DS-Net:可落地的动态网络,实际加速1.62倍,快改造起来 | CVPR 2021 Oral
论文提出能够适配硬件加速的动态网络DS-Net,通过提出的double-headed动态门控来实现动态路由。基于论文提出的高性能网络设计和IEB、SGS训练策略,仅用1/2-1/4的计算量就能达到静态SOTA网络性能,实际加速也有1.62倍
来源:晓飞的算法工程笔记 公众号
论文: Dynamic Slimmable Network

Introduction
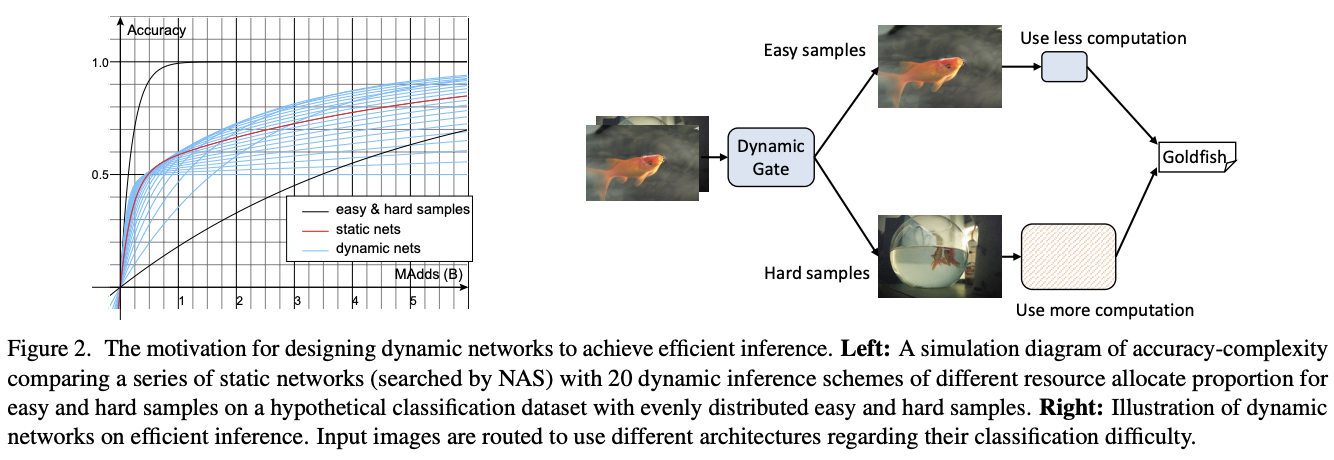
模型速度在模型的移动端应用中十分重要,提高模型推理速度的方法有模型剪枝、权值量化、知识蒸馏、模型设计以及动态推理等。其中,动态推理根据输入调整其结构,降低整体计算耗时,包含动态深度和动态维度两个方向。如图2所示,动态网络自动在准确率和计算量之间trade-off,比静态的模型设计和剪枝方法要灵活。
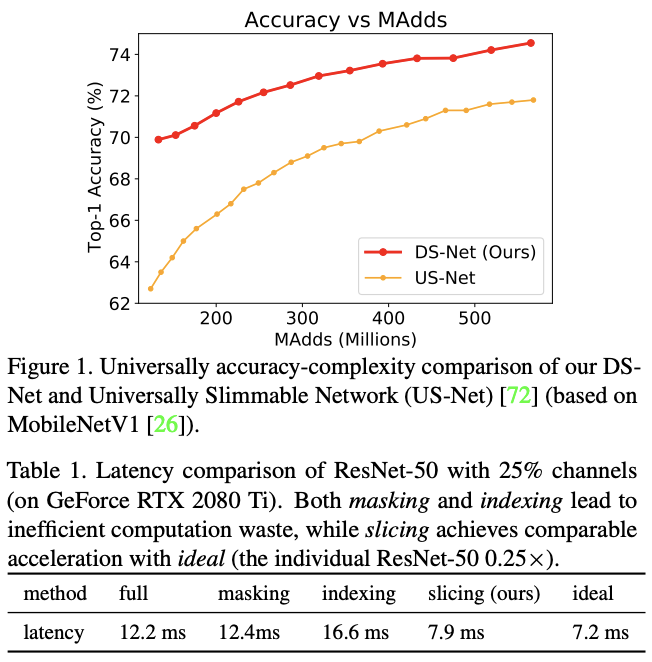
然而,论文发现包含动态维度的网络的实际运行速度大都不符合预期,主要原因在于动态剪枝后的稀疏卷积与当前硬件的计算加速不匹配。大多数卷积核的动态剪枝通过zero masking(常规卷积后再通过mask取对应的输出)或path indexing(直接通过
\([:,:]\)
获取对应的新卷积再计算)来实现,如表1所示,这些方法的计算效率都不高,导致整体推理速度没有加快。
为了解决这一问题,论文提出了动态可精简网络DS-Net,在实现动态网络的同时也有很好的硬件匹配性。
论文的主要贡献如下:
- 提出新的动态网络路由机制,通过提出的double-headed动态门控来实现网络结构的动态路由。另外,卷积的动态剪枝通过切片的方式保持权值的内存连续性,可以很好地适配硬件加速。
- 提出用于DS-Net的两阶段训练方式,包含IEB和SGS方法。IEB用于稳定可精简网络的训练,SGS用于提高门控输出的多样性,两者都能帮助提高DS-Net的性能。
- 通过ImageNet实验对比,DS-Net的整体性能比SOTA动态网络高约5.9%,比ResNet和MobileNet等静态网络性能稍微下降,但是有2-4倍计算量节省以及1.62倍实际推理加速。
Dynamic Slimmable Network
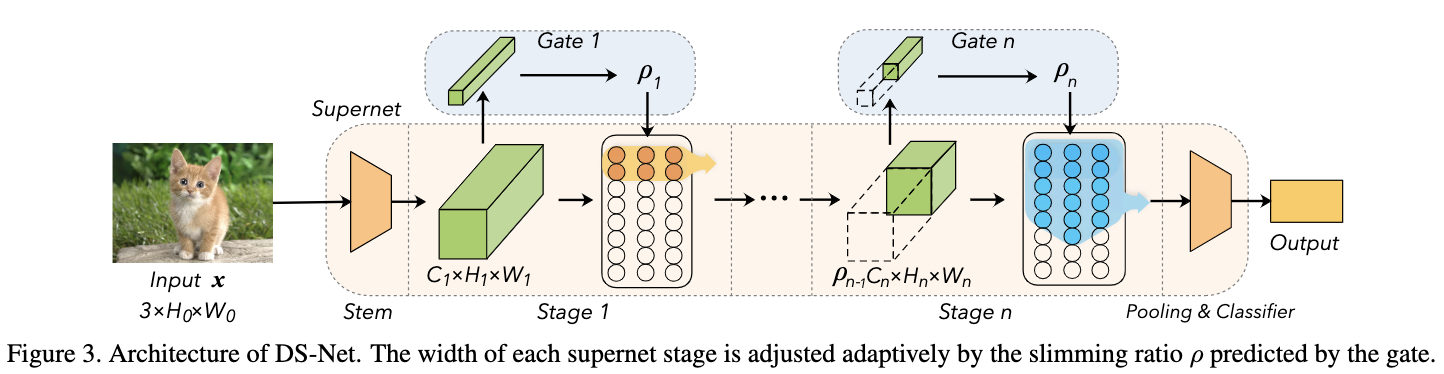
