[Flink/FlinkCDC] 实践总结:Flink 1.12.6 升级 Flink 1.15.4
Flink DataStream/API
未变的重要特性
虽然官宣建议弃用 JDK 8,使用JDK 11+;但:仍继续支持 JDK 8
个人猜测:JDK 8 的用户群实在太大,牵一发而动全身,防止步子扯太大,遏制自身项目的发展势头。
依赖模块的变化
版本变化
- flink.version : 1.12.6 => 1.15.4
- flink.connector.version : 1.12.6 => 1.15.4
- flink.connector.cdc.version : 1.3.0 => 2.3.0
Flink Cdc : flink cdc 2.0.0 之后,【groupId、包路径】 从
com.alibaba.ververica
变为
com.ververica
- apache flink cdc 1.3.0
<dependency>
<groupId>com.alibaba.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>1.3.0</version>
</dependency>
- apache flink cdc 2.3.0
<dependency>
<groupId>com.alibaba.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.3.0</version>
</dependency>
- 详情参见:
各模块摆脱了 scala
详情参见:
https://github.com/apache/flink/blob/release-1.15.4/docs/content.zh/release-notes/flink-1.15.md
【推荐】
https://nightlies.apache.org/flink/flink-docs-release-1.15/release-notes/flink-1.15/
org.apache.flink:flink-clients:${flink.version}flink-streaming-java:org.apache.flink:flink-table-api-java-bridge
org.apache.flink:flink-table-api-java-bridge_${scala.version}:${flink.version}
org.apache.flink:flink-connector-kafka:${flink.version}org.apache.flink:flink-runtime-web:${flink.version}`org.apache.flink:flink-statebackend-rocksdb:${flink.version}``
org.apache.flink:flink-table-planner:${flink.version}
org.apache.flink:flink-table-planner-blink_${scala.version}:${flink.version}
table-*-blink
转正 : flink-table-planner/runtime-blink => flink-table-planner、flink-table-runtime
- 从 Flink 1.15 开始,发行版包含两个规划器:
flink-table-planner_2.12-${flink.version}.jar
: in /opt, 包含查询规划器flink-table-planner-loader-${flink.version}.jar
【推荐】 : 默认加载
/lib
,包含隐藏在隔离类路径后面的查询计划器
注意:这2个规划器(planner_2)不能同时存在于类路径中。如果将它们都加载到
/lib
表作业
中,则会失败,报错
Could not instantiate the executor. Make sure a planner module is on the classpath
。
Exception in thread "main" org.apache.flink.table.api.TableException: Could not instantiate the executor. Make sure a planner module is on the classpath
at org.apache.flink.table.api.bridge.internal.AbstractStreamTableEnvironmentImpl.lookupExecutor(AbstractStreamTableEnvironmentImpl.java:108)
at org.apache.flink.table.api.bridge.java.internal.StreamTableEnvironmentImpl.create(StreamTableEnvironmentImpl.java:100)
at org.apache.flink.table.api.bridge.java.StreamTableEnvironment.create(StreamTableEnvironment.java:122)
at org.apache.flink.table.api.bridge.java.StreamTableEnvironment.create(StreamTableEnvironment.java:94)
at table.FlinkTableTest.main(FlinkTableTest.java:15)
Caused by: org.apache.flink.table.api.ValidationException: Multiple factories for identifier 'default' that implement 'org.apache.flink.table.delegation.ExecutorFactory' found in the classpath.
