SemanticKernel/C#:实现接口,接入本地嵌入模型
前言
本文通过Codeblaze.SemanticKernel这个项目,学习如何实现ITextEmbeddingGenerationService接口,接入本地嵌入模型。
项目地址:
https://github.com/BLaZeKiLL/Codeblaze.SemanticKernel
实践
SemanticKernel初看以为只支持OpenAI的各种模型,但其实也提供了强大的抽象能力,可以通过自己实现接口,来实现接入不兼容OpenAI格式的模型。
Codeblaze.SemanticKernel这个项目实现了ITextGenerationService、IChatCompletionService与ITextEmbeddingGenerationService接口,由于现在Ollama的对话已经支持了OpenAI格式,因此可以不用实现ITextGenerationService和IChatCompletionService来接入Ollama中的模型了,但目前Ollama的嵌入还没有兼容OpenAI的格式,因此可以通过实现ITextEmbeddingGenerationService接口,接入Ollama中的嵌入模型。
查看ITextEmbeddingGenerationService接口:

代表了一种生成浮点类型文本嵌入的生成器。
再看看IEmbeddingGenerationService<string, float>接口:
[Experimental("SKEXP0001")]
public interface IEmbeddingGenerationService<TValue, TEmbedding> : IAIService where TEmbedding : unmanaged
{
Task<IList<ReadOnlyMemory<TEmbedding>>> GenerateEmbeddingsAsync(IList<TValue> data, Kernel? kernel = null, CancellationToken cancellationToken = default(CancellationToken));
}再看看IAIService接口:

说明我们只要实现了
Task<IList<ReadOnlyMemory<TEmbedding>>> GenerateEmbeddingsAsync(IList<TValue> data, Kernel? kernel = null, CancellationToken cancellationToken = default(CancellationToken));
