k8s集群搭建及对一些组件的简单理解(二)
背景
前面写了一篇,k8s集群搭建及对一些组件的简单理解(一),主要讲了下背景和对一些组件的理解。
今天讲一下正式的安装,有网环境的,后续再说下无外网环境纯内网的。
k8s集群节点、组件
控制面节点,一般就是部署了如下组件:etcd、apiserver、kube-scheduler、kube-controller-manager,由于这些组件都是面向用户,通过kubectl或者UI来接收用户的请求,并对用户请求做出响应。
这些组件收到请求后,开始处理请求,如用户希望运行pod,则这些组件会寻找某个合适的node来部署pod,因此,实际运行用户pod的节点,一般认为是数据面节点。
这些概念可参考:
https://kubernetes.io/docs/concepts/overview/components/
控制面中的组件,理论上是可以分布在任意node,但是安装脚本一般选择将这些组件安装在同一台机器上,并且不在这些机器上运行用户的pod;为了高可用,还会在多台机器上来部署这些控制面组件,因此,我们可以把这些机器叫做控制面节点。
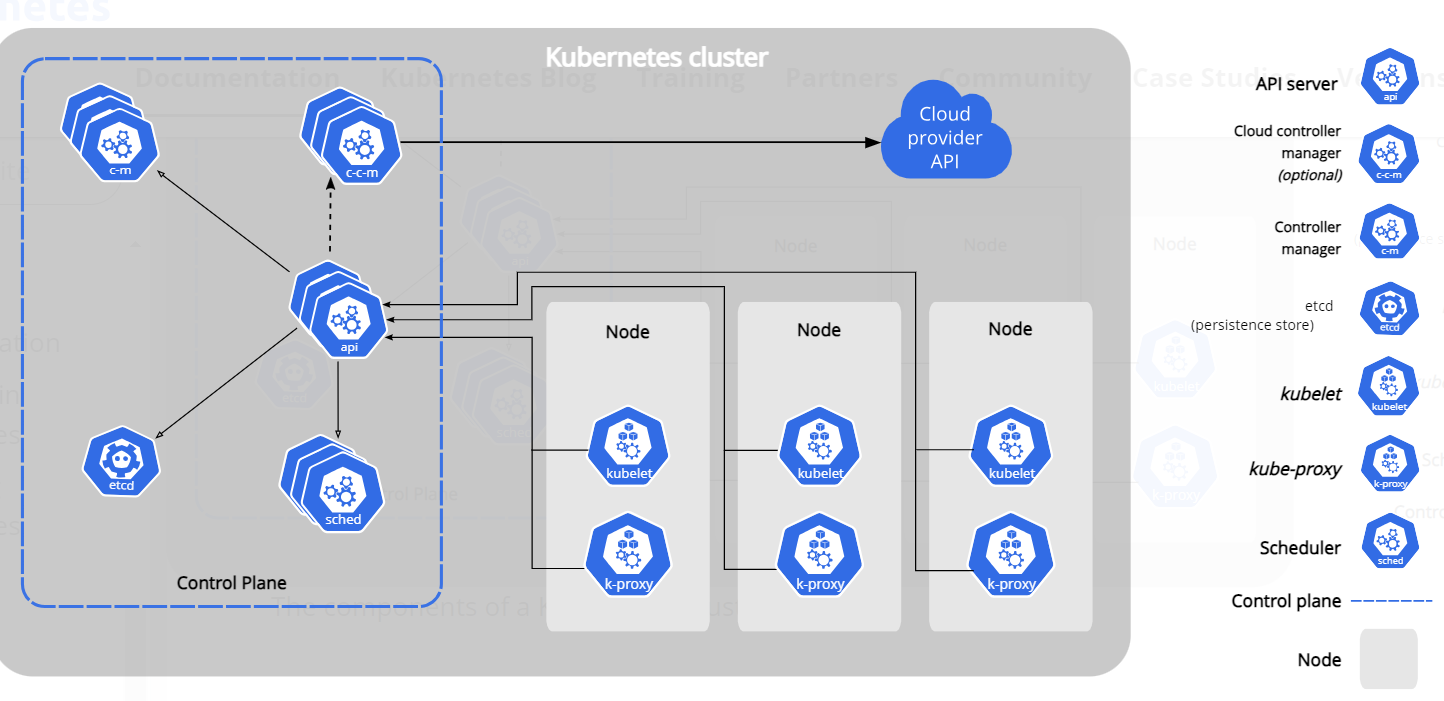
上图可以看出,控制面节点中只包含了api-server/etcd/kube-scheduler等组件,实际上,控制面并没有强制说一定不能运行用户pod,而且,在我们使用kubeadm搭建集群时,一般控制面节点会同时包含控制面组件和数据面节点的组件(kubelet、kube-proxy、容器运行时等)。
下面是我整理的图,利用kubeadm搭建完控制面节点后,里面包含了:
6个pod(4个绿色部分的:etcd、api-server、scheduler、control-manager;2个灰色部分:coredns、kube-proxy),这些pod可以理解为6个后台进程
3个由systemctl管理的service:
/usr/lib/systemd/system/kubelet.service
/usr/lib/systemd/system/cri-docker.service
/usr/lib/systemd/system/docker.service
这3个service,也可以理解为3个后台进程,只是不是pod容器方式运行的;
这3个service,也变相地提供了3个二进制文件给我们用:kubelet、cri-docker、dokcer
2个cli:kubectl和kubeadm,这两个不是后台进程,只是单纯的cli客户端
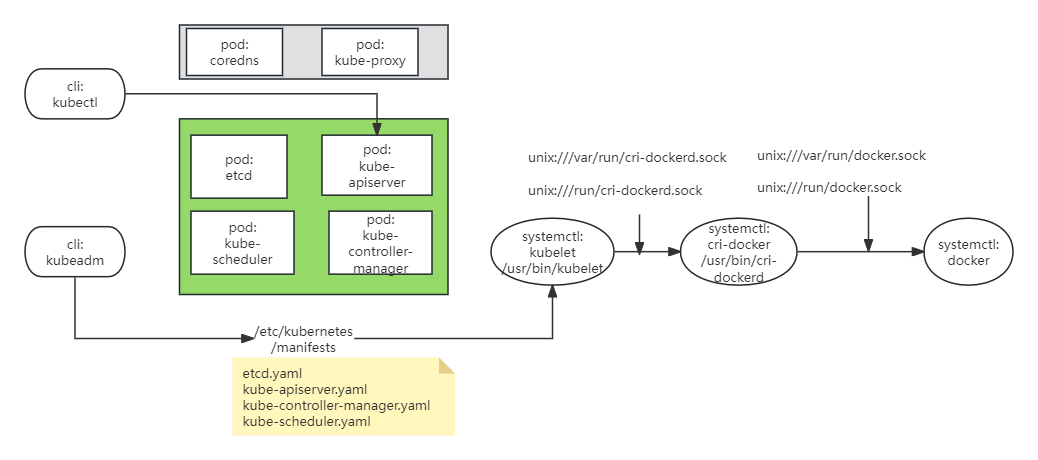
第一次装的时候,面对这近10个进程、几个cli,几个cli名字还像,真是有点晕。搞了几次后,稍微清晰点了,下面就正式开始安装的部署。
我们的机器配置:
virtualbox搞了两个干净的虚拟机,里面啥都没安装,但是有外网。
10.0.2.8 node4,准备作为主节点
10.0.2.9 node5,准备作为工作节点
操作系统都是centos 7.9。
容器运行时
参考文档:
https://kubernetes.io/docs/setup/production-environment/container-runtimes/
这里选择docker,这个个人用习惯了,空了再学其他的吧。
前置条件
- ip转发
文档里提到,linux默认未开启ip转发,而k8s的很多网络插件都需要这个特性,所以需要打开。
By default, the Linux kernel does not allow IPv4 packets to be routed between interfaces. Most Kubernetes cluster networking implementations will change this setting (if needed)
# sysctl params required by setup, params persist across reboots
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward = 1
EOF
# Apply sysctl params without reboot
sudo sysctl --system
检查是否已经设为1:
sysctl net.ipv4.ip_forward
- cgroup drivers
https://kubernetes.io/docs/setup/production-environment/container-runtimes/
在linux中,control group用于对进程可以使用的资源进行限制。而kubelet和容器运行时,都需要和control group打交道,对pod和容器的资源进行管理、对其可以使用的cpu、内存等资源进行限制。要和control group打交道,也不是直接打交道,而是要通过一个control group driver,感觉可以理解为驱动。很重要的一点是,容器运行时和kubelet,需要保证使用同样的cgroup driver。
目前有两种cgroup driver:cgroupfs、systemd。
cgroupfs是kubelet中默认的driver,fs表示文件系统file system的意思,它是 cgroup 的文件系统接口,用户可以操作对应的文件来进行资源控制。
默认的目录为:/sys/fs/cgroup。我们系统下:
[root@node4 ~]# ll /sys/fs/cgroup
total 0
drwxr-xr-x. 2 root root 0 Jun 23 12:53 blkio
lrwxrwxrwx. 1 root root 11 Jun 23 12:53 cpu -> cpu,cpuacct