Ambiguous factory classes are:
org.apache.flink.table.planner.delegation.DefaultExecutorFactory
org.apache.flink.table.planner.loader.DelegateExecutorFactory
at org.apache.flink.table.factories.FactoryUtil.discoverFactory(FactoryUtil.java:553)
at org.apache.flink.table.api.bridge.internal.AbstractStreamTableEnvironmentImpl.lookupExecutor(AbstractStreamTableEnvironmentImpl.java:105)
... 4 more
Process finished with exit code 1
- flink 1.14 版本以后,之前版本
flink-table-*-blink-*
转正。所以:
flink-table-planner-blink
=>
flink-table-plannerflink-table-runtime-blink
=>
flink-table-runtime
停止支持 scala 2.11,但支持 2.12
scala.version = 2.12
flinkversion = 1.15.4
org.apache.flink:flink-connector-hive_${scala.version}:${flink.version}org.apache.flink:flink-table-api-java-bridge_${scala.version}:${flink.version}
相比 flink 1.12.6 时:
org.apache.flink:flink-table-api-java-bridge_${scala.version=2.11}:${flink.version=1.12.6}
flink-shaded-guava
模块的版本变化与包冲突问题
- 若报下列错误,即:版本不同引起的包冲突。
NoClassDefFoundError: org/apache/flink/shaded/guava30/com/google/common/collect/Lists
原因: flink 1.16、1.15 、1.12.6 等版本使用的 flink-shaded-guava 版本基本不一样,且版本不兼容,需要修改 cdc 中的 flink-shaded-guava 版本。
- 不同flink版本对应
flink-shaded-guava
模块的版本
- flink 1.12.6 : flink-shaded-guava
18.0-12.0- flink 1.15.4 : flink-shaded-guava
30.1.1-jre-15.0- flink 1.16.0 : flink-shaded-guava
30.1.1-jre-16.0
- 如果工程内没有主动引入
org.apache.flink:flink-shaded-guava
工程,则无需关心此问题————
flink-core
/
flink-runtime
/
flink-clients
等模块内部会默认引入正确的版本
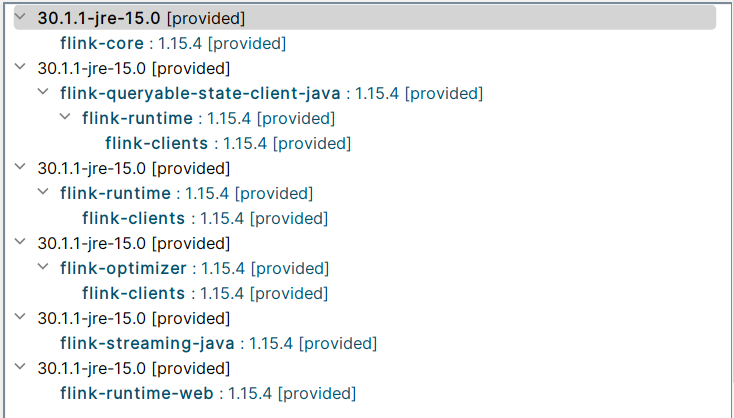
flink 1.15.4
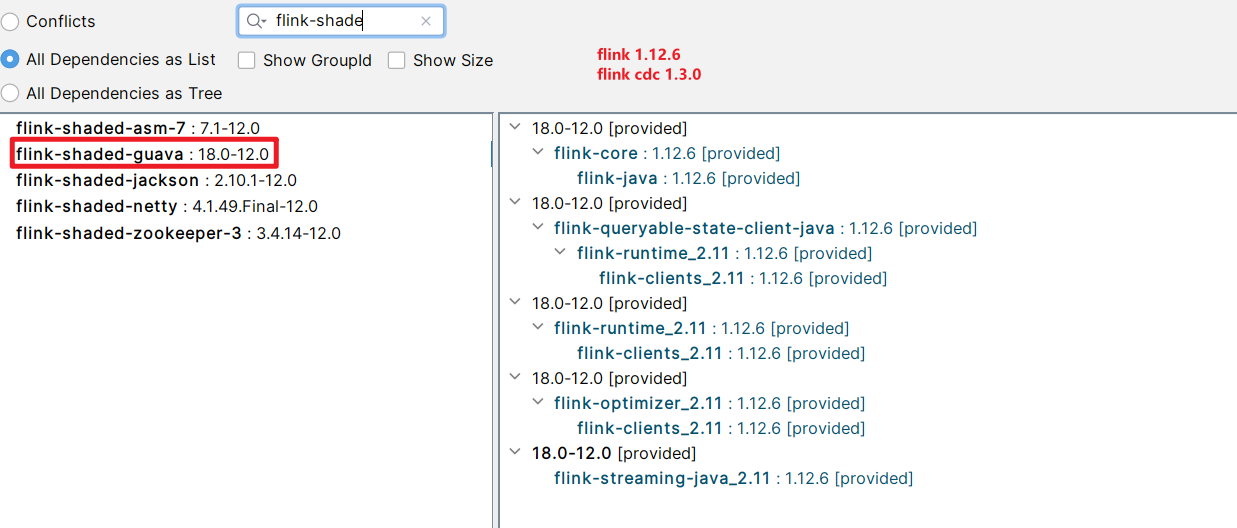
flink 1.12.6
MySQL JDBC Version :
≥ 8.0.16
=>
≥8.0.27
- 版本依据: Apache Flink CDC 官网
针对报错:
Caused by: java.lang.NoSuchMethodError: com.mysql.cj.CharsetMapping.getJavaEncodingForMysqlCharset(Ljava/lang/String;)Ljava/lang/String;
如果MySQL是8.0,fink cdc 2.1 之后由
debezium
连接器引起的问题。
- 将依赖改为8.0.21之后:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.32</version>
</dependency>
应用程序的源代码调整
Flink
KafkaRecordDeserializer : 不再存在/不再被支持(flink1.13.0及之后),并替换为
KafkaDeserializationSchema
,
KafkaSourceBuilder
创建本对象的语法稍有变化
org.apache.flink.connector.kafka.source.reader.deserializer.KafkaRecordDeserializer
| flink-connector-kafka_2.11 : 1.12.6
- flink 1.12.6
https://github.com/apache/flink/blob/release-1.12.6/flink-connectors/flink-connector-kafka/src/main/java/org/apache/flink/connector/kafka/source/reader/deserializer/KafkaRecordDeserializer.java- flink 1.12.7 : 仍存在/支持 KafkaRecordDeserializer
- flink 1.13.0 : 不再存在/不再支持 KafkaRecordDeserializer
- flink 14.0
- flink 1.15.4
- flink-connector-kafka : 3.0.0 | 了解即可,暂无需被此工程干扰上面思路
- 改造原因、改造思路
在 Apache Flink 1.13.0起,
KafkaRecordDeserializer
已被弃用、并被移除。
如果你正在使用的是Flink的旧版本,并且你看到了
KafkaRecordDeserializer
的提示,你应该将其替换为使用
KafkaDeserializationSchema
