_2 + b_2$$
虽然线性变换在不同位置上是相同的(就算前馈网络其实是对一个一个词元作用的,与序列无关),但是它们在不同层之间使用不同的参数。另一种描述这个过程的方法是两个卷积核大小为1的卷积(就是改变维度的那种)。输入和输出的维度是$d_{\text{model}}=512$,内层的维度是$d_{ff}=2048$。
class PositionwiseFeedForward(nn.Module):
"前馈神经网络的实现."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(self.w_1(x).relu()))class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)位置编码
¶
由于我们的模型不包含卷积或循环结构,为了让模型利用序列的顺序消息,我们必须注入一些有关位置的信息到序列的每一个词元中。为了达到这个目的,我们向串联的编码器和解码器与嵌入层中间添加了位置编码层。位置编码的维度与词元的维度相同,都为$d_{\text{model}}$,这样两者可以相加。有许多位置编码的选择,有学习的,也有固定的
参考资料
。
在我们的模型中,我们使用不同频率的正弦和余弦函数(就是固定的位置编码):
$$PE_{(pos,2i)} = \sin(pos / 10000^{2i/d_{\text{model}}})$$$$PE_{(pos,2i+1)} = \cos(pos / 10000^{2i/d_{\text{model}}})$$
其中$pos$是序列中位置的编号,$i$是词元中维度的编号。也就是说,位置编码让每个维度都对应了一个正弦波。波长从$2\pi$到$10000 \cdot 2\pi$不等,形成一个几何级数。我们选择这个函数是因为我们假设它可以让模型很容易学习到位置的相对关系,因为对于任何固定的偏移$k$,$PE_{pos+k}$都可以由$PE_{pos}$线性变换而来。
$$ \begin{split}\begin{aligned} &\begin{bmatrix} \cos(\delta \omega_j) & \sin(\delta \omega_j) \\ -\sin(\delta \omega_j) & \cos(\delta \omega_j) \\ \end{bmatrix} \begin{bmatrix} p_{i, 2j} \\ p_{i, 2j+1} \\ \end{bmatrix}\\ =&\begin{bmatrix} \cos(\delta \omega_j) \sin(i \omega_j) + \sin(\delta \omega_j) \cos(i \omega_j) \\ -\sin(\delta \omega_j) \sin(i \omega_j) + \cos(\delta \omega_j) \cos(i \omega_j) \\ \end{bmatrix}\\ =&\begin{bmatrix} \sin\left((i+\delta) \omega_j\right) \\ \cos\left((i+\delta) \omega_j\right) \\ \end{bmatrix}\\ =& \begin{bmatrix} p_{i+\delta, 2j} \\ p_{i+\delta, 2j+1} \\ \end{bmatrix} \end{aligned}\end{split} $$
这个$2 \times 2$线性变换表示矩阵不依赖与任何位置编号。
除此之外,我们在编码器和解码器的词嵌入层和位置编码层的求和结果上应用了dropout。在基准模型中,我们使用$P_{drop}=0.1$作为dropout率。
class PositionalEncoding(nn.Module):
"位置编码层的实现"
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# 计算位置编码
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(
torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model) # 换底公式
)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer("pe", pe)
def forward(self, x):
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
return self.dropout(x)下面为位置编码示例,它会根据位置生成正弦波。每个维度对应的波的频率和偏移都是不同的。
def example_positional():
pe = PositionalEncoding(20, 0)
y = pe.forward(torch.zeros(1, 100, 20))
data = pd.concat(
[
pd.DataFrame(
{
"embedding": y[0, :, dim],
"dimension": dim,
"position": list(range(100)),
}
)
for dim in [4, 5, 6, 7]
]
)
return (
alt.Chart(data)
.mark_line()
.properties(width=800)
.encode(x="position", y="embedding", color="dimension:N")
.interactive()
)
show_example(example_positional)我们还尝试使用了
需要学习的位置编码
,但是发现两种版本的结果几乎相同。我们选择了正弦波版本,因为它可以让模型推广到比训练时遇到的序列长度更长的序列。(正弦波可以不断生成下去)
完整模型
¶
这是我们使用超参数构建完整模型的函数。
def make_model(
src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1
):
"助手:根据超参数构造模型。"
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab),
)
# 这是他们的代码中很重要的一部分。
# 使用Glorot / fan_avg初始化参数。
"""
nn.init.xavier_uniform_(p) 是一个函数调用,它使用 Xavier (又称为 Glorot) 初始化方法来填充参数 p 的值。Xavier 初始化是一种常用的权重初始化技巧,旨在保持网络各层间输入和输出的方差一致,从而有助于防止梯度消失或爆炸问题,促进神经网络在训练初期的稳定收敛。