lrwxrwxrwx. 1 root root 11 Jun 23 12:53 cpuacct -> cpu,cpuacct
drwxr-xr-x. 2 root root 0 Jun 23 12:53 cpu,cpuacct
drwxr-xr-x. 2 root root 0 Jun 23 12:53 cpuset
drwxr-xr-x. 4 root root 0 Jun 23 12:53 devices
drwxr-xr-x. 2 root root 0 Jun 23 12:53 freezer
drwxr-xr-x. 2 root root 0 Jun 23 12:53 hugetlb
drwxr-xr-x. 2 root root 0 Jun 23 12:53 memory
lrwxrwxrwx. 1 root root 16 Jun 23 12:53 net_cls -> net_cls,net_prio
drwxr-xr-x. 2 root root 0 Jun 23 12:53 net_cls,net_prio
lrwxrwxrwx. 1 root root 16 Jun 23 12:53 net_prio -> net_cls,net_prio
drwxr-xr-x. 2 root root 0 Jun 23 12:53 perf_event
drwxr-xr-x. 2 root root 0 Jun 23 12:53 pids
drwxr-xr-x. 4 root root 0 Jun 23 12:53 systemd
总之,简单理解,这种driver是直接操作这个目录下的文件来和内核中的control group交互,比如可以在这边创建一个group,然后把某些进程的pid加入,这样,这些pid就会应用这个group的资源限制配置。
但是,在systemd管理的系统中(比如centos 7基本就是systemd管理的),就不推荐使用这种cgroupfs驱动了。
因为,在这种系统中,systemd会为每一个unit配置一个control group,比如:
https://serverfault.com/questions/683911/use-of-cpuquota-in-systemd
[Unit]
Description=Virtual Distributed Ethernet
[Service]
ExecStart=/usr/bin/ddcommand
CPUQuota=10%
[Install]
WantedBy=multi-user.target
这里面就通过CPUQuota限制了可以使用的cpu为10%。
关于systemd的资源限制这块,可以查看:
man systemd.resource-control
因此,在这种systemd系统中,就得统一都使用systemd这种cgroup driver。
后面再说说具体怎么设置。
docker 安装
我们准备采用yum安装,这种安装之后,rpm包就找不到了,由于我们需要把rpm包保存下来供后面搭建内网k8s,所以我们就先把rpm包下载下来再手动安装。
参考文档:
https://docs.docker.com/engine/install/centos/
在yum安装前,得先安装docker的yum仓库,否则,你直接yum安装的话,可能版本会非常老。比如,在centos 7.9中:
[root@node4 ~]# yum info docker
Available Packages
Name : docker
Arch : x86_64
Epoch : 2
Version : 1.13.1
Release : 210.git7d71120.el7.centos
Size : 17 M
Repo : extras/7/x86_64
这个就是1.13.1,该版本是2017年的:
https://docs.docker.com/engine/release-notes/prior-releases/
后来改成了17.03这样的格式(一开始说是YY.MM格式,现在也不是很遵从了),最近几年的几个版本是23.0/24.0/25.0/26.0,目前最新是26.1。
所以,要安装新版本,先弄一下docker的yum仓库。
官方是这个,但是被q了:
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
那就搞个镜像,如果大家使用云服务器的话,可以找找自己云厂商提供的docker镜像,有的是只给自己的云服务器用的,这种一般速度比较快:
wget -O /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
下载rpm包:
[root@node4 ~]# mkdir /root/docker-package
[root@node4 ~]# cd /root/docker-package/
[root@node4 docker-package]# yumdownloader --resolve --destdir=. docker-ce docker-ce-cli containerd.io
我们没安装docker-buildx-plugin docker-compose-plugin,暂时感觉用不上。
下载完成后,查看:
[root@node4 docker-package]# ll
total 118488
-rw-r--r--. 1 root root 78256 Aug 23 2019 audit-libs-python-2.8.5-4.el7.x86_64.rpm
-rw-r--r--. 1 root root 302068 Nov 12 2018 checkpolicy-2.5-8.el7.x86_64.rpm