【推荐】或
KafkaDeserializer
。KafkaDeserializationSchema
相比
KafkaRecordDeserializer
,多了需要强制实现的2个方法:
boolean isEndOfStream(T var1)
: 默认返回 false 即可T deserialize(ConsumerRecord<byte[], byte[]> var1)
: 老方法
void deserialize(ConsumerRecord<byte[], byte[]> message, Collector<T> out)
内部调用的即本方法
// flink 1.15.4
//org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema
package org.apache.flink.streaming.connectors.kafka;
import java.io.Serializable;
import org.apache.flink.annotation.PublicEvolving;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.java.typeutils.ResultTypeQueryable;
import org.apache.flink.util.Collector;
import org.apache.kafka.clients.consumer.ConsumerRecord;
@PublicEvolving
public interface KafkaDeserializationSchema<T> extends Serializable, ResultTypeQueryable<T> {
default void open(DeserializationSchema.InitializationContext context) throws Exception {
}
boolean isEndOfStream(T var1);
T deserialize(ConsumerRecord<byte[], byte[]> var1) throws Exception;//方法1
default void deserialize(ConsumerRecord<byte[], byte[]> message, Collector<T> out) throws Exception {//方法2
T deserialized = this.deserialize(message);// 复用/调用的方法1
if (deserialized != null) {
out.collect(deserialized);
}
}
}
故新适配新增的
T deserialize(ConsumerRecord<byte[], byte[]> var1)
方法是很容易的:
import com.xxx.StringUtils;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.typeutils.TupleTypeInfo;
//import org.apache.flink.connector.kafka.source.reader.deserializer.KafkaRecordDeserializer;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
import org.apache.flink.util.Collector;
import org.apache.kafka.clients.consumer.ConsumerRecord;
//public class MyKafkaRecordDeserializer implements KafkaRecordDeserializer<Tuple2<String, String>> {
public class MyKafkaRecordDeserializer implements KafkaDeserializationSchema<Tuple2<String, String>> {
/* @Override
public void open(DeserializationSchema.InitializationContext context) throws Exception {
KafkaDeserializationSchema.super.open(context);
}*/
@Override
public boolean isEndOfStream(Tuple2<String, String> stringStringTuple2) {
return false;
}
@Override
public Tuple2<String, String> deserialize(ConsumerRecord<byte[], byte[]> consumerRecord) throws Exception {//适配新方法1 | 强制
if(consumerRecord.key() == null){
return new Tuple2<>("null", StringUtils.bytesToHexString(consumerRecord.value()) );
}
return new Tuple2<>( new String(consumerRecord.key() ) , StringUtils.bytesToHexString(consumerRecord.value() ) );
}
// @Override
// public void deserialize(ConsumerRecord<byte[], byte[]> consumerRecord, Collector<Tuple2<String, String>> collector) throws Exception {//适配老方法2 | 非强制
// collector.collect(new Tuple2<>(consumerRecord.key() == null ? "null" : new String(consumerRecord.key()), StringUtils.bytesToHexString(consumerRecord.value())));