具体而言,Xavier 初始化根据权重矩阵的输入和输出维度计算一个合适的均匀分布范围,并从中随机采样值来填充权重矩阵。在 PyTorch 中,nn.init.xavier_uniform_() 版本使用的是均匀分布。"fan_avg" 指的是在计算分布范围时采用输入和输出维度的平均值(“均方根”Fan-in和Fan-out),这是 Xavier 初始化的默认行为。
"""
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model模型推理:
¶
这是我们让模型向前传播生成预测结果的代码。我们尝试使用我们的Transformer模型来记忆输入。正如你所看到的,由于模型尚未训练,输出是随机生成的。在下一节教程中,我们将构建训练函数,并尝试训练我们的模型来记忆从1到10的数字。
def inference_test():
test_model = make_model(11, 11, 2)
test_model.eval()
src = torch.LongTensor([[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]])
src_mask = torch.ones(1, 1, 10)
memory = test_model.encode(src, src_mask)
ys = torch.zeros(1, 1).type_as(src)
for i in range(9):
out = test_model.decode(
memory, src_mask, ys, subsequent_mask(ys.size(1)).type_as(src.data)
)
prob = test_model.generator(out[:, -1])
_, next_word = torch.max(prob, dim=1)
next_word = next_word.data[0]
ys = torch.cat(
[ys, torch.empty(1, 1).type_as(src.data).fill_(next_word)], dim=1
)
print("Example Untrained Model Prediction:", ys)
def run_tests():
for _ in range(10):
inference_test()
show_example(run_tests)Example Untrained Model Prediction: tensor([[0, 1, 3, 7, 6, 1, 3, 7, 3, 2]])
Example Untrained Model Prediction: tensor([[0, 8, 9, 7, 1, 6, 9, 7, 1, 6]])
Example Untrained Model Prediction: tensor([[0, 2, 2, 2, 2, 2, 2, 2, 2, 2]])
Example Untrained Model Prediction: tensor([[0, 9, 3, 7, 7, 7, 5, 1, 9, 3]])
Example Untrained Model Prediction: tensor([[0, 8, 8, 8, 8, 8, 6, 1, 7, 7]])
Example Untrained Model Prediction: tensor([[ 0, 7, 6, 6, 10, 10, 10, 7, 3, 6]])
Example Untrained Model Prediction: tensor([[ 0, 7, 10, 10, 10, 10, 10, 10, 10, 10]])
Example Untrained Model Prediction: tensor([[ 0, 5, 5, 5, 10, 9, 4, 7, 9, 4]])
Example Untrained Model Prediction: tensor([[0, 7, 5, 5, 2, 2, 2, 2, 2, 2]])
Example Untrained Model Prediction: tensor([[0, 9, 9, 9, 9, 9, 9, 9, 9, 9]])第二部分: 模型训练
¶
训练
¶
本节将描述我们模型的训练过程。
稍等一下,我们先介绍一些训练标准编码器解码器模型所需的工具。首先我们定义一个批处理对象,它保存了用于训练的源和目标句子,以及构造的掩码。
批处理和掩码
¶
class Batch:
"""用于在训练过程中生成带掩码的批数据的对象"""
def __init__(self, src, tgt=None, pad=2): # 2 = <blank>
self.src = src
self.src_mask = (src != pad).unsqueeze(-2)
if tgt is not None:
self.tgt = tgt[:, :-1]
self.tgt_y = tgt[:, 1:]
self.tgt_mask = self.make_std_mask(self.tgt, pad)
self.ntokens = (self.tgt_y != pad).data.sum()
@staticmethod
def make_std_mask(tgt, pad):
"构造一个掩码去挡住pad词元和尚未生成的词元。"
tgt_mask = (tgt != pad).unsqueeze(-2)
tgt_mask = tgt_mask & subsequent_mask(tgt.size(-1)).type_as(
tgt_mask.data
) # 这里利用到了广播机制
return tgt_mask接下来我们创建一个通用的用于训练与评分的函数,同时也能对损失进行跟踪。我们向函数中传入一个能处理参数更新的损失计算函数
训练代码
¶
class TrainState:
"""记录计算过的步数,样例数和词元数"""
step: int = 0 # 当前轮的步数
accum_step: int = 0 # 优化器调整参数的次数
samples: int = 0 # 处理过的样例数
tokens: int = 0 # 处理过的词元数def run_epoch(
data_iter,
model,
loss_compute,
optimizer,
scheduler,
mode="train",
accum_iter=1,
train_state=TrainState(),
):
"""训练单轮"""
start = time.time()
total_tokens = 0
total_loss = 0
tokens = 0
n_accum = 0
for i, batch in enumerate(data_iter):
out = model.forward(
batch.src, batch.tgt, batch.src_mask, batch.tgt_mask
)
loss, loss_node = loss_compute(out, batch.tgt_y, batch.ntokens)
