LookupViT:类似SE的token压缩方案,加速还能丰富特征 | ECCV'24
视觉变换器(
ViT
)已成为众多工业级视觉解决方案的事实标准选择。但由于每一层都计算自注意力,这导致其推理成本对许多场景而言是不可接受的,因为自注意力在标记数量上具有平方的计算复杂度。另一方面,图像中的空间信息和视频中的时空信息通常是稀疏和冗余的。
LookupViT
旨在利用这种信息稀疏性来降低
ViT
的推理成本,提供了一种新颖的通用视觉变换器块,通过将来自高分辨率标记的信息压缩到固定数量的标记来操作。这些压缩的标记进行细致的处理,而高分辨率标记则通过计算成本较低的层。通过双向交叉注意力机制,使得这两个标记集之间的信息共享成为可能。该方法具有多个优点(a)通过标准高层操作,在标准的机器学习加速器(
GPU
/
TPU
)上易于实现。(b)适用于标准的
ViT
及其变体,因此能够推广到各种任务。(c)可以处理不同的标记化和注意力方法。
LookupViT
还为压缩标记提供了灵活性,使得在单个训练模型中进行性能与计算的权衡成为可能。论文在多个领域展示了
LookupViT
的有效性。
LookupViT
提供了
2X
的
FLOPs
减少,同时在这些领域保持或提高了准确性。此外,
LookupViT
在图像分类(
ImageNet-C,R,A,O
)上也表现出了开箱即用的鲁棒性和泛化能力,较
ViT
提高了多达
4%
。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: LookupViT: Compressing visual information to a limited number of tokens

Introduction
图像和视频作为现代视觉通信的基石,具有一个固有特性:它们的信息内容通常是稀疏的,并且存在显著的冗余。然而,尽管视觉变换器(
ViTs
)在多个视觉任务中占主导地位,但它们并没有利用这种冗余,而是以同质化的方式处理每个标记。这导致了与图像大小相关的平方计算复杂度,妨碍了其在实时场景中的应用。为了弥补这一差距,迫切需要有效地将视觉信息压缩为一个更小、更易于计算处理的标记集。这种表示将解锁
ViTs
在资源受限场景中的潜力,同时保持其灵活性和性能优势,这些优势使其在计算机视觉领域得到了广泛采用。
若干架构旨在通过有针对性地减少标记的数量来解决
ViTs
的计算负担。标记剪枝方法保留一部分标记,而标记池化技术则将相似的标记组合以获得更紧凑的表示。这些机制依赖基于注意力分数或特征相似性的启发式方法,特定任务可能需要额外的调整。尽管这些技术提供了有价值的好处,但它们可能需要根据应用进行进一步的微调。相较之下,论文提出了一种新颖的
LookupViT
模块,以替代传统的
ViT
模块,该模块本质上充当压缩模块。该设计消除了后处理或广泛微调的需要。此外,论文的方法保留了
ViT
架构的整体结构,从而允许使用现有方法(如标记修剪或合并)进行进一步优化和适应。
其它压缩模块,如
TokenLearner
和
Perceiver
,论文也进行了对比。
TokenLearner
在网络深度的很大一部分中利用传统的
ViT
模块,在后期将大量标记压缩到一个较小的集合(例如,
8
个或
16
个)。这种对
ViT
模块的依赖会产生相当大的计算开销,并严重限制了压缩模块在网络中的完全利用。另一方面,
Perceiver
通过在整个网络中以迭代方式直接从图像像素生成一小组潜在表示,设计了一种不对称的信息流。对于这些网络架构,从相同参数中提取多个模型并非易事,需要在提取的模型之间进行计算性能权衡。而