// }
@Override
public TypeInformation<Tuple2<String, String>> getProducedType() {
return new TupleTypeInfo<>(BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO);
}
}
使用本类、创建本类对象的方式,也稍有变化:
// org.apache.flink.connector.kafka.source.KafkaSourceBuilder | flink-connector-kafka:1.15.4
KafkaSourceBuilder<Tuple2<String, String>> kafkaConsumerSourceBuilder = KafkaSource.<Tuple2<String, String>>builder()
.setTopics(canTopic)
.setProperties(kafkaConsumerProperties)
.setClientIdPrefix(Constants.JOB_NAME + "#" + System.currentTimeMillis() + "")
.setDeserializer( KafkaRecordDeserializationSchema.of(new MyKafkaRecordDeserializer()) ); // flink 1.15.4
//.setDeserializer(new MyKafkaRecordDeserializer());// flink 1.12.6
- 推荐文献
Flink Cdc : flink cdc 2.0.0 之后,【groupId、包路径】 从
com.alibaba.ververica
变为
com.ververica
MySQLSource : 包路径被调整(2.0.0及之后)、类名大小写有变化(flink cdc 2.0.0 及之后)、不再被推荐使用(flink cdc 2.1.0 及之后)
com.alibaba.ververica.cdc.connectors.mysql.MySQLSource
| flink cdc 1.3.0
https://github.com/apache/flink-cdc/blob/release-2.0.0/flink-connector-mysql-cdc/src/main/java/com/ververica/cdc/connectors/mysql/MySqlSource.java
com.ververica.cdc.connectors.mysql.MySqlSource
自 flink cdc 2.1.0 及之后
被建议弃用
、但
com.ververica.cdc.connectors.mysql.source.MySqlSource
被推荐可用
https://github.com/apache/flink-cdc/blob/release-2.1.0/flink-connector-mysql-cdc/src/main/java/com/ververica/cdc/connectors/mysql/MySqlSource.java
Flink CDC这个MySqlSource弃用了,还有别的方式吗? - aliyun
【推荐】有两个MysqlSource,一个是弃用的,另一个是可用的,包名不同。
com.ververica.cdc.connectors.mysql.source
这个包下的是可用的。
com.ververica.cdc.connectors.mysql.source.MySqlSource
| flink cdc 2.3.0
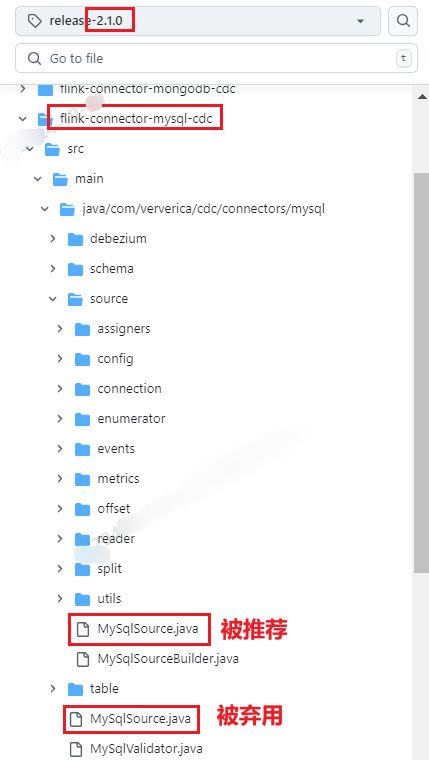
serverId : 如果选择新的
MySqlSource
类,则:其设置入参稍有变化
com.alibaba.ververica.cdc.connectors.mysql.MySQLSource#serverId()
| flink cdc 1.3.0
com.ververica.cdc.connectors.mysql.source.MySqlSource
| flink cdc 2.1.0 、 2.3.0 【被推荐使用】
没有
serverId
方法
https://github.com/apache/flink-cdc/blob/release-2.1.0/flink-connector-mysql-cdc/src/main/java/com/ververica/cdc/connectors/mysql/source/MySqlSourceBuilder.java
有
serverId
方法,通过
MySqlSource.<String>builder()
即
MySqlSourceBuilder
/**
* A numeric ID or a numeric ID range of this database client, The numeric ID syntax is like
* '5400', the numeric ID range syntax is like '5400-5408', The numeric ID range syntax is
* required when 'scan.incremental.snapshot.enabled' enabled. Every ID must be unique across all
* currently-running database processes in the MySQL cluster. This connector joins the MySQL
* cluster as another server (with this unique ID) so it can read the binlog. By default, a
* random number is generated between 5400 and 6400, though we recommend setting an explicit
* value."