论文提出的dynamic slimmable network通过学习可精简的超网(supernet)以及动态门控(gating)机制,达到根据不同输入样本动态生成网络的目的。如图3所示,DS-Net的超网为包含全部完整卷积的完整网络。动态门控则是一系列预测模块,根据输入动态设定每个阶段的卷积维度,进而生成子网,这一过程也称为动态路由(dynamic routing)。
目前的动态网络研究中,主网络和动态路由通常是联合训练的,类似于联合优化的网络搜索方法。参考one-shot NAS方法,论文提出解耦的两阶段训练方法来保证DS-Net中每个路径的泛化性。在stage I中,禁用门控的功能并用IEB方法训练超网,在stage II中,固定超网的权值单独用SGS方法训练门控。
Dynamic Supernet
这里先介绍可在硬件高效运行的通道切片方法以及论文设计超网,然后再介绍Stage I中用到的IEB方法。
Supernet and Dynamic Channel Slicing
在如动态裁剪、动态卷积等动态网络中,卷积核
\(\mathcal{W}\)
根据输入
\(\mathcal{X}\)
进行动态参数化
\(\mathcal{A}(\theta, \mathcal{X})\)
,这样的卷积可表示为:
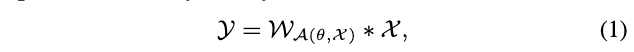
动态卷积根据输入去掉不重要的特征通道,降低理论计算量,但其实际加速大都不符合预期。由于通道的稀疏性与硬件加速技术不匹配,在计算时不得不多次索引和拷贝需要的权值到新的连续内存空间再进行矩阵相乘。为了更好地加速,卷积核在动态权值选择时必须保持连续且相对静态。
基于上面的分析,论文设计了结构路由器
\(\mathcal{A}(\theta)\)
,能够偏向于输出稠密的选择结果。对于
\(N\)
输出、
\(M\)
输入的卷积核
\(W\in\mathbb{R}^{N\times M}\)
,结构路由器输出精简比例
\(\rho\in(0,1]\)
,通过切片操作
\([:]\)
选择卷积核的前
\(\rho\times N\)
部分构成切片动态卷积:
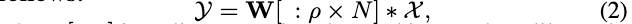
\([:]\)
切片操作加
\(*\)
稠密矩阵乘法要比索引操作或稀疏矩阵相乘要高效得多,保证了实际运行时的速度。