-rw-r--r--. 1 root root 37045876 Jun 21 18:38 containerd.io-1.6.33-3.1.el7.x86_64.rpm
...
使用rpm包安装:
rpm -ivh *.rpm
安装完成后,会有多个systemd管理的unit:
cd /usr/lib/systemd/system
ll
-rw-r--r-- 1 root root 1264 Jun 5 16:36 containerd.service
-rw-r--r-- 1 root root 295 Jun 5 19:31 docker.socket
-rw-r--r-- 1 root root 1962 Jun 5 19:31 docker.service
然后就是设置下docker的配置文件(没有就新建):
[root@app1 ~]# vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"debug": true
}
如果需要配私服、镜像的,也基本就是改这个文件,比如增加如下行,我就先不加了:
"registry-mirrors": ["http://10.0.218.xxx:8083"],
"insecure-registries": ["http://10.0.218.xxx:8083"]
启动服务:
systemctl start docker
systemctl status docker
开机启动:
systemctl enable docker
检查是否cgroup driver为systemd:
[root@app1 cri-docker]# docker info|grep group
Cgroup Driver: systemd
Cgroup Version: 1
检查下能拉不:
[root@node4 docker-package]# docker pull hello-world
Using default tag: latest
latest: Pulling from library/hello-world
c1ec31eb5944: Retrying in 1 second
error pulling image configuration: download failed after attempts=6: dial tcp 103.252.114.61:443: i/o timeout
拉不下来,也可以查看下日志:
journalctl -u docker
实时查看:
journalctl -u docker -f
嗯,不能。。。因为docker pull的时候要去访问一些网站
https://production.cloudflare.docker.com
,被q了。
那如果不学上网技术,就只能使用docker.io这个官方仓库的国内镜像仓库了。
我一开始看到网上总结的几个镜像站:
| docker.io | mirror.ccs.tencentyun.com | 仅腾讯云vpc内部访问, registry2 proxy |
|---|---|---|
| docker.nju.edu.cn | 南京大学开源镜像站, nexus3 | |
| docker.mirrors.sjtug.sjtu.edu.cn | 上海交通大学, registry2 proxy | |
| docker.m.daocloud.io | 国内可用, 带宽低 | |
| *****.mirror.aliyuncs.com | 国内可用,更新慢 |
除了腾讯是内部用(云服务器上可以用),其他的,除了倒数第二个,其他的几个全用不了了。(当前时间20240623)。
docker pull docker.m.daocloud.io/hello-world
[root@node4 docker-package]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.m.daocloud.io/hello-world latest d2c94e258dcb 13 months ago 13.3kB
另外,可以关注下docker对外部提供的接口,为domain unix socket:
[root@node4 docker-package]# netstat -nlp |grep docker
unix 2 [ ACC ] STREAM LISTENING 40562 1/systemd /run/docker.sock
cri-docker 安装
https://mirantis.github.io/cri-dockerd/
cri-docker是docker公司和Mirantis 公司(docker商业化公司)来维护,实现了k8s的CRI接口,将CRI接口进行适配,转换为对docker的调用并响应。
安装的话,最简单就是安装rpm包 ,
https://github.com/Mirantis/cri-dockerd/releases这里下载即可。
我这边下载的是cri-dockerd-0.3.14-3.el7.x86_64.rpm。
cd /root/upload
上传rpm
rpm -ivh cri-dockerd-0.3.14-3.el7.x86_64.rpm
安装完成后,会有如下service:
/usr/lib/systemd/system/cri-docker.service
查看内容,主要命令就是:
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd://
查看帮助:
/usr/bin/cri-dockerd -h
这个里面选项不少,要多看看。
比如这里就可以指定docker的socket的地址:
--docker-endpoint string Use this for the docker endpoint to communicate with.
(default "unix:///var/run/docker.sock")
还可以指定pod中的基础容器的镜像坐标:
--pod-infra-container-image string The image whose network/ipc namespaces containers in each pod will use (default "registry.k8s.io/pause:3.9")
启动:
[root@node4 upload]# systemctl start cri-docker
[root@node4 upload]# systemctl status cri-docker
它监听的端口为/run/cri-dockerd.sock或者/var/run/cri-dockerd.sock,这两个指向同一个文件:
[root@node4 upload]# netstat -nlxp|grep cri
unix 2 [ ACC ] STREAM LISTENING 68693 1/systemd /run/cri-dockerd.sock
日志查看:
journalctl -u cri-docker
kubelet安装
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
前置
关闭SeLinux:
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
关闭swap:
sudo vi /etc/fstab
注释掉如下行:
# /dev/mapper/centos-swap swap swap defaults 0 0
[root@app1 ~]# sudo swapoff -a
检查:
[root@app1 ~]# free -h
安装kubelet
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.30/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.30/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni
EOF
然后,首先安装kubelet:
rpm安装:
mkdir /root/kubelet-kubeadm
cd /root/kubelet-kubeadm
yumdownloader --resolve --destdir=. kubelet --disableexcludes=kubernetes
rpm -ivh *.rpm
如果直接装就是:
yum install kubelet --disableexcludes=kubernetes
可以观察到,其依赖于:kubernetes-cni这个包。
/usr/lib/systemd/system/kubelet.service
systemctl status kubelet
cd /usr/lib/systemd/system/
[root@node4 system]# ll kubelet*
-rw-r--r--. 1 root root 278 Jun 12 05:15 kubelet.service
我们如果此时启动,大家看看效果:
systemctl start kubelet
systemctl enable kubelet
systemctl status kubelet
是启动失败的。
查看日志:
journalctl -u kubelet

可以发现,此时进入的是standalone模式,这个模式下,kubelet可以独立管理pod,不需要api-server的存在,具体大家可以搜一下。
安装kubeadm
rpm安装:
cd /root/kubelet-kubeadm
yumdownloader --resolve --destdir=. kubeadm --disableexcludes=kubernetes
rpm -ivh *.rpm
如果直接装就是:
yum install kubeadm --disableexcludes=kubernetes
发现其会依赖cri-tools
对kubelet的影响
安装完成后,我们再去看kubelet的service目录下:
cd /usr/lib/systemd/system/
[root@node4 system]# ll kubelet*
-rw-r--r--. 1 root root 278 Jun 12 05:15 kubelet.service
kubelet.service.d:
total 4
-rw-r--r--. 1 root root 900 Jun 12 05:14 10-kubeadm.conf
发现多了个目录,目录下还有配置文件10-kubeadm.conf. 这个配置文件其实就是给kubelet指定了些配置,比如后续怎么去连接api-server(就不在是standalone模式了)、以及指定了一些kubelet自身的配置项
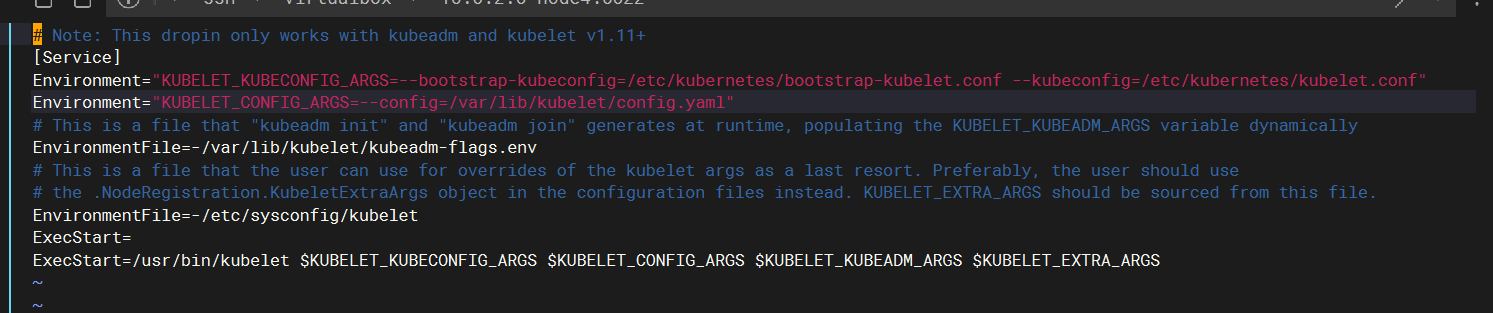
另外,也可以查看下kubelet的选项,非常多:
[root@node4 system]# /usr/bin/kubelet -h
kubeadm的流程
此时,其实就可以准备创建集群了。语法很简单:
kubeadm init --pod-network-cidr=192.168.0.0/16 --cri-socket unix:///var/run/cri-dockerd.sock --kubernetes-version v1.30.1 --v=5
具体选项可以看:
kubeadm init -h
我们指定的选项的意思:
--pod-network-cidr,这个是部分cni插件需要指定,我们选的是calico,去calico官网查看文档,发现其默认需要这么指定:192.168.0.0/16,意思就是pod的ip的网段
--cri-socket,这个是因为我们机器上,既有cri-docker,又有containerd,两个cri实现,必须手动指定一个。
--kubernetes-version v1.30.1,联网环境下可以不指定,就是指定k8s的版本;离线环境下指定了就不用去联网发请求
--v,日志级别
但,实际这样还不够,k8s的控制面组件不是有好几个pod吗,pod内容器的镜像,是维护在registry.k8s.io这个仓库下的。
我们直接去拉取镜像会失败:
[root@node4 system]# docker pull registry.k8s.io/kube-apiserver:v1.30.1
Error response from daemon: Head "https://asia-east1-docker.pkg.dev/v2/k8s-artifacts-prod/images/kube-apiserver/manifests/v1.30.1": dial tcp: lookup asia-east1-docker.pkg.dev on 10.0.2.1:53: no such host
这些网址是由Google团队提供的,被q了。
所以,我们只能找找registry.k8s.io的镜像仓库,我这边用的registry-k8s-io.mirrors.sjtug.sjtu.edu.cn。
因此,最后命令是:
kubeadm init --image-repository registry-k8s-io.mirrors.sjtug.sjtu.edu.cn --pod-network-cidr=192.168.0.0/16 --cri-socket unix:///var/run/cri-dockerd.sock --kubernetes-version v1.30.1 --v=5
另外,我们加上--dry-run,先试着跑一下,但是,我建议,还是先提前拉取好镜像,再来跑这个好一点:
kubeadm init --image-repository registry-k8s-io.mirrors.sjtug.sjtu.edu.cn --pod-network-cidr=192.168.0.0/16 --cri-socket unix:///var/run/cri-dockerd.sock --kubernetes-version v1.30.1 --v=5 --dry-run
为啥呢,因为k8s这几个组件的镜像大小有大几百兆,所以界面会一直卡在这里,不知道后台到底怎么样了,是卡死了还是怎么了。
我们如果要提前拉取镜像,先得知道要拉取哪些镜像:
[root@node4 system]# kubeadm config images list
registry.k8s.io/kube-apiserver:v1.30.2
registry.k8s.io/kube-controller-manager:v1.30.2
registry.k8s.io/kube-scheduler:v1.30.2
registry.k8s.io/kube-proxy:v1.30.2
registry.k8s.io/coredns/coredns:v1.11.1
registry.k8s.io/pause:3.9
registry.k8s.io/etcd:3.5.12-0
然后,转换为:
docker pull registry-k8s-io.mirrors.sjtug.sjtu.edu.cn/kube-apiserver:v1.30.2
docker pull registry-k8s-io.mirrors.sjtug.sjtu.edu.cn/kube-controller-manager:v1.30.2
docker pull registry-k8s-io.mirrors.sjtug.sjtu.edu.cn/kube-scheduler:v1.30.2
docker pull registry-k8s-io.mirrors.sjtug.sjtu.edu.cn/kube-proxy:v1.30.2
docker pull registry-k8s-io.mirrors.sjtug.sjtu.edu.cn/coredns/coredns:v1.11.1
docker pull registry-k8s-io.mirrors.sjtug.sjtu.edu.cn/pause:3.9
docker pull registry-k8s-io.mirrors.sjtug.sjtu.edu.cn/etcd:3.5.12-0
docker images,确保镜像都存在了,再次运行:
发现会卡在一个拉取coreDns的地方,
pulling: registry-k8s-io.mirrors.sjtug.sjtu.edu.cn/coredns:v1.11.1
这个主要是两个仓库的标签打得有点不一样,我们就把我们已经存在的镜像,重新打个tag:
docker tag registry-k8s-io.mirrors.sjtug.sjtu.edu.cn/coredns/coredns:v1.11.1 registry-k8s-io.mirrors.sjtug.sjtu.edu.cn/coredns:v1.11.1
结果再次运行,发现还是卡:
[api-check] Waiting for a healthy API server. This can take up to 4m0s
检查了几个服务的日志,发现docker日志显示还在拉取:
...