IReadOnlyDictionary<string, object?> Attributes { get; }这个方法和属性就行。
学习Codeblaze.SemanticKernel中是怎么做的。
添加OllamaBase类:
public interface IOllamaBase
{
Task PingOllamaAsync(CancellationToken cancellationToken = new());
}
public abstract class OllamaBase<T> : IOllamaBase where T : OllamaBase<T>
{
public IReadOnlyDictionary<string, object?> Attributes => _attributes;
private readonly Dictionary<string, object?> _attributes = new();
protected readonly HttpClient Http;
protected readonly ILogger<T> Logger;
protected OllamaBase(string modelId, string baseUrl, HttpClient http, ILoggerFactory? loggerFactory)
{
_attributes.Add("model_id", modelId);
_attributes.Add("base_url", baseUrl);
Http = http;
Logger = loggerFactory is not null ? loggerFactory.CreateLogger<T>() : NullLogger<T>.Instance;
}
/// <summary>
/// Ping Ollama instance to check if the required llm model is available at the instance
/// </summary>
/// <param name="cancellationToken"></param>
public async Task PingOllamaAsync(CancellationToken cancellationToken = new())
{
var data = new
{
name = Attributes["model_id"]
};
var response = await Http.PostAsJsonAsync($"{Attributes["base_url"]}/api/show", data, cancellationToken).ConfigureAwait(false);
ValidateOllamaResponse(response);
Logger.LogInformation("Connected to Ollama at {url} with model {model}", Attributes["base_url"], Attributes["model_id"]);
}
protected void ValidateOllamaResponse(HttpResponseMessage? response)
{
try
{
response.EnsureSuccessStatusCode();
}
catch (HttpRequestException)
{
Logger.LogError("Unable to connect to ollama at {url} with model {model}", Attributes["base_url"], Attributes["model_id"]);
}
}
}注意这个
public IReadOnlyDictionary<string, object?> Attributes => _attributes;实现了接口中的属性。
添加OllamaTextEmbeddingGeneration类:
#pragma warning disable SKEXP0001
public class OllamaTextEmbeddingGeneration(string modelId, string baseUrl, HttpClient http, ILoggerFactory? loggerFactory)
: OllamaBase<OllamaTextEmbeddingGeneration>(modelId, baseUrl, http, loggerFactory),
ITextEmbeddingGenerationService
{
public async Task<IList<ReadOnlyMemory<float>>> GenerateEmbeddingsAsync(IList<string> data, Kernel? kernel = null,
CancellationToken cancellationToken = new())
{
var result = new List<ReadOnlyMemory<float>>(data.Count);
foreach (var text in data)