LookupViT
以提供可扩展的、计算上高效的模块而脱颖而出,这些模块可以像标准
ViT
模块一样无缝重复。其双向交叉注意力机制促进了压缩标记和原始标记之间更丰富的信息交换,增强了表达能力。
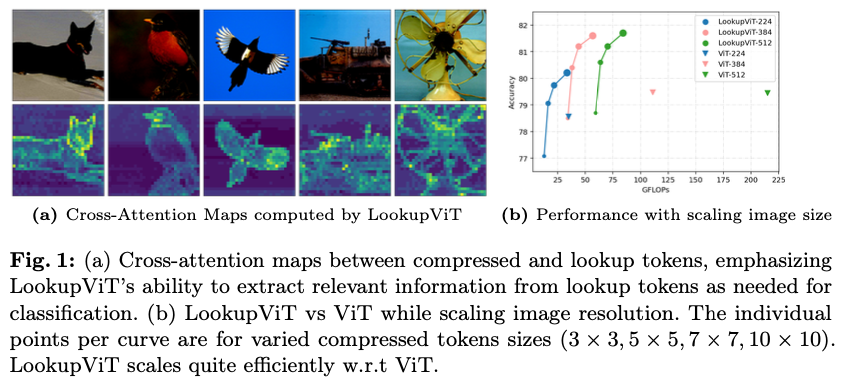
对于天生冗余的模态,如视觉,从原始标记中将相关的空间(和时间)信息压缩到一个更小的集合仍然可以维持性能,同时显著降低计算需求,前提是保持两个标记集合之间有效的信息交换。图
1b
表明,与传统的
ViT
模块相比,
LookupViT
能够有效地扩展到较大图像尺寸,因为它仅处理相关信息,而前者在原始图像标记的数量上呈平方级扩展。将较小的压缩标记集合称为压缩标记,这些标记“查看”较大的原始标记集合,将其称之为查找标记。
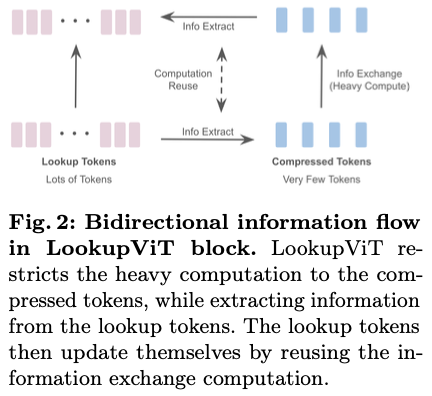
这些标记之间的信息交换发生在每个
LookupViT
模块中,其过程包括三个关键步骤,如图
2
所示。 (
i
) 交叉注意力将相关信息从查找标记转移到压缩标记(见图
1a
),(
ii
) 压缩标记之间的自注意力,以及(
iii
) 使用第一步中计算的共享注意力权重,将信息从压缩标记转移到查找标记。当压缩标记通过自注意力进行交流时,查找标记仅通过压缩标记进行相互通信。这种技术避免了平方级扩展,同时确保查找潜在表示在各层之间变得更加丰富。
LookupViT
的内部设计自然支持在标记压缩和可变图像或标记大小方面的灵活性。通过调整压缩标记和查找标记之间的下采样比例,成本与性能的权衡可以根据具体应用要求进行定制。这种多分辨率特性允许在推理阶段提取计算高效的高性能模型,同时保持相同的参数空间。为了验证
LookupViT
的有效性,论文在多个基准上展示了结果,如图像和视频分类,以及图像标题生成。值得注意的是,由于信息流的瓶颈设计,
LookupViT
还表现出对图像损坏的开箱即用的鲁棒性。
本工作的主要贡献如下:
- 高效的标记压缩:
LookupViT
引入了一种新颖的多头双向交叉注意力(
MHBC
)模块,能够实现有效的信息流动,同时显著节省计算成本。 - 通用框架:
LookupViT
提供了一个适用于视觉模态的灵活框架。它还通过压缩标记的多分辨率能力提供了计算与性能之间的权衡,同时保持相同的模型参数。 - 增强的性能:
LookupViT
在图像/视频模态的应用中表现出良好的泛化能力,并且具有开箱即用的抗损坏鲁棒性。
LookupViT Methodology
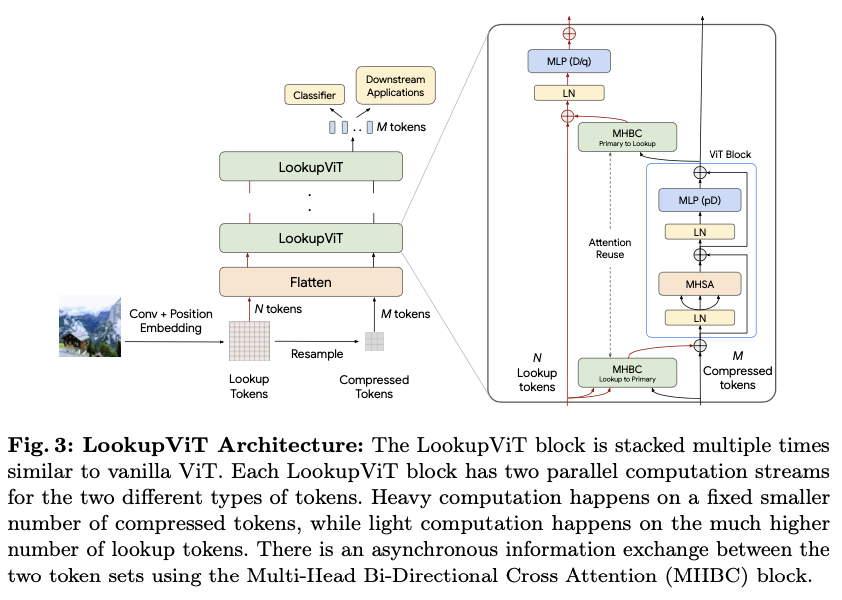
Overall Architecture
LookupViT
架构如图
3
所示。与
ViT
架构类似,它由一系列
LookupViT
模块组成。首先,输入的
RGB
图像(或视频)被分割成非重叠的图像块,随后通过卷积层生成特征嵌入,添加位置嵌入以构建输入标记,这一过程与标准
ViT
架构相同。与普通
ViT
不同的是,这里的核心思想是将视觉信息压缩为较少数量的标记,重点将大部分计算专注于这些标记。
固定数量的标记
\(M\)
\((\ll N)\)
,将其称为压缩标记,使用双线性插值从输入标记中抽取出来。对压缩标记进行的计算密集型处理类似于标准
ViT
模块,同时通过异步多头双向交叉注意力(
MHBC
)与原始标记交换信息。该过程分为以下几个步骤(
1
)信息聚集:压缩标记利用交叉注意力“查看”原始标记(称为查找标记)并收集相关信息。(
2
