轻松复现一张AI图片
轻松复现一张AI图片
现在有一个非常漂亮的AI图片,你是不是想知道他是怎么生成的?
今天我会交给大家三种方法,学会了,什么图都可以手到擒来了。
需要的软件
在本教程中,我们将使用AUTOMATIC6666661 stable diffusion WebUI。这是一款流行且免费的软件。您可以在Windows、Mac或Google Colab上使用这个软件。
方法1: 通过阅读PNG信息从图像中获取提示
如果AI图像是PNG格式,你可以尝试查看提示和其他设置信息是否写在了PNG元数据字段中。
首先,将图像保存到本地。
打开AUTOMATIC6666661 WebUI。导航到
PNG信息
页面。
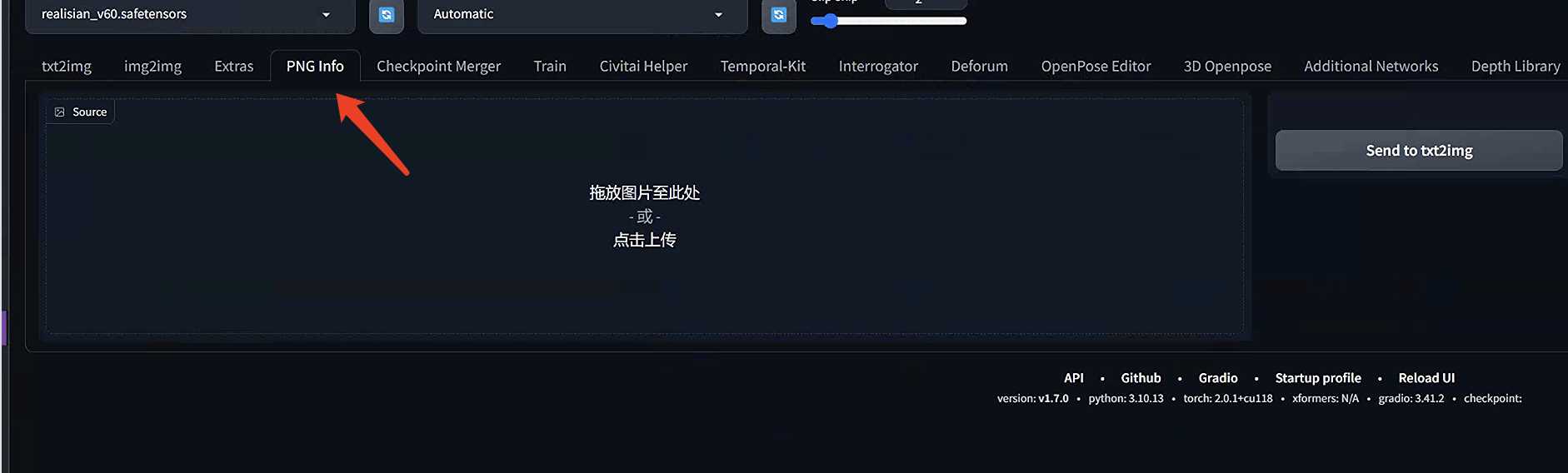
将图像拖放到左侧的
源
画布上。
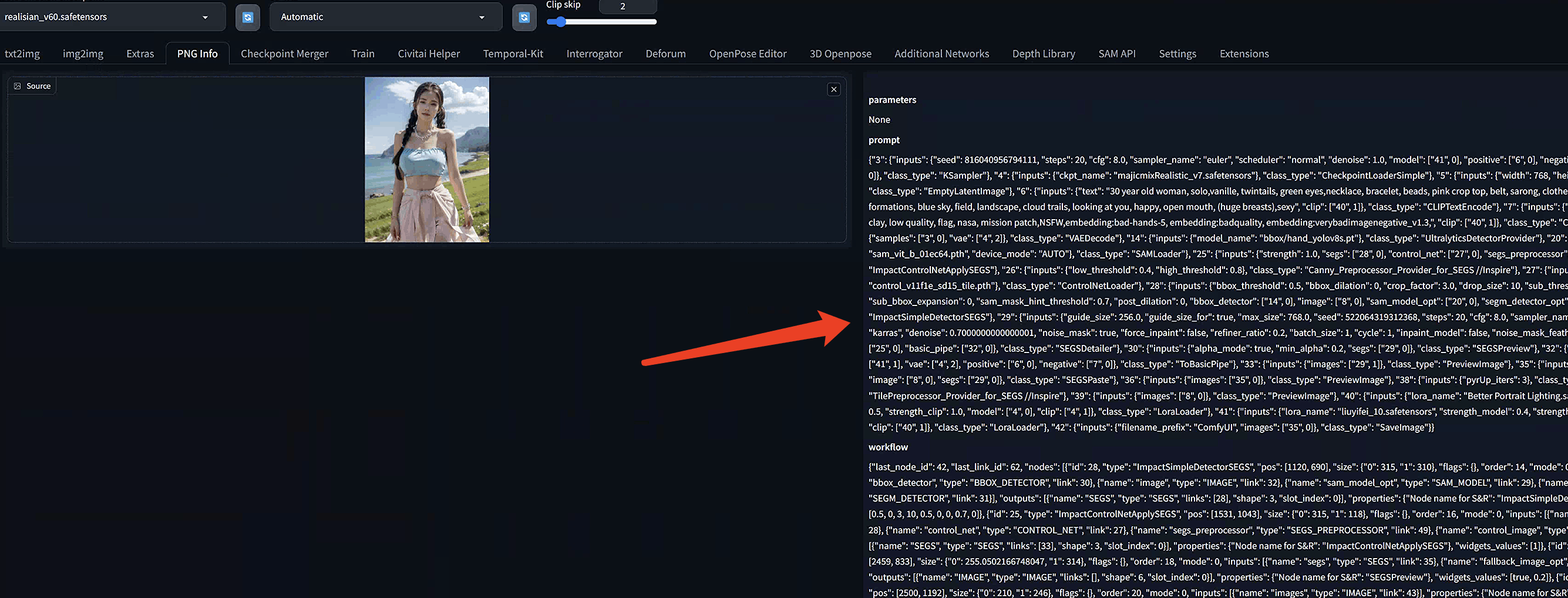
在右边你会找到关于提示词的有用信息。你还可以选择将提示和设置发送到txt2img、img2img、inpainting或者Extras页面进行放大。
方法2:使用CLIP interrogator从图像中推测Prompt
在处理图像信息时,我们常常会发现直接的方法并不总是有效。
有时候,信息并没有在最初就被记录在图像中,或者在后续的图像优化过程中被Web服务器去除。
也有可能这些信息并非由Stable diffusion这类AI技术生成。
面对这种情况,我们可以尝试使用CLIP interrogator作为替代方案。
CLIP interrogator是一种AI模型,它具备推测图像内容标题的能力。这个工具不仅适用于AI生成的图像,也能够应对各种类型的图像。通过这种方式,我们能够对图像内容进行更深入的理解和分析。
什么是CLIP?