{
var request = new
{
model = Attributes["model_id"],
prompt = text
};
var response = await Http.PostAsJsonAsync($"{Attributes["base_url"]}/api/embeddings", request, cancellationToken).ConfigureAwait(false);
ValidateOllamaResponse(response);
var json = JsonSerializer.Deserialize<JsonNode>(await response.Content.ReadAsStringAsync().ConfigureAwait(false));
var embedding = new ReadOnlyMemory<float>(json!["embedding"]?.AsArray().GetValues<float>().ToArray());
result.Add(embedding);
}
return result;
}
}注意实现了GenerateEmbeddingsAsync方法。实现的思路就是向Ollama中的嵌入接口发送请求,获得embedding数组。
为了在MemoryBuilder中能用还需要添加扩展方法:
#pragma warning disable SKEXP0001
public static class OllamaMemoryBuilderExtensions
{
/// <summary>
/// Adds Ollama as the text embedding generation backend for semantic memory
/// </summary>
/// <param name="builder">kernel builder</param>
/// <param name="modelId">Ollama model ID to use</param>
/// <param name="baseUrl">Ollama base url</param>
/// <returns></returns>
public static MemoryBuilder WithOllamaTextEmbeddingGeneration(
this MemoryBuilder builder,
string modelId,
string baseUrl
)
{
builder.WithTextEmbeddingGeneration((logger, http) => new OllamaTextEmbeddingGeneration(