)表示精炼:压缩标记之间相互交换信息,更新其表示。(
3
)全局上下文注入:查找标记利用经过处理的信息丰富的压缩标记,更新自身表示,重用在信息聚集过程中计算的注意力权重以提高效率。
在整个过程中,查找标记只能通过与压缩标记的交互来收集信息,从而减少了计算复杂度。此外,查找标记经过一个具有较小投影维度 (
\(D/q\)
) 的多层感知机(
MLP
)模块,相较于普通模型的投影 (
\(pD\)
),该投影应用于压缩标记,其中
\(D\)
代表变换器的嵌入维度 (
\((p,q) = (4,2)\)
)。这种优化进一步减少了计算量。尽管存在这个显著的
MLP
瓶颈,
LookupViT
模块仍能实现与基线相当的性能,这证明了压缩标记与查找标记之间信息交换的有效性。
Input Tokenization
查找标记嵌入的构建类似于标准
ViT
的标记化策略。给定输入图像
\(\boldsymbol{\mathrm{X}} \in \mathbb{R}^{h \times w \times c}\)
,通过卷积层获得查找特征
\(\boldsymbol{\mathrm{F}}_l \in \mathbb{R}^{h_l \times w_l \times D}\)
。一个可学习的查找位置嵌入
\(\boldsymbol{\mathrm{F}}_{l,pos} \in \mathbb{R}^{h_l \times w_l \times D}\)
被添加到此特征图中。然后,这些标记被显著下采样到固定形状
\((h_p, w_p)\)
,构成压缩标记。
总结如下:
\boldsymbol{\mathrm{F}}_p &\leftarrow \boldsymbol{\mathcal{T}}\big(\boldsymbol{\mathrm{F}}_l, (h_p, w_p)\big) & \boldsymbol{\mathrm{F}}&_{p, pos} \leftarrow \boldsymbol{\mathcal{T}}\big(\boldsymbol{\mathrm{F}}_{l, pos}, (h_p, w_p)\big)\\
\boldsymbol{\mathrm{F}}_{p} &\leftarrow \boldsymbol{\mathrm{F}}_{p} + \boldsymbol{\mathrm{F}}_{p, pos} & \boldsymbol{\mathrm{F}}&_{l} \leftarrow \boldsymbol{\mathrm{F}}_{l} + \boldsymbol{\mathrm{F}}_{l, pos}
\end{align}
\]
算子
\(\boldsymbol{\mathcal{T}}(\mathbf{x},s)\)
以双线性方式将
\(\mathbf{x}\)
调整为形状
\(s\)
。查找标记和压缩标记网格的大小分别为
\((h_l, w_l)\)
和
\((h_p, w_p)\)
,
\(D\)
是嵌入维度。这些特征图
\(\boldsymbol{\mathrm{F}}_{p}\)
和
\(\boldsymbol{\mathrm{F}}_{l}\)
然后被空间展平为
\(\boldsymbol{\mathrm{z}}^0_p\)
和
\(\boldsymbol{\mathrm{z}}^0_l\)
:
& \boldsymbol{\mathrm{z}}^0_p = [\boldsymbol{\mathrm{F}}_{p(0,0)}, \dots, \boldsymbol{\mathrm{F}}_{p(h_p-1,w_p-1)}] & \boldsymbol{\mathrm{z}}^0_p &\in \mathbb{R}^{h_p.w_p \times D}\\