SuperNet
将多个动态卷积组合起来即可搭建超网,超网通过设置不同的特征维度组合创建多个子网。将结构路由器禁用时,超网等同于常见可精简网络,可用类似的方法进行预训练。
In-place Ensemble Bootstrapping
经典的Universally Slimmable Networks通过两个方法来有效地提升整体的性能:
- sandwich rule:每次训练的网络组合包含最大的子网、最小的子网以及其它子网,其中最大的子网和最小的子网分别决定了可精简网络性能的上界和下界。
- in-plcae distillation:将最大子网的向量输出作为其它子网的训练目标,而最大子网的训练目标则是数据集标签,这样对可精简网络更好地收敛有很好的帮助。
虽然in-place distillation很有效,但最大子网权值的剧烈抖动会导致训练难以收敛。根据BigNas的实验,使用in-place distillation训练较为复杂的网络会极其不稳定。如果没有残差连接或特殊的权值初始化,在训练初期甚至会出现梯度爆炸的情况。为了解决可精简网络收敛难的问题并且提升整体性能,论文提出了In-plcae Ensemble Boostrapping(IEB)方法。
首先,参考BYOL等自监督和半监督方法,使用过往的表达能力进行自监督的in-plcae distillation训练的做法,将模型的指数滑动平均(EMA, exponential moving average)作为目标网络生成目标向量。定义
\(\theta\)
和
\(\theta^{'}\)
为在线网络和目标网络:
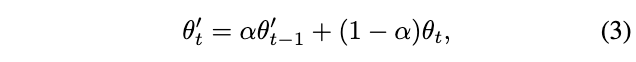
\(\alpha\)
为动量因子,控制历史参数的比例,
\(t\)
为训练轮次。在训练时,模型的EMA会比在线网络更加稳定和准确,为精简子网提供高质量的训练目标。
接着,参考MealV2使用一组teacher网络来生成更多样的输出向量供student网络学习的做法,在进行in-place distillation时使用不同的子网构成一组teacher网络,主要提供目标向量给最小子网学习。
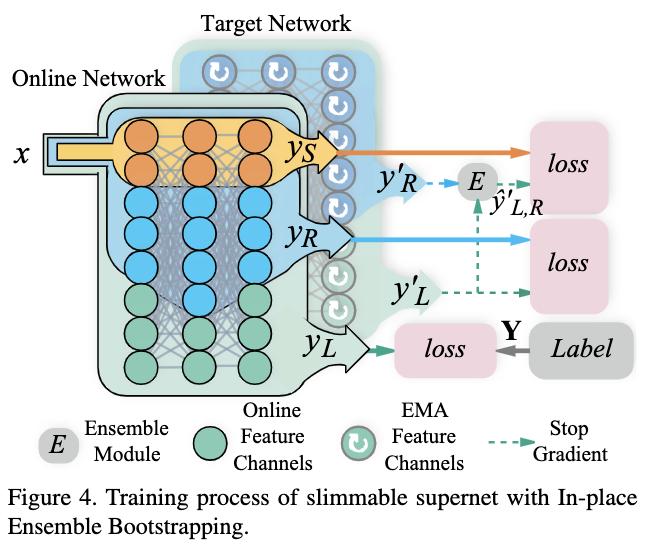
整体训练过程如图4所示。结合sandwich rule和上述优化的in-place distillation,每论训练有以下3种网络:
- 最大的子网
\(L\)
使用数据集标签作为训练目标。 - \(n\)
个随机维度的子网使用目标网络的最大子网的向量输出作为训练目标。 - 最小的子网使用上述子网在目标网络中对应的子网的向量输出的组合作为训练目标,即训练目标为:
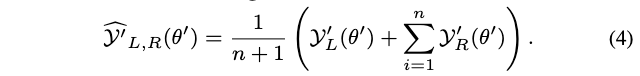
总结起来,超网训练的IEB损失为:
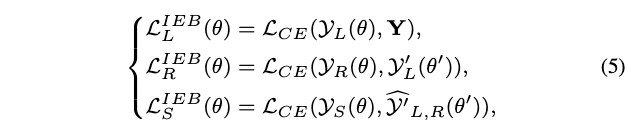
Dynamic Slimming Gate
这里先介绍公式2中输出
\(\rho\)
因子的结构路由器
\(\mathcal{A}(\theta, \mathcal{X})\)
以及动态门控的double-headed设计,最后再介绍Stage II训练使用的sandwich gate sparsification(SGS)方法。
Double-headed Design
将特征图转换为精简比例
\(\rho\)
有两种方法:1)标量模式:直接通过sigmoid输出0到1的标量作为精简比例。2)one-hot模式:通过argmax/softmax得到one-hot向量,选择离散的候选向量
\(L_p\)
中对应的精简比例。
论文对这两种方法进行对比后,选择了性能更好的one-hot模式。为了将特征图
\(\mathcal{X}\)
转换为one-hot向量,将
\(\mathcal{A(\theta, \mathcal{X})}\)
转换为两个函数的组合:
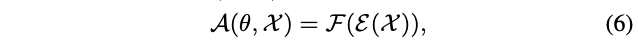
\(\mathcal{E}\)
将特征图下采样为向量,
\(\mathcal{F}\)
将向量转化为one-hot向量用于后续的维度切片。参考DenseNet等网络,
\(\mathcal{E}\)
为全局池化层,
\(\mathcal{F}\)
为全连接层
\(W_1\in\mathbb{R}^{d\times C_n}\)
+ReLU+
\(W_2\in\mathbb{R}^{g\times d}\)
+argmax函数(
\(d\)
为中间特征维度,
\(g\)
为
\(L_p\)
的长度):

以图3的第
\(n\)
个门控为例,将大小为
\(\rho_{n-1}C_n\times H_n\times W_n\)
的特征图
\(\mathcal{X}\)
