flink同步MySQL数据的时候出现内存溢出
flink同步MySQL数据的时候出现内存溢出
背景:需要将1000w的某类型数据同步到别的数据源里面,使用公司的大数据平台可以很快处理完毕,而且使用的内存只有很少很少量(公司的大数据平台的底层是flink,但是连接器使用的是chunjun开源产品),由于我个人想使用flink原生的连接器来尝试一下,所以就模拟了1000w的数据,然后启动了flink单节点,通过flinksql的方式提交了同步任务,最终结果内存溢出!!!
下面的问题是在使用MySQL数据源的时候出现的,别的数据源可能不会有这个问题
下面是在main方法里面写的flink代码
import ch.qos.logback.classic.Level;
import ch.qos.logback.classic.Logger;
import ch.qos.logback.classic.LoggerContext;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.slf4j.LoggerFactory;
import java.util.List;
public class Main2 {
static {
LoggerContext loggerContext = (LoggerContext) LoggerFactory.getILoggerFactory();
List<Logger> loggerList = loggerContext.getLoggerList();
loggerList.forEach(logger -> {
logger.setLevel(Level.INFO);
});
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
streamExecutionEnvironment.setParallelism(1);
StreamTableEnvironment streamTableEnvironment = StreamTableEnvironment.create(streamExecutionEnvironment);
// 定义目标表
streamTableEnvironment.executeSql("CREATE TABLE `gsq_hsjcxx_pre_copy1` (\n" +
" `reportid` BIGINT COMMENT 'reportid',\n" +
" `sfzh` VARCHAR COMMENT 'sfzh',\n" +
" `cjddh` VARCHAR COMMENT 'cjddh',\n" +
" `cjsj` VARCHAR COMMENT 'cjsj',\n" +
" PRIMARY KEY (`reportid`) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://127.0.0.1:3306/xxx?useSSL=false&useInformationSchema=true&nullCatalogMeansCurrent=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&',\n" +
" 'table-name' = 'xxx',\n" +
" 'username' = 'xxx',\n" +
" 'password' = 'xxx',\n" +
" 'sink.buffer-flush.max-rows' = '1024'\n" +
")");
// 定义源表
streamTableEnvironment.executeSql("CREATE TABLE `gsq_hsjcxx_pre` (\n" +
" `reportid` BIGINT COMMENT 'reportid',\n" +
" `sfzh` VARCHAR COMMENT 'sfzh',\n" +
" `cjddh` VARCHAR COMMENT 'cjddh',\n" +
" `cjsj` VARCHAR COMMENT 'cjsj'\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://127.0.0.1:3306/xxx?useSSL=false&useInformationSchema=true&nullCatalogMeansCurrent=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai',\n" +
" 'table-name' = 'xxx',\n" +
" 'username' = 'xxx',\n" +
" 'password' = 'xxx',\n" +
" 'scan.fetch-size' = '1024'\n" +
")");
// 将源表数据插入到目标表里面
streamTableEnvironment.executeSql("INSERT INTO `gsq_hsjcxx_pre_copy1` (`reportid`,\n" +
" `sfzh`,\n" +
" `cjddh`,\n" +
" `cjsj`)\n" +
"(SELECT `reportid`,\n" +
" `sfzh`,\n" +
" `cjddh`,\n" +
" `cjsj`\n" +
" FROM `gsq_hsjcxx_pre`)");
streamExecutionEnvironment.execute();
}
}
以上是一个简单的示例,定义了三个sql语句,首先是定义两个数据源,然后再进行查询插入操作,运行之后就会开始执行flinksql。
如果在启动的时候指定jvm的内存大小为 -Xms512m -Xmx1g,会发现压根启动不起来,直接就oom了。
如果不指定jvm内存的话,则程序能启动,内存的使用量会慢慢的升高,甚至要使用将近4G内存,如果在flink集群上运行的话,直接会oom的。
先说flink读取数据的流程,flink读取数据的时候是分批读取的,不可能一次性把数据全部读出来的,但是通过现象来看是flink读取数据的时候,所有数据都在内存里面的,这个现象是不合理的。
分析源码
通过调试模式分析代码是怎么走的,经过一番调试之后发现了一下代码
public void openInputFormat() {
try {
Connection dbConn = this.connectionProvider.getOrEstablishConnection();
if (this.autoCommit != null) {
dbConn.setAutoCommit(this.autoCommit);
}
this.statement = dbConn.prepareStatement(this.queryTemplate, this.resultSetType, this.resultSetConcurrency);
if (this.fetchSize == -2147483648 || this.fetchSize > 0) {
this.statement.setFetchSize(this.fetchSize);
}
} catch (SQLException var2) {
throw new IllegalArgumentException("open() failed." + var2.getMessage(), var2);
} catch (ClassNotFoundException var3) {
throw new IllegalArgumentException("JDBC-Class not found. - " + var3.getMessage(), var3);
}
}
先说下flink是怎么是如果分批拉取数据的,flink是使用的游标来分批拉取数据,那么这个时候就要确定是否真正使用了游标。
于是乎,我写了一个原生的JDBC程序读取数据的程序(没有限制jvm内存)
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class Main3 {
public static void main(String[] args) {
Connection connection = null;
Runtime runtime = Runtime.getRuntime();
System.out.printf("启动前总内存>%s 使用前的空闲内存>%s 使用前最大内存%s%n", runtime.totalMemory() / 1024 / 1024, runtime.freeMemory() / 1024 / 1024, runtime.maxMemory() / 1024 / 1024);
try {
int i = 0;
connection = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/xxx?useSSL=false&useInformationSchema=true&nullCatalogMeansCurrent=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useCursorFetch=true", "xxx", "xxx");
connection.setAutoCommit(false);
PreparedStatement preparedStatement = connection.prepareStatement("SELECT `reportid`,\n" +
" `sfzh`,\n" +
" `cjddh`,\n" +
" `cjsj`\n" +
" FROM `gsq_hsjcxx_pre`", ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
// 每批拉取的数据量
preparedStatement.setFetchSize(1024);
ResultSet resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
i++;
}
System.out.printf("启动前总内存>%s 使用前的空闲内存>%s 使用前最大内存%s%n", runtime.totalMemory() / 1024 / 1024, runtime.freeMemory() / 1024 / 1024, runtime.maxMemory() / 1024 / 1024);
System.out.println("数据量> " + i);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (connection != null) {
try {
connection.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
最终打印的结果是
很显然,数据是全部读取出来的,这个时候需要确认的程序是不是真正使用了游标,经过一番查看后发现,需要在jdbc的参数里面加上&useCursorFetch=true,才能使游标生效
修改完jdbc参数之后,问题就得到了完全的结局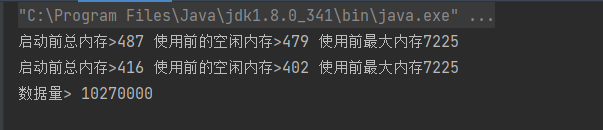
除此之外我用过apahce的seatunnel,这个同步数据的时候是真的快,快的离谱。不过使用的时候可能会漏掉一些jdbc相关的参数(MySQL为例)
"rewriteBatchedStatements" : "true" 这个批量的参数 apache seatunnel也不会自动添加的,需要手动加,不然数据就是一条一条插入的,这个坑我也踩了