# loss_node = loss_node / accum_iter
if mode == "train" or mode == "train+log":
loss_node.backward()
train_state.step += 1
train_state.samples += batch.src.shape[0]
train_state.tokens += batch.ntokens
if i % accum_iter == 0:
optimizer.step()
optimizer.zero_grad(set_to_none=True)
n_accum += 1
train_state.accum_step += 1
scheduler.step()
total_loss += loss
total_tokens += batch.ntokens
tokens += batch.ntokens
if i % 40 == 1 and (mode == "train" or mode == "train+log"):
lr = optimizer.param_groups[0]["lr"]
elapsed = time.time() - start
print(
(
"Epoch Step: %6d | Accumulation Step: %3d | Loss: %6.2f "
+ "| Tokens / Sec: %7.1f | Learning Rate: %6.1e"
)
% (i, n_accum, loss / batch.ntokens, tokens / elapsed, lr)
)
start = time.time()
tokens = 0
del loss
del loss_node
return total_loss / total_tokens, train_state训练数据和批处理
¶
我们基于标准的WMT 2014 英德数据集(包含了450万句子对)。句子被编码成字节对,源和目标有一个相同的词表,大约有37000个词元。对于英法翻译器训练,我们使用了更大的WMT 2014 英法数据集,包含了3600万句子,并将词元分割成了一个32000个词片的词表。
句子对根据近似的序列长度打包成同一个训练批次。每个训练批次包含了一组句子对,包含了大约25000个源词元和25000个目标词元。
硬件与训练计划
¶
我们在一台有 8 张 NVIDIA P100 GPUs 的机器上训练我们的模型。对于我们的使用论文上述超参数的基准模型,每个训练步骤大约需要 0.4 秒。我们训练基准模型共 100,000 步,共计 12 小时。对于我们的大模型,步骤时间为 1.0 秒。大模型训练了 300,000 步(3.5 天)。
备注:此部分十分重要。需要使用这些设置来训练模型。
以下是对于不同模型大小和超参数的模型,学习率随训练步数的变化曲线
def rate(step, model_size, factor, warmup):
"""
为了避免零值被赋予负指数导致错误,我们必须在LambdaLR函数(本函数就是LambdaLR函数)中将step参数默认设置为1。
"""
if step == 0:
step = 1
return factor * (
model_size ** (-0.5) * min(step ** (-0.5), step * warmup ** (-1.5))
)def example_learning_schedule():
opts = [
[512, 1, 4000], # 样例 1
[512, 1, 8000], # 样例 2
[256, 1, 4000], # 样例 3
]
dummy_model = torch.nn.Linear(1, 1)
learning_rates = []
# 我们有3个样例在opts列表中
for idx, example in enumerate(opts):
# 为每个样例运行20000个epoch
optimizer = torch.optim.Adam(
dummy_model.parameters(), lr=1, betas=(0.9, 0.98), eps=1e-9
)
lr_scheduler = LambdaLR(
optimizer=optimizer, lr_lambda=lambda step: rate(step, *example)
)
tmp = []
# 进行20000个虚拟训练步,保存每一步的学习率
for step in range(20000):
tmp.append(optimizer.param_groups[0]["lr"])
optimizer.step()
lr_scheduler.step()
learning_rates.append(tmp)
learning_rates = torch.tensor(learning_rates)
# 开启altair处理超过5000行的数据
alt.data_transformers.disable_max_rows()
opts_data = pd.concat(
[
pd.DataFrame(
{
"Learning Rate": learning_rates[warmup_idx, :],
"model_size:warmup": ["512:4000", "512:8000", "256:4000"][
warmup_idx
],
"step": range(20000),
}
)
for warmup_idx in [0, 1, 2]
]
)
return (
alt.Chart(opts_data)
.mark_line()
.properties(width=600)
.encode(x="step", y="Learning Rate", color="model_size\:warmup:N")
.interactive()
)
example_learning_schedule()我们通过 KL div loss 实现标签平滑。我们不使用热独编码,而是创建了 一种正确的词元的概率为
confidence
,其他词元的总概率为
smoothing
(平均分配给除了正确词元的其他词元)的概率分布来代替热度编码。
class LabelSmoothing(nn.Module):
"标签平滑的实现"
def __init__(self, size, padding_idx, smoothing=0.0):
super(LabelSmoothing, self).__init__()
self.criterion = nn.KLDivLoss(reduction="sum")
self.padding_idx = padding_idx
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
self.size = size