registry.k8s.io/pause from https://registry.k8s.io
后面查了下,是因为就是我们忽略了一句kubeadm打印的提示:
W0623 16:26:12.928077 22235 checks.go:844] detected that the sandbox image "registry.k8s.io/pause:3.9" of the container runtime is inconsistent with that used by kubeadm.It is recommended to use "registry-k8s-io.mirrors.sjtug.sjtu.edu.cn/pause:3.9" as the CRI sandbox image.
我们在cri-docker那里,需要修改下镜像坐标。
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --pod-infra-container-image registry-k8s-io.mirrors.sjtug.sjtu.edu.cn/pause:3.9
systemctl daemon-reload
systemctl restart cri-docker
再次执行,又说一堆东西已经存在了。我们可以先reset下:
kubeadm reset -f --cri-socket unix:///var/run/cri-dockerd.sock
这次基本就能成功了,把最下面的命令存下来:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 10.0.2.x:6443 --token k3nmtk.kx1k6cbxbsuaqysd \
--discovery-token-ca-cert-hash sha256:9659ceb5bf342b1a9fa1ef1888a3ce26a1f9c881dbbf4bbadcbb62d5dcde37dd
安装kubectl
这个东西是啥呢,只是个cli,客户端工具,给我们用的,就像redis-cli和mysql命令行客户端一样,主要是和控制面组件中的api-server进行交互。
事实上,各个容器厂商都是做一套界面出来给用户用的,也是直接对接api-server。
这里我们安装下。
rpm安装:
cd /root/kubelet-kubeadm
yumdownloader --resolve --destdir=. kubectl --disableexcludes=kubernetes
rpm -ivh *.rpm
如果直接装就是:
yum install kubectl --disableexcludes=kubernetes
然后执行下:
[root@node4 system]# kubectl get pods -A
E0623 16:40:18.035470 25920 memcache.go:265] couldn't get current server API group list: Get "http://localhost:8080/api?timeout=32s": dial tcp [::1]:8080: connect: connection refused
因为还需要指定api-server的地址:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
再来:
[root@node4 system]# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-86c4446b65-6sr2p 0/1 Pending 0 7m13s
kube-system coredns-86c4446b65-n4xcl 0/1 Pending 0 7m13s
kube-system etcd-node4 1/1 Running 0 7m28s
kube-system kube-apiserver-node4 1/1 Running 0 7m28s
kube-system kube-controller-manager-node4 1/1 Running 0 7m28s
kube-system kube-proxy-rxxc9 1/1 Running 0 7m13s
kube-system kube-scheduler-node4 1/1 Running 0 7m28s
可以发现,coreDns这两个pod是pending状态。看一下这个pod的状态:发现是说没有可用的ready的node。
[root@node4 system]# kubectl get nodes -A
NAME STATUS ROLES AGE VERSION
node4 NotReady control-plane 13m v1.30.2
我们的node确实是NotReady。
[root@node4 system]# kubectl describe node node4
...