CLIP(Contrastive Language–Image Pre-training)是一个神经网络,它将视觉概念映射到自然语言中。CLIP模型是通过大量的图像和图像信息对进行训练的。
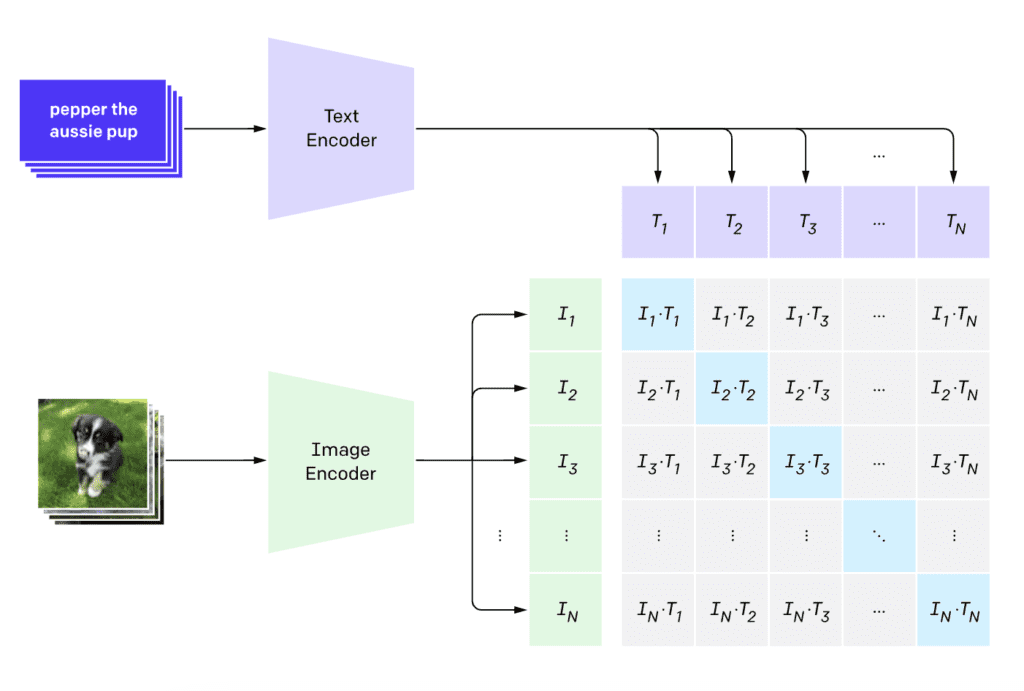
在我们的用例中,CLIP模型能够通过对给定图片的分析,推断出一个恰当的图片描述。
这个描述可以作为提示词,帮助我们进一步理解和描述图片的内容。CLIP模型通过学习大量的图像和相关文本数据,掌握了图像识别和语义理解的能力,因此它能够捕捉到图片中的关键元素,并将其转化为一个描述性的标题。
WebUI中自带的CLIP interrogator
如果你倾向于避免安装额外的扩展,可以选择使用AUTOMATIC6666661提供的内置CLIP interrogator功能。
WebUI提供了两种识别图像信息的功能。一个是clip:这个功能底层基于BLIP模型,它是在论文《BLIP: 为统一的视觉语言理解和生成进行语言图像预训练》中由李俊楠以及其团队所提出的CLIP模型的一个变种。一个是DeepBooru, 这个比较适合识别二次元图片。
要利用这个内置的CLIP interrogator,你可以按照以下简单的步骤操作:
启动AUTOMATIC6666661
:首先,你需要打开AUTOMATIC6666661的网站。导航至
img2img
页面:在AUTOMATIC6666661的界面中,找到并点击“img2img”这一选项。这是一个专门的页面,用于上传和处理图像。上传图像到
img2img
画布:在这个页面上,你会找到一个用于上传图像的区域,通常被称为“画布”。点击上传按钮,选择你想要分析的图像文件,并将其上传到画布上。上传之后在界面右边就可以找到两个interrogator工具了:
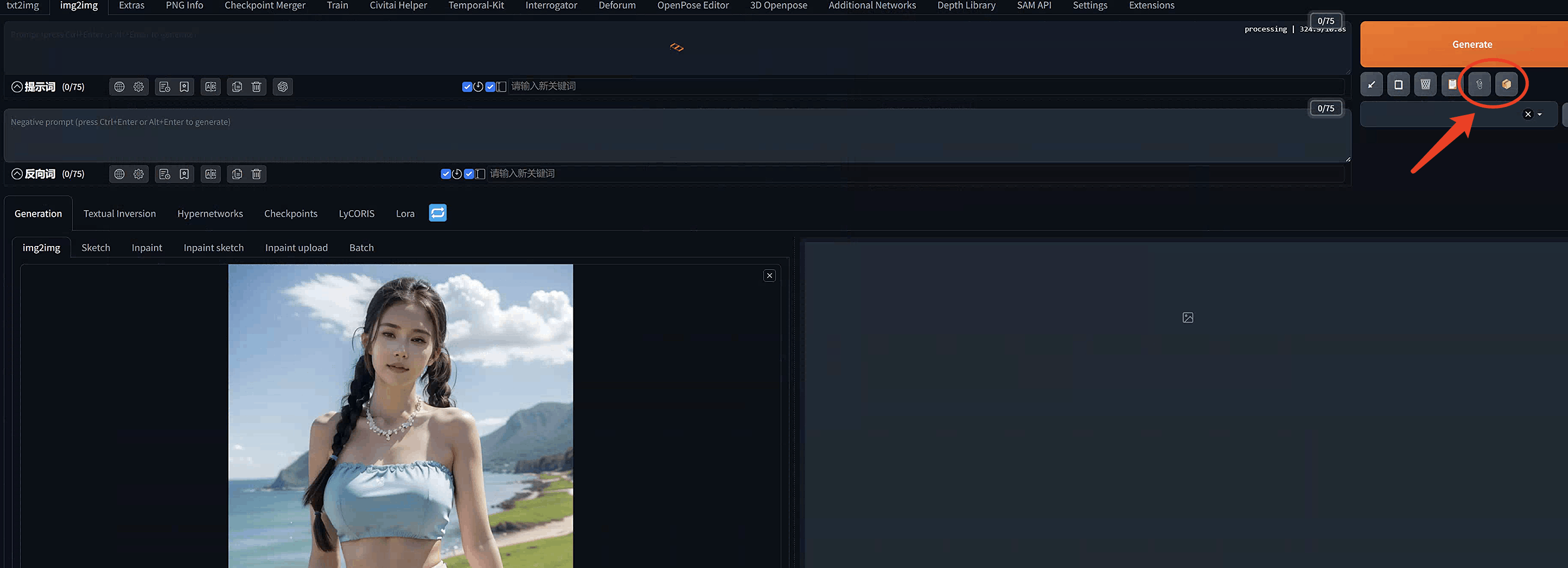