转换成向量
\(\mathcal{X}_{\mathcal{E}}\in \mathbb{R}^{\rho_{n-1}C_n}\)
,随后用argmax将向量进一步转换成one-hot向量,最后通过计算one-hot向量与
\(L_p\)
的点积得到预测的精简比例:
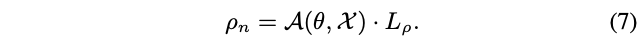
论文采用的精简比例生成方法跟通道注意力方法十分类似,通过添加第三个全连接层
\(W_3^{\rho_{n-1}\times d}\)
,可直接为网络引入注意力机制。基于上面的结构,论文提出double-headed dynamic gate,包含用于通道路由的hard channel slimming head以及用于通道注意力的soft channel attention head,其中soft channel attention head定义为:
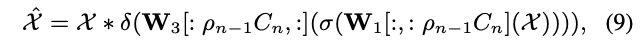
\(\delta(x)=1+tanh(x)\)
,channel attention head参与stage I的训练。
Sandwich Gate Sparsification
在stage II训练中,论文使用分类交叉熵损失
\(L_{cls}\)
和复杂度惩罚函数
\(L_{cplx}\)
来端到端地训练门控,引导门控为每个输入图片选择最高效的子网。为了能够用
\(L_{cls}\)
来训练不可微的slimming head,论文尝试了经典的gumbel-softmax方法,但在实验中发现门控很容易收敛到静态的选项,即使加了Gumbel噪声也优化不了。
为了解决收敛问题并且增加门控的多样性,论文提出Sandwich Gate Sparsification(SGS)训练方法,使用最大子网和最小子网识别输入图片中的hard和easy,为其生成slimming head输出精简因子的GT。基于训练好的超网,将输入大致地分为三个级别:
- Easy samples
\(\mathcal{X}_{easy}\)
:能够被最小子网识别的输入。 - Hard samples
\(\mathcal{X}_{hard}\)
:不能被最大子网识别的输入。 - Dependent samples
\(\mathcal{X}_{dep}\)
:不属于上述两种的输入。