Ready False Sun, 23 Jun 2024 16:43:43 +0800 Sun, 23 Jun 2024 16:33:18 +0800 KubeletNotReady container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
里面可以看到,是因为cni网络插件尚未ready的原因。
安装网络插件calico
网络插件有好多种,主流用的也有好几种,各种的差别后面我们再讲,其中呢,calico算是一款优秀的网络插件。
https://docs.tigera.io/calico/latest/getting-started/kubernetes/quickstart
安装operator
wget https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/tigera-operator.yaml
执行:
k create -f tigera-operator.yaml
执行完后,会新增一个pod:
[root@node4 calico-install]# kubectl get pods -A |grep tigera
tigera-operator tigera-operator-5ddc799ffd-fqsps 0/1 ContainerCreating 0 49s
这里又涉及到拉取镜像,这次的镜像是在:
[root@node4 calico-install]# grep image tigera-operator.yaml |grep quay
image: quay.io/tigera/operator:v1.34.0
还好,这个quay.io/tigera/operator:v1.34.0直接网络可以拉取。。不需要镜像
运行网络插件相关pod
https://docs.tigera.io/calico/latest/getting-started/kubernetes/quickstart
wget https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/custom-resources.yaml
// 这个动作又要拉取镜像,有大几百兆
kubectl create -f custom-resources.yaml
我在我以前成功的机器上看了下,拉取了这些(版本不一定和最新一样):
[root@app1 ~]# docker images |grep calico
calico/typha v3.28.0 a9372c0f51b5 71.1MB
calico/kube-controllers v3.28.0 428d92b02253 79.1MB
calico/apiserver v3.28.0 6c07591fd1cf 97.9MB
calico/cni v3.28.0 107014d9f4c8 209MB
calico/node-driver-registrar v3.28.0 0f80feca743f 23.5MB
calico/csi v3.28.0 1a094aeaf152 18.3MB
calico/pod2daemon-flexvol v3.28.0 587b28ecfc62 13.4MB
calico/node v3.28.0 4e42b6f329bc 353MB
我看了下docker日志,发现又跑去docker.io这个官方仓库拉取calico镜像去了,这尼玛。还是得配个镜像仓库啊。
vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"debug": true,
"registry-mirrors": ["https://docker.m.daocloud.io"]
}
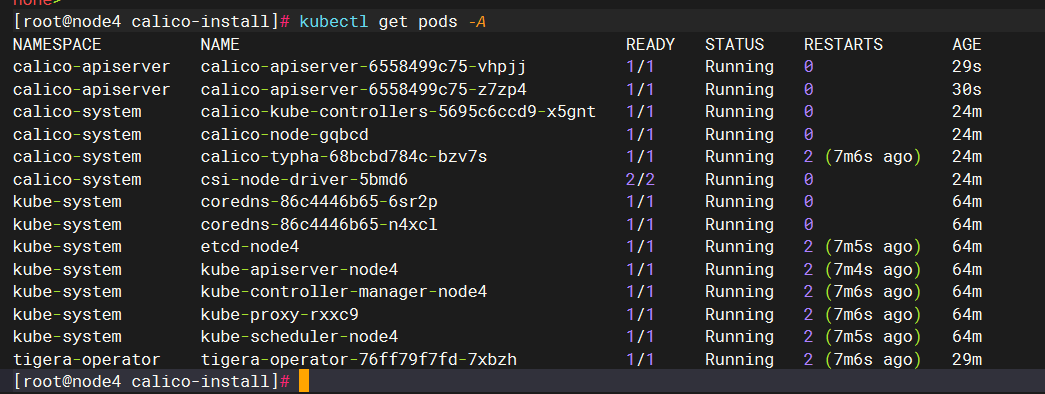
只要镜像下下来了,就没问题了,等一会,pod就会就绪,coreDns也会就绪:
worker节点安装
10.0.2.9 node5
容器运行时
参照主节点,全都需要执行。
rpm包我们scp拷贝过去。
scp * 10.0.2.9:/root/docker-package