点击这两个按钮,就可以获得图像的描述信息了。
我们可以得到下面的信息:
a woman in a blue top and pink skirt standing on a hill near the ocean with a grassy area in the background,Ai Xuan,ocean,a statue,rococo,
我们用这段提示发到text2image中看看效果:

嗯....大体上还是有点相似的..... 因为图片跟我们的底模,种子还有采样多种因素有关。所以你想1比1复制,这个比较难。
CLIP扩展
如果您在使用AUTOMATIC6666661的内置CLIP interrogator时发现其功能不足以满足您的需求,或者您希望尝试使用不同的CLIP模型来获得更多样化的结果,那么您可以考虑安装CLIP interrogator扩展。这个扩展将为您提供更多的选项和灵活性,以适应您特定的使用场景。
这个插件的下载地址如下:
https://github.com/pharmapsychotic/clip-interrogator-ext
要使用CLIP interrogator扩展。
打开AUTOMATIC6666661 WebUI。
转到interrogator页面。
将图像上传到
图像
画布。在
CLIP模型
下拉菜单中选择
ViT-L-14-336/openai
。这是Stable Diffusion v1.5中使用的语言嵌入模型。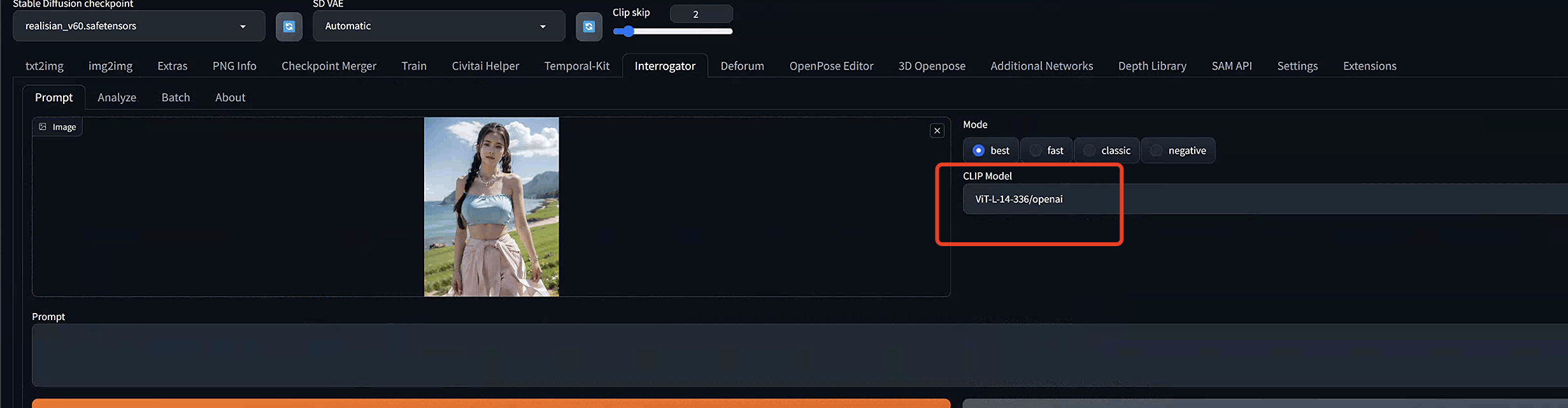
单击
生成
以生成提示。
对SDXL模型进行CLIP
如果你的目标是使用Stable Diffusion XL (SDXL)模型,那么我们需要选择不同的CLIP模型。
在“interrogator”页面上,你可以选择很多clip模型,如果要和SDXL模型一起工作的话,那么可以选择