& \boldsymbol{\mathrm{z}}^0_l = [\boldsymbol{\mathrm{F}}_{l(0,0)}, \dots, \boldsymbol{\mathrm{F}}_{l(h_l-1,w_l-1)}] & \boldsymbol{\mathrm{z}}^0_l &\in \mathbb{R}^{h_l.w_l \times D}
\end{align}
\]
这些展平的特征图
\(\boldsymbol{\mathrm{z}}^0_p\)
和
\(\boldsymbol{\mathrm{z}}^0_l\)
(分别是压缩标记和查找标记)被作为输入传递给
LookupViT
块,该块通过信息交换有效地优化这些表示。调整比例
\(C = h_l.w_l/h_p.w_p\)
是一个灵活性参数,表示信息压缩的程度。这能够灵活地使用不同的调整比例训练模型,从而在特定的
\(C\)
下实现计算感知模型提取。更小的
\(C\)
值表示更多的压缩标记,从而具有更好的表示能力。实际上,
\(C=1\)
代表的是普通的
ViT
,但由于跨注意力的原因会有额外的计算。将查找标记和压缩标记的数量分别表示为
\(N = h_l.w_l\)
和
\(M = h_p.w_p\)
,这种标记化形式可以很容易扩展到视频,其中会引入一个表示时间的第三维度,压缩比例将变为
\(C = h_l.w_l.t_l/h_p.w_p.t_p\)
,其中
\(t_{.}\)
表示时间维度。
LookupViT Block

第
\(k^{th}\)
个
LookupViT
块接收来自前一个块的压缩标记
\(\boldsymbol{\mathrm{z}}^{k-1}_p\)
和查找标记
\(\boldsymbol{\mathrm{z}}^{k-1}_l\)
,促进这两个标记集之间的信息交换,并将更新后的表示传递给下一个块,这里的新架构设计是异步多头双向跨注意力(
MHBC
)。直观地说,在第一层中,查找标记比压缩标记保留了更丰富的图像表示。然而,在通过
LookupViT
块多次传递后,压缩标记积累了相关的压缩图像信息,从而使它们适合于下游任务。这是通过在每个
LookupViT
块中查找标记和压缩标记之间的迭代通信实现的(算法
4
)。
这一过程可以总结为三个关键步骤:
Information Gathering
在这一步骤中,通过 MHBC
\(_{l\rightarrow p}\)
可以实现从查找到压缩标记的单向信息流。压缩标记用作查询(
\(\boldsymbol{\mathrm{Q}}\)
),标记标记用作键值(
\(\boldsymbol{\mathrm{K}},\boldsymbol{\mathrm{V}}\)
),如算法
1
所示。此外,还存储了在此步骤中计算出的注意力权重
\(\mathcal{A}\)
,以便在反向共享信息时重复使用。
Representation Refinement
在信息提取步骤之后,压缩标记经过一个普通的
ViT
块(自注意力后跟
MLP
),如算法
3
所示。
MLP
维度上升因子
\(p\)
保持为
4
,和普通的
ViT
一样。但这个计算是在较小的压缩标记集上进行的。该步骤允许压缩标记之间进行内部信息共享,以更新它们的表示。
Global Context Infusion
信息收集与基于
ViT