scp /etc/docker/daemon.json 10.0.2.9:/etc/docker/daemon.json
systemctl start docker
systemctl status docker
systemctl enable docker
cri-docker安装
参照主节点。
记得修改service文件:
/usr/lib/systemd/system/cri-docker.service
加参数:
--pod-infra-container-image registry-k8s-io.mirrors.sjtug.sjtu.edu.cn/pause:3.9
systemctl start cri-docker
systemctl status cri-docker
systemctl enable cri-docker
kubelet安装
直接装,或者拿主节点的rpm来装:
yum install kubelet --disableexcludes=kubernetes
systemctl start kubelet
systemctl enable kubelet
kubeadm安装
直接装,或者拿主节点的rpm来装:
yum install kubeadm --disableexcludes=kubernetes
拷贝并加载镜像
从主节点中,执行:
[root@node4 docker-package]# docker save -o calico_images.tar $(docker images --format "{{.Repository}}:{{.Tag}}" | grep "^calico")
[root@node4 docker-package]# docker save -o pause.tar $(docker images --format "{{.Repository}}:{{.Tag}}" | grep "pause")
[root@node4 docker-package]# docker save -o kube-proxy.tar $(docker images --format "{{.Repository}}:{{.Tag}}" | grep "kube-proxy")
[root@node4 docker-package]# scp calico_images.tar pause.tar kube-proxy.tar 10.0.2.9:/root/images-for-load
在worker节点上:
cd /root/images-for-load
docker load < kube-proxy.tar
docker load < calico_images.tar
docker load < pause.tar
docker images
join集群
找出之前存下来的join语句:
kubeadm join 10.0.2.8:6443 --token k3nmtk.kx1k6cbxbsuaqysd \
--discovery-token-ca-cert-hash sha256:9659ceb5bf342b1a9fa1ef1888a3ce26a1f9c881dbbf4bbadcbb62d5dcde37dd --cri-socket unix:///var/run/cri-dockerd.sock --v=5
注意,worker节点不能执行kubectl是正常的,因为一般是在控制节点上执行kubectl。当然,如果有需要,也可以像主节点那样操作,弄一下就行了。
测试
我这边在主节点上:
kubectl create deploy www-nginx-demo --image nginx --replicas=2
如果发现调度到了两台机器上,等nginx镜像拉取完成后(在主、工作节点都要拉取),可以看到pod状态变成正常。

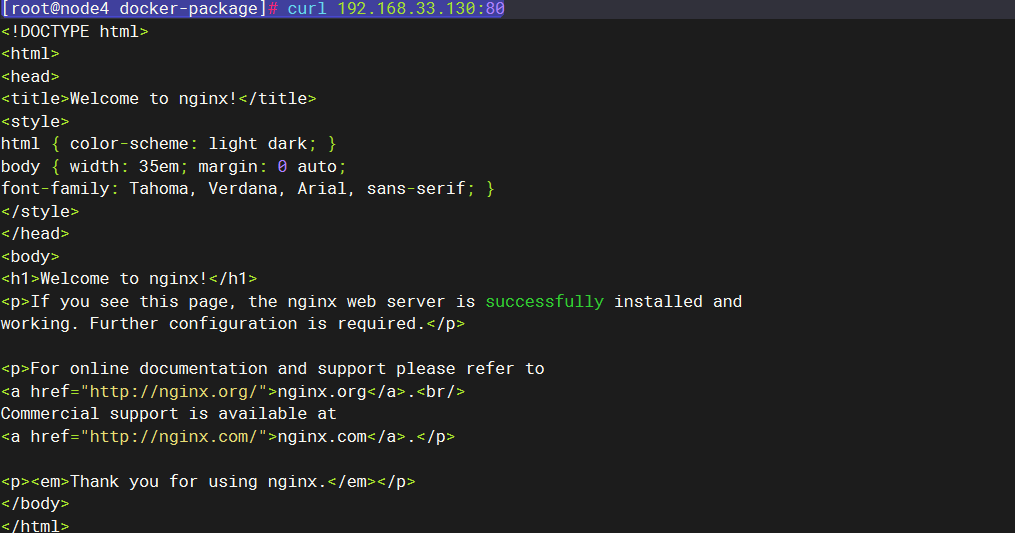
在主节点上,直接访问pod:
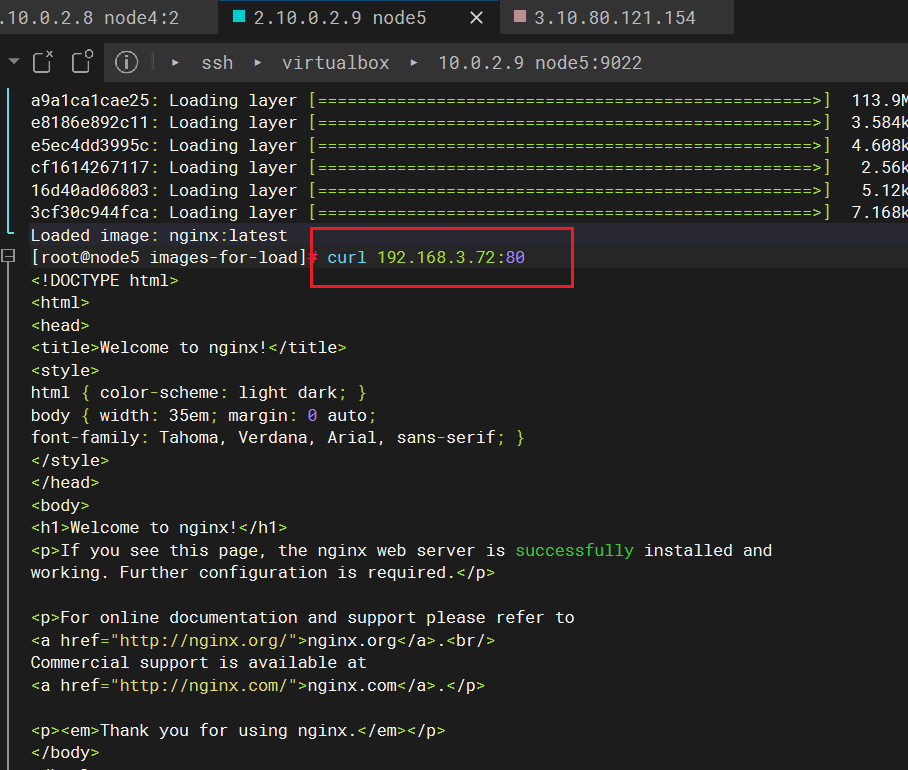
在工作节点上,直接访问pod:
容器到容器的网络也是通的,只是容器内太简单了,缺少ping这些基础的工具,以后再说说这块。
总结
后续再讲下完全没有网络的环境中的安装吧,也算是给自己备忘了。