modelId,
baseUrl,
http,
logger
));
return builder;
}
}开始使用
public async Task<ISemanticTextMemory> GetTextMemory3()
{
var builder = new MemoryBuilder();
var embeddingEndpoint = "http://localhost:11434";
var cancellationTokenSource = new System.Threading.CancellationTokenSource();
var cancellationToken = cancellationTokenSource.Token;
builder.WithHttpClient(new HttpClient());
builder.WithOllamaTextEmbeddingGeneration("mxbai-embed-large:335m", embeddingEndpoint);
IMemoryStore memoryStore = await SqliteMemoryStore.ConnectAsync("memstore.db");
builder.WithMemoryStore(memoryStore);
var textMemory = builder.Build();
return textMemory;
} builder.WithOllamaTextEmbeddingGeneration("mxbai-embed-large:335m", embeddingEndpoint);实现了WithOllamaTextEmbeddingGeneration这个扩展方法,因此可以这么写,使用的是mxbai-embed-large:335m这个向量模型。
我使用WPF简单做了个界面,来试试效果。
找了一个新闻嵌入:
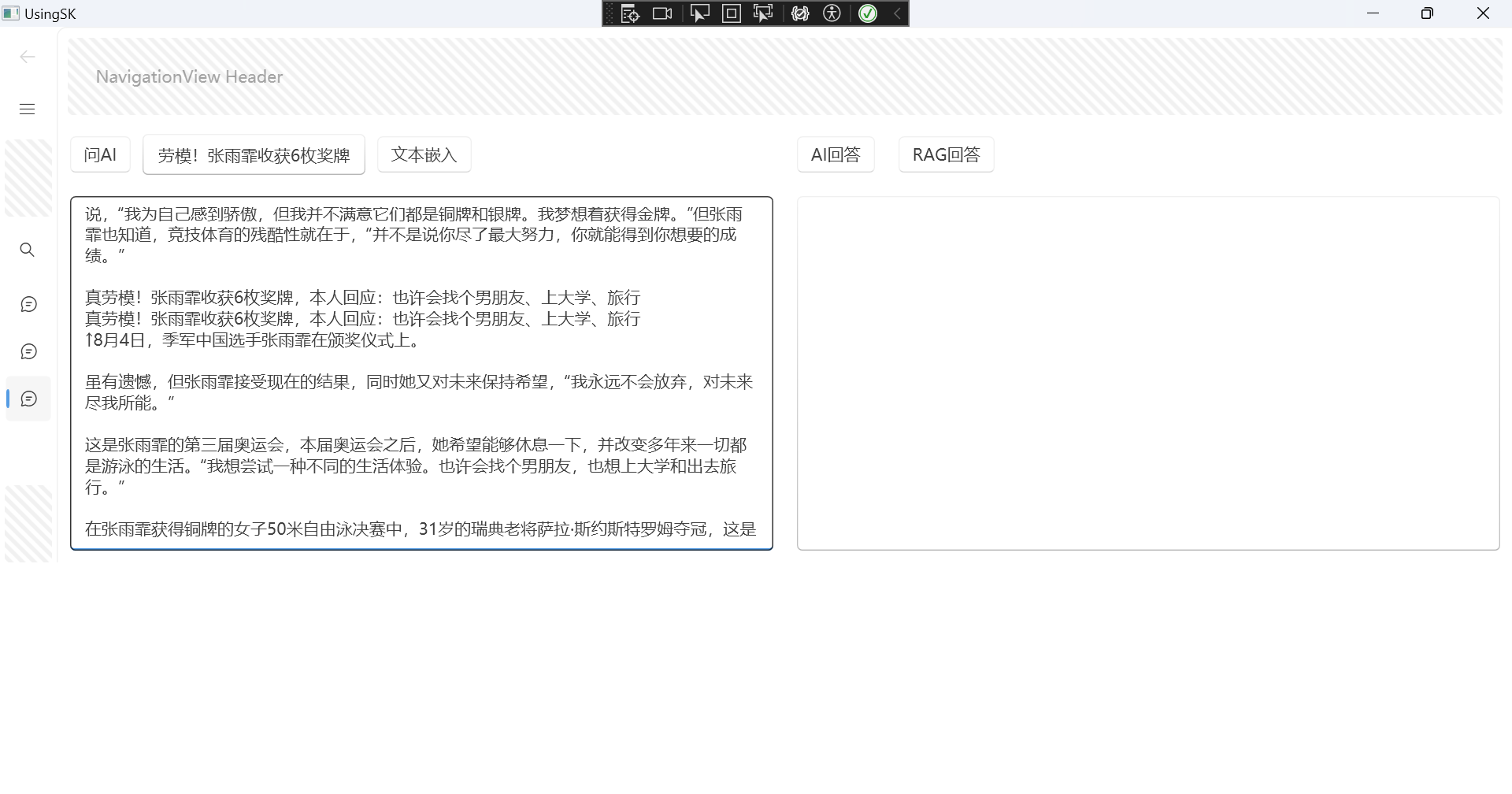
文本向量化存入数据库中:

现在测试RAG效果:
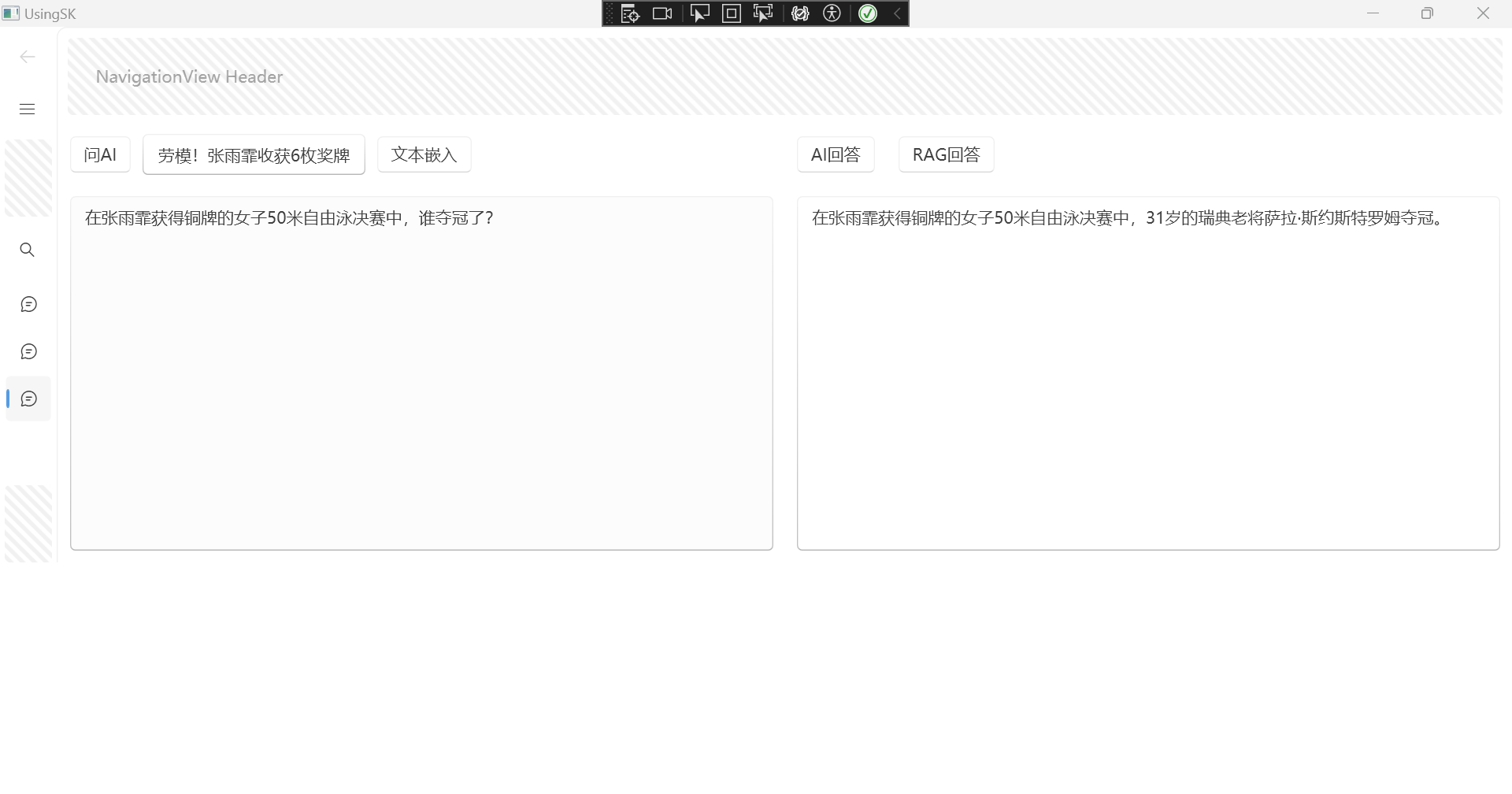
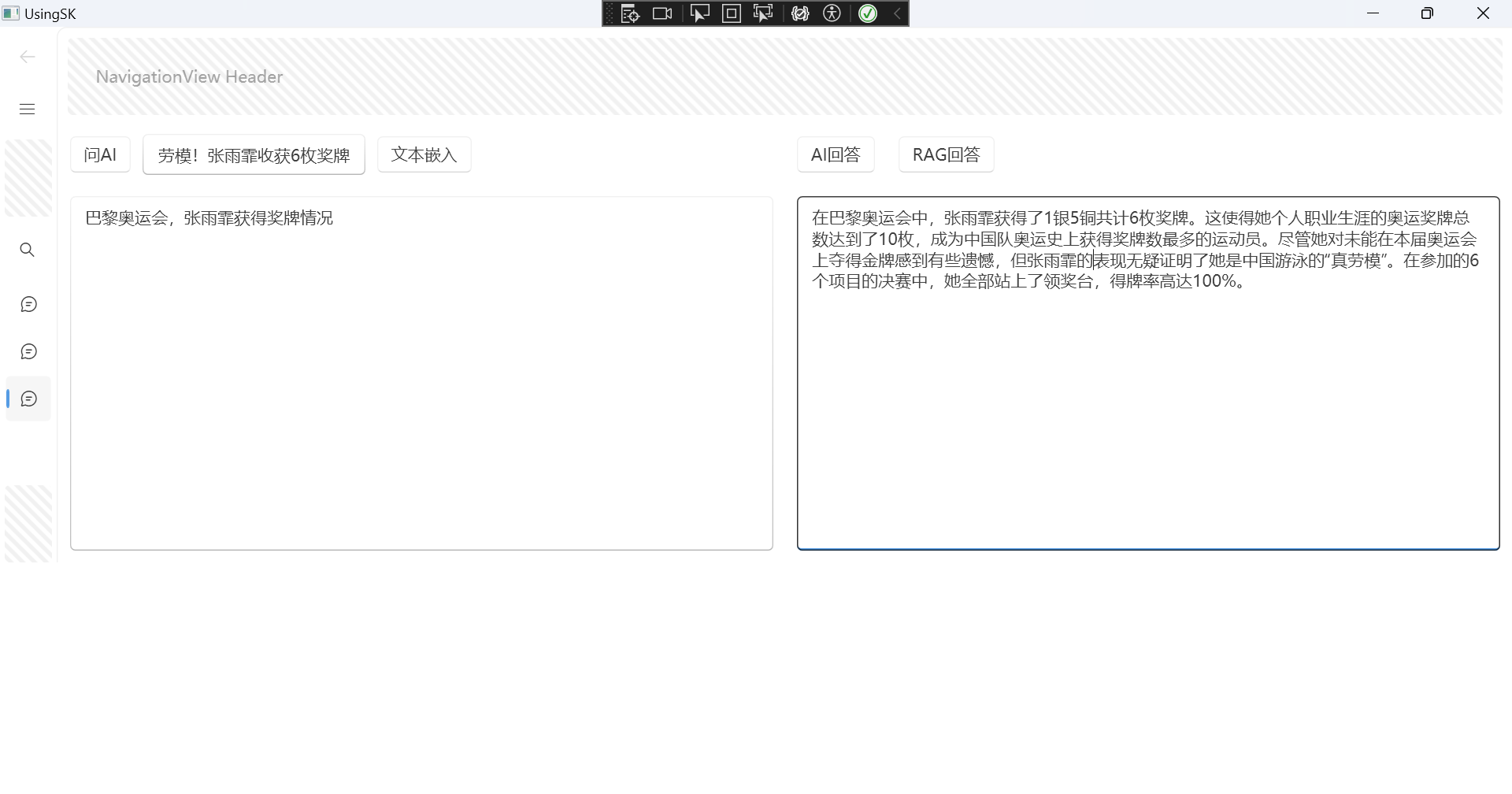
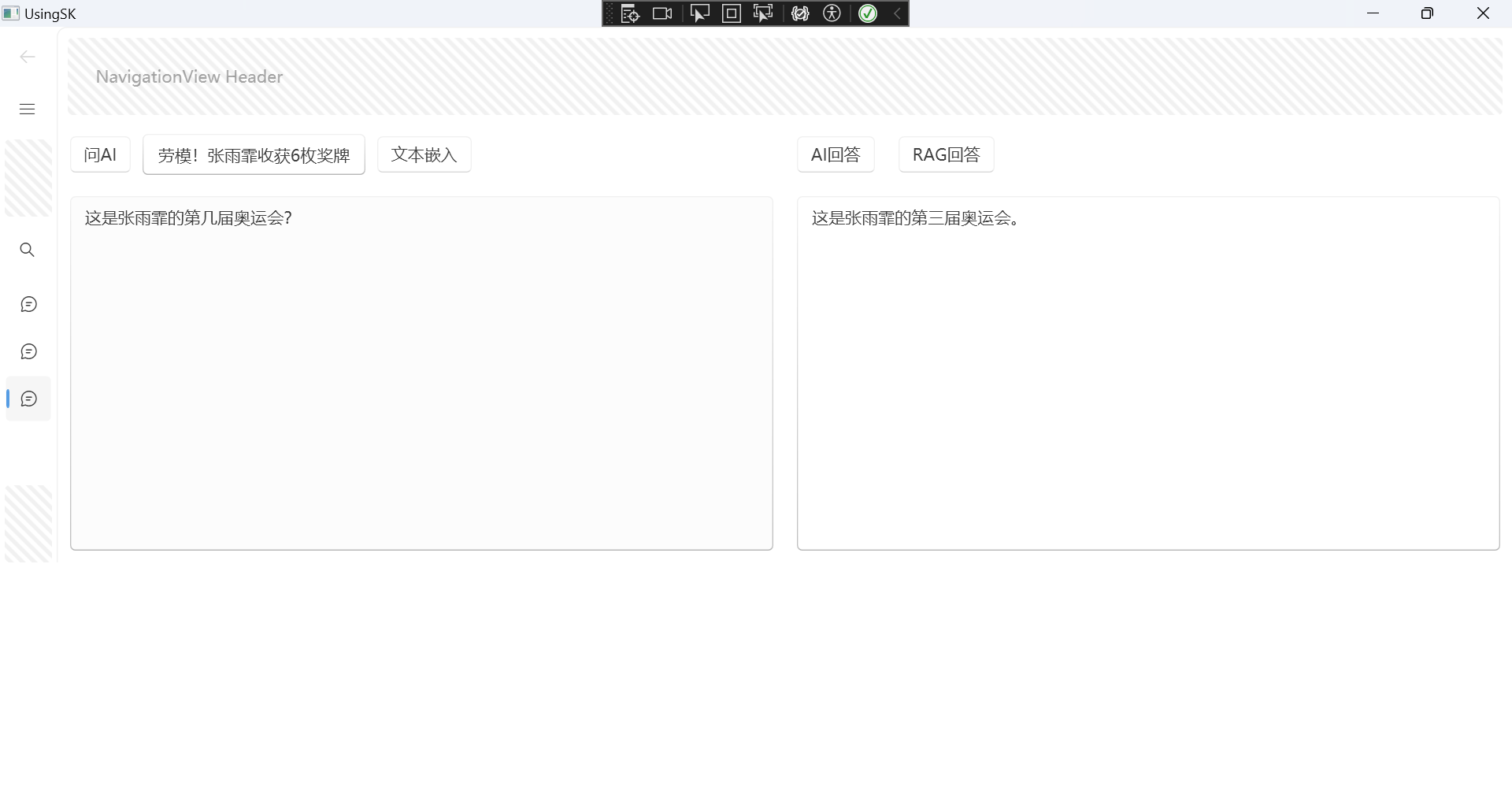
回答的效果也还可以。
大模型使用的是在线api的Qwen/Qwen2-72B-Instruct,嵌入模型使用的是本地Ollama中的mxbai-embed-large:335m。