self.true_dist = None
def forward(self, x, target):
assert x.size(1) == self.size
true_dist = x.data.clone()
true_dist.fill_(self.smoothing / (self.size - 1)) # 原文这里是 -2 ,但是译者无法理解其含义,所以将其改为 -1
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence) # 将正确词元的概率设置为confidence,这一步其实是将 target序列转换为独热编码(这里是标签平滑)
true_dist[:, self.padding_idx] = 0
mask = torch.nonzero(target.data == self.padding_idx)
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist = true_dist
return self.criterion(x, true_dist.clone().detach()) # 计算损失下面是一个示例,展示了如何根据 'confidence' 计算对应的标签平滑分布。
# 标签平滑示例
def example_label_smoothing():
crit = LabelSmoothing(5, 0, 0.4)
predict = torch.FloatTensor(
[
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
]
)
crit(x=predict.log(), target=torch.LongTensor([2, 1, 0, 3, 3]))
LS_data = pd.concat(
[
pd.DataFrame(
{
"target distribution": crit.true_dist[x, y].flatten(),
"columns": y,
"rows": x,
}
)
for y in range(5)
for x in range(5)
]
)
return (
alt.Chart(LS_data)
.mark_rect(color="Blue", opacity=1)
.properties(height=200, width=200)
.encode(
alt.X("columns:O", title=None),
alt.Y("rows:O", title=None),
alt.Color(
"target distribution:Q", scale=alt.Scale(scheme="viridis")
),
)
.interactive()
)
show_example(example_label_smoothing)如果模型对某个选择非常自信(过拟合),标签平滑计算实际上会开始对模型进行惩罚。
def loss(x, crit):
d = x + 3 * 1
predict = torch.FloatTensor([[ 1 / d, x / d, 1 / d, 1 / d, 1 / d]])
return crit(predict.log(), torch.LongTensor([1])).data
def penalization_visualization():
crit = LabelSmoothing(5, 0, 0.1)
loss_data = pd.DataFrame(
{
"Loss": [loss(x, crit) for x in range(1, 100)],
"Steps": list(range(99)),
}
).astype("float")
return (
alt.Chart(loss_data)
.mark_line()
.properties(width=350)
.encode(
x="Steps",
y="Loss",
)
.interactive()
)
show_example(penalization_visualization)第一个例子
¶
我们可以从一个简单的复述任务开始。给定在一个小词汇表里的随机输入序列,目标是生成返回相同的序列。
生成数据
¶
def data_gen(V, batch_size, nbatches):
"生成一个随机的源-目标复述任务的数据集"
for i in range(nbatches):
data = torch.randint(1, V, size=(batch_size, 10))
data[:, 0] = 1
src = data.requires_grad_(False).clone().detach()
tgt = data.requires_grad_(False).clone().detach()
yield Batch(src, tgt, 0)损失计算
¶
class SimpleLossCompute:
"一个简单的损失计算和训练函数。"
def __init__(self, generator, criterion):
self.generator = generator
self.criterion = criterion
def __call__(self, x, y, norm):
x = self.generator(x)
sloss = (
self.criterion(
x.contiguous().view(-1, x.size(-1)), y.contiguous().view(-1)
)
/ norm
)
return sloss.data * norm, sloss贪心解码
¶
这段代码使用贪心解码来预测翻译,以简化计算。(直接选取当前概率最大的预测结果,不考虑后面的影响,事实上一般是使用束搜索)
def greedy_decode(model, src, src_mask, max_len, start_symbol):
memory = model.encode(src, src_mask)
ys = torch.zeros(1, 1).fill_(start_symbol).type_as(src.data)
for i in range(max_len - 1):
out = model.decode(
memory, src_mask, ys, subsequent_mask(ys.size(1)).type_as(src.data)
)
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim=1)
next_word = next_word.data[0]
ys = torch.cat(
[ys, torch.zeros(1, 1).type_as(src.data).fill_(next_word)], dim=1
)
return ys# 训练简单的复述任务