的处理丰富了压缩标记特征,因为它们包含图像的全局压缩表示。虽然查找标记之间并不直接共享信息,但它们通过反向信息交换(从压缩标记到查找标记)了解全局信息,如算法
2
所示。这里不是重新计算注意力矩阵,而是重用之前在算法
1
中保存的注意力矩阵。这种关系进一步施加了两个特征图之间的隐式相似性约束,并增强了信息交换。最后,为了细化查找特征,应用一个低维的
MLP
块,维度为 (
\(D/q\)
),是普通
ViT MLP
维度的
\(pq\)
倍小(在所有的实验中设置
\((p, q) = (4, 2)\)
)。这为压缩标记在下一个
LookupViT
块中的信息提取丰富了查找标记。
Multi-Resolution Tokens
压缩标记通过简单地在非可学习的方式下调整查找标记的大小来构建。因此,可以在具有多种压缩标记分辨率的情况下共享相同的参数空间和查找标记。为此,在训练期间随机选择压缩标记的大小,借鉴了
FlexiViT
的灵感。一旦以这种方式进行训练,就可以从一个单一训练的模型中提取出多个具有不同计算需求的高性能模型。这种灵活性使得该方法可以在各种环境中使用,具体取决于资源的可用性。
Training and Token Utilization for Downstream Applications
在
LookupViT
中,整个网络中维护两组标记,
\(N\)
个查找标记和
\(M\)
个压缩标记。对于分类,可以将分类器应用于任一或两个标记集。通过实验证明,对两个头施加分类损失可以获得最佳性能。对各自的标记集使用全局平均池化,然后使用两个独立的分类器。接着,联合损失函数以相同的权重进行优化。
尽管训练损失独立应用于两个标记集,但在推理过程中使用压缩标记上的分类器就足够了,添加来自查找标记的分类器输出确实也可以略微提高性能。由于分类没有额外的计算成本,将压缩头和查找头的输出以相同的权重进行平均。对于分类以外的下游应用(例如,图像-语言模型任务,如字幕生成),在
LookupViT
编码器上使用解码器。这种情况下,使用有限的压缩标记集在计算上对交叉注意力块有好处。因此,实验只使用压缩标记。
Computational Complexity
设
\(\mathcal{C}_x\)
表示过程
\(x\)
的计算。然后,给定特征维度
\(D\)
、查找标记的数量
\(N\)
、压缩标记的数量
\(M (<<N)\)
、
MLP
升维因子
\(p=4\)
(针对压缩标记)和降维因子
\(q=2\)
(针对查找标记),普通
ViT
和
LookupViT
块的计算复杂度可以表示如下(忽略较小的项)。
{{\mathcal{C}}}_{\mathrm{ViT}} &= 2N^2D + 12ND^2\\
{{\mathcal{C}}}_{\mathrm{LookupViT}} &= \left(3NM + 2M^2\right)D + \left(4N + 15M\right)D^2
\end{align}
\]
LookupViT
消除了对查找标记数量
\(N\)
的平方依赖,并分别减少了注意力和线性投影的计算。由于压缩标记的数量
\(M (<< N)\)
保持在用户指定的值,因此注意力减少因子迅速增长,能够在更高分辨率下实现可扩展性。通常,对于
384
的图像分辨率,使用
\(N=576\)
和
\(M=25\)
,这显示出比普通模型更优越的性能,同时将
FLOPs
降低了超过
\(3\)
倍。
Results

如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