ViT-g-14/laion2b_s34b_b88k
这个选项。
选择
ViT-g-14/laion2b_s34b_b88k
模型后,系统将会根据这个模型的特性生成相应的提示。你可以使用这个提示词作为SDXL的提示,从而可以更精确地生成与原始图像内容相符合的图像。
ViT-g-14/laion2b_s34b_b88k模型是一个基于Vision Transformer (ViT)架构的预训练模型,它在大型图像数据集laion2b上进行了训练,具有34亿个参数。这个模型在图像识别和理解方面表现出色,能够有效地捕捉图像的关键特征,并生成与原始图像内容紧密相关的提示。
通过这种方式,就可以确保在使用SDXL模型进行图像生成时,所得到的输出图像能够更好地反映原始图像的意图和风格。
总结一下
我们讲了三种方法来从图片信息中提取出对应的Prompt。
你应该首先尝试使用PNG信息方法。这种方法的优势在于,如果图像中包含了完整的元数据,那么您可以一次性获取到包括提示、使用的模型、采样方法、采样步骤等在内的所有必要信息。这对于重新创建图像非常有帮助。
如果PNG没有信息可用,那么可以考虑使用BLIP和CLIP模型。对于v1.5模型来说,ViT-g-14/laion2b_s34b_b88k模型可能是一个不错的选择,它不仅适用于SDXL模型,也可能在v1.5模型中表现出色。
另外,我们在构建提示词的时候,不要害怕对提示词进行修改。因为自动生成的提示可能并不完全准确,或者可能遗漏了一些图像中的关键对象。
所以需要根据自己的观察和需求,来修改提示词以确保它能准确地描述图像内容。这对于最终生成的图像质量和准确性至关重要。
同时,选择正确的checkpoint模型也非常关键。因为提示中可能并不总是包含正确的风格信息。
例如,如果您的目标是生成一个真实人物图像,那么你肯定不能选择一个卡通模型。