为了最小化计算消耗,easy samples应该都使用最小子网进行识别,即门控的GT为
\(\mathcal{T}(\mathcal{X}_{easy})=[1,0,\cdots,0]\)
。而对于dependent samples和hard samples则应该鼓励其尽量使用最大的子网进行识别,即门控的GT为
\(\mathcal{T}(\mathcal{X}_{hard})=\mathcal{T}(\mathcal{X}_{dep})=[0,0,\cdots,1]\)
。基于这些生成的门控GT,SGS损失定义为:
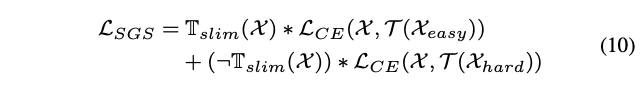
\(\mathbb{T}_{sim}(\mathcal{X})\in{0,1}\)
代表
\(\mathcal{X}\)
是否应该被最小子网预测,
\(\mathcal{L}_{CE}(\mathcal{X},\mathcal{T})=-\sum\mathcal{T}*log(\mathcal{X})\)
为门控输出与生成GT之间交叉熵损失。
Experiment
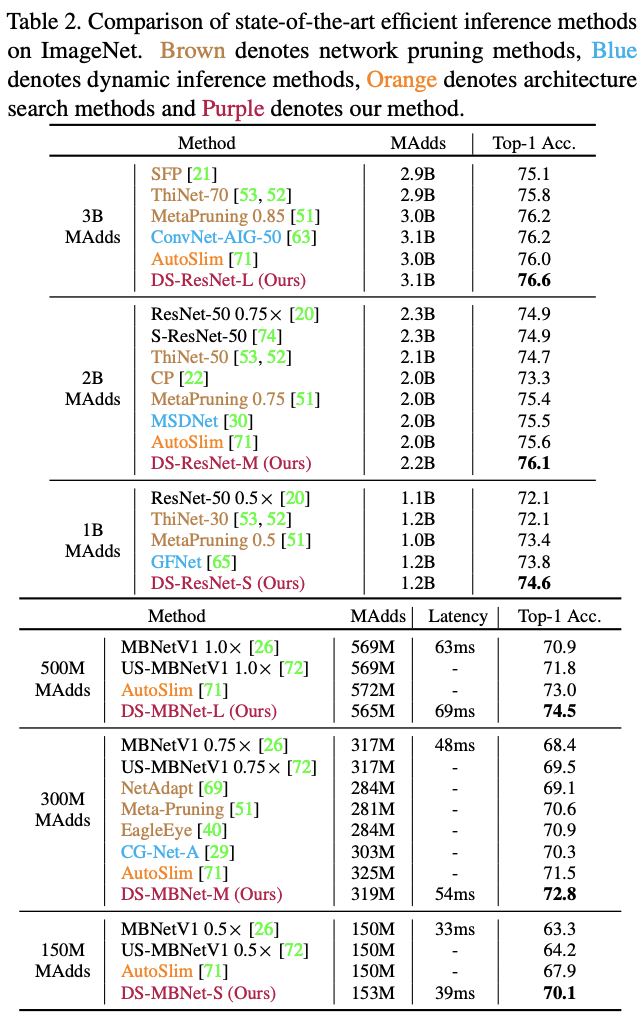
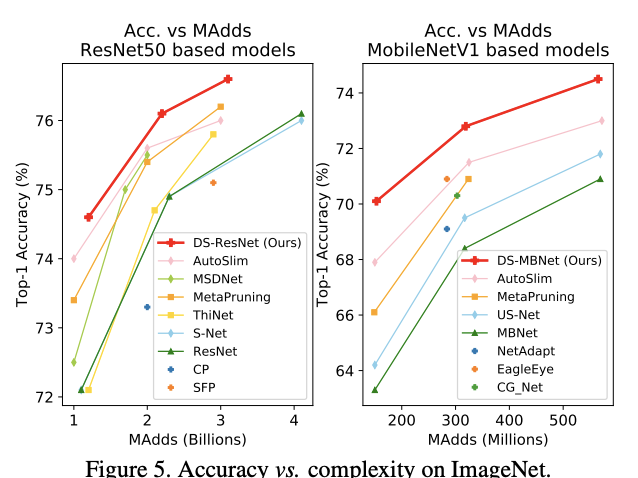
与不同类型的网络对比ImageNet性能。
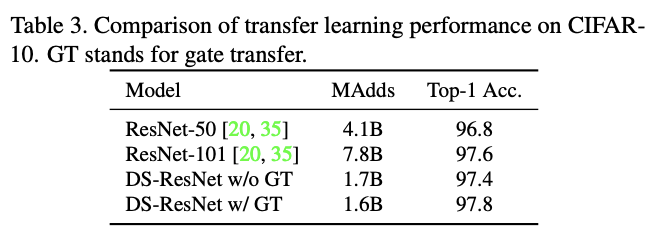
CIFAR-10性能对比。

VOC检测性能对比。

对IEB训练方法各模块进行对比实验。
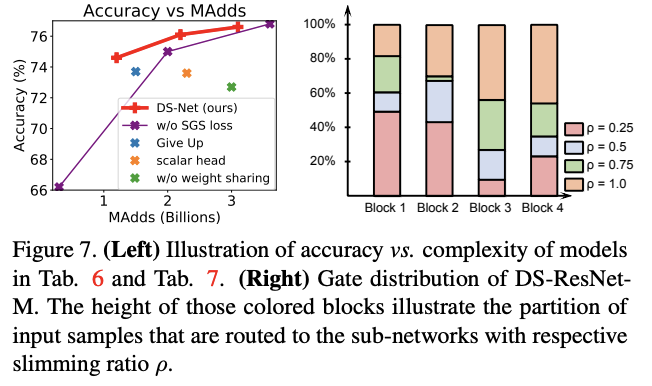
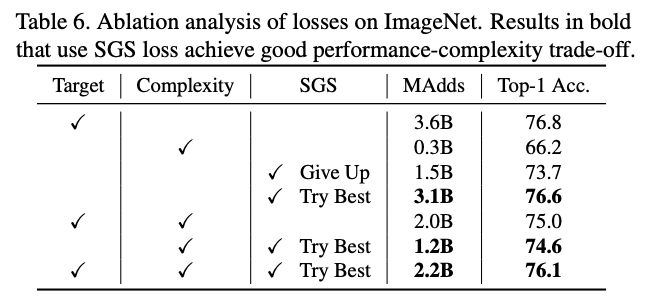
对比SGS损失与精简比例分布的可视化。
对比不同的SGS训练策略,Try Best为本文的策略,Give up为放弃hard samples,将其归类为最小精简网络的目标。

对比不同门控设计细节。
Conclusion
论文提出能够适配硬件加速的动态网络DS-Net,通过提出的double-headed动态门控来实现动态路由。基于论文提出的高性能网络设计和IEB、SGS训练策略,仅用1/2-1/4的计算量就能达到静态SOTA网络性能,实际加速也有1.62倍。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