def example_simple_model():
V = 11
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
model = make_model(V, V, N=2)
optimizer = torch.optim.Adam(
model.parameters(), lr=0.5, betas=(0.9, 0.98), eps=1e-9
)
lr_scheduler = LambdaLR(
optimizer=optimizer,
lr_lambda=lambda step: rate(
step, model_size=model.src_embed[0].d_model, factor=1.0, warmup=400
),
)
batch_size = 80
for epoch in range(20):
model.train()
run_epoch(
data_gen(V, batch_size, 20),
model,
SimpleLossCompute(model.generator, criterion),
optimizer,
lr_scheduler,
mode="train",
)
model.eval()
run_epoch(
data_gen(V, batch_size, 5),
model,
SimpleLossCompute(model.generator, criterion),
DummyOptimizer(),
DummyScheduler(),
mode="eval",
)[0]
model.eval()
src = torch.LongTensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])
max_len = src.shape[1]
src_mask = torch.ones(1, 1, max_len)
print(greedy_decode(model, src, src_mask, max_len=max_len, start_symbol=0))
execute_example(example_simple_model)Epoch Step: 1 | Accumulation Step: 2 | Loss: 3.14 | Tokens / Sec: 1705.7 | Learning Rate: 5.5e-06
Epoch Step: 1 | Accumulation Step: 2 | Loss: 2.13 | Tokens / Sec: 2466.4 | Learning Rate: 6.1e-05
Epoch Step: 1 | Accumulation Step: 2 | Loss: 1.78 | Tokens / Sec: 2785.6 | Learning Rate: 1.2e-04
Epoch Step: 1 | Accumulation Step: 2 | Loss: 1.53 | Tokens / Sec: 2779.2 | Learning Rate: 1.7e-04
Epoch Step: 1 | Accumulation Step: 2 | Loss: 1.07 | Tokens / Sec: 2791.2 | Learning Rate: 2.3e-04
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.68 | Tokens / Sec: 2477.7 | Learning Rate: 2.8e-04
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.37 | Tokens / Sec: 2862.2 | Learning Rate: 3.4e-04
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.25 | Tokens / Sec: 2790.3 | Learning Rate: 3.9e-04
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.13 | Tokens / Sec: 2812.5 | Learning Rate: 4.5e-04
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.15 | Tokens / Sec: 2796.5 | Learning Rate: 5.0e-04
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.13 | Tokens / Sec: 2737.6 | Learning Rate: 5.6e-04
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.06 | Tokens / Sec: 2771.7 | Learning Rate: 6.1e-04
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.23 | Tokens / Sec: 2935.7 | Learning Rate: 6.7e-04
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.07 | Tokens / Sec: 2880.7 | Learning Rate: 7.2e-04
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.07 | Tokens / Sec: 2637.4 | Learning Rate: 7.8e-04
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.08 | Tokens / Sec: 2950.8 | Learning Rate: 8.3e-04
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.07 | Tokens / Sec: 2932.8 | Learning Rate: 8.9e-04
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.08 | Tokens / Sec: 2659.8 | Learning Rate: 9.4e-04
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.09 | Tokens / Sec: 2793.8 | Learning Rate: 1.0e-03
Epoch Step: 1 | Accumulation Step: 2 | Loss: 0.13 | Tokens / Sec: 2851.5 | Learning Rate: 1.1e-03