*/
public MySqlSourceBuilder<T> serverId(String serverId) {
this.configFactory.serverId(serverId);
return this;
}
com.ververica.cdc.connectors.mysql.source.MySqlSource#serverId(int serverId)
| flink cdc 2.1.0 【被建议弃用】、flink cdc 2.3.0 【被废止/无法用】
/**
* A numeric ID of this database client, which must be unique across all currently-running
* database processes in the MySQL cluster. This connector joins the MySQL database cluster
* as another server (with this unique ID) so it can read the binlog. By default, a random
* number is generated between 5400 and 6400, though we recommend setting an explicit value.
*/
public Builder<T> serverId(int serverId) {
this.serverId = serverId;
return this;
}
- 改造Demo: flink 1.3.0
SourceFunction<String> mySqlSource =
MySqlSource.<String>builder()
//数据库地址
.hostname(jobParameterTool.get("cdc.mysql.hostname"))
//端口号
.port(Integer.parseInt(jobParameterTool.get("cdc.mysql.port")))
//用户名
.username(jobParameterTool.get("cdc.mysql.username"))
//密码
.password(jobParameterTool.get("cdc.mysql.password"))
//监控的数据库
.databaseList(jobParameterTool.get("cdc.mysql.databaseList"))
//监控的表名,格式数据库.表名
.tableList(jobParameterTool.get("cdc.mysql.tableList"))
//虚拟化方式
.deserializer(new MySQLCdcMessageDeserializationSchema())
//时区
.serverTimeZone("UTC")
.serverId( randomServerId(5000, Constants.JOB_NAME + "#xxxConfig") )
.startupOptions(StartupOptions.latest())
.build();
public static Integer randomServerId(int interval, String jobCdcConfigDescription){
//startServerId ∈[ interval + 0, interval + interval)
//int serverId = RANDOM.nextInt(interval) + interval; // RANDOM.nextInt(n) : 生成介于 [0,n) 区间的随机整数
//serverId = [ 7000 + 0, Integer.MAX_VALUE - interval)
int serverId = RANDOM.nextInt(Integer.MAX_VALUE - interval - 7000) + 7000;
log.info("Success to generate random server id result! serverId : {}, interval : {}, jobCdcConfigDescription : {}"
, serverId , interval , jobCdcConfigDescription );
return serverId;
}
- 改造Demo: flink 2.3.0
MySqlSource<String> mySqlSource =
MySqlSource.<String>builder()
//数据库地址
.hostname(jobParameterTool.get("cdc.mysql.hostname"))
//端口号
.port(Integer.parseInt(jobParameterTool.get("cdc.mysql.port")))
//用户名
.username(jobParameterTool.get("cdc.mysql.username"))
//密码
.password(jobParameterTool.get("cdc.mysql.password"))
//监控的数据库
.databaseList(jobParameterTool.get("cdc.mysql.databaseList"))
//监控的表名,格式数据库.表名
.tableList(jobParameterTool.get("cdc.mysql.tableList"))
//虚拟化方式
.deserializer(new MySQLCdcMessageDeserializationSchema())
//时区
.serverTimeZone("UTC")
.serverId( randomServerIdRange(5000, Constants.JOB_NAME + "#xxxConfig") )
.startupOptions(StartupOptions.latest())
.build();
//新增强制要求: interval >= 本算子的并行度
public static String randomServerIdRange(int interval, String jobCdcConfigDescription){
// 生成1个起始随机数 |
//startServerId = [interval + 0, interval + interval )
//int startServerId = RANDOM.nextInt(interval) + interval; // RANDOM.nextInt(n) : 生成介于 [0,n) 区间的随机整数
//startServerId = [ 7000 + 0, Integer.MAX_VALUE - interval)
int startServerId = RANDOM.nextInt(Integer.MAX_VALUE - interval - 7000) + 7000;
//endServerId ∈ [startServerId, startServerId + interval];
int endServerId = startServerId + interval;
log.info("Success to generate random server id result! startServerId : {},endServerId : {}, interval : {}, jobCdcConfigDescription : {}"
, startServerId, endServerId , interval , jobCdcConfigDescription );
return String.format("%d-%d", startServerId, endServerId);
}
MySQLSourceBuilder#build 方法: 返回类型存在变化:
SourceFunction/DebeziumSourceFunction<T>
=>
MySqlSource<T>
org.apache.flink.streaming.api.functions.source.SourceFunction
=>
com.ververica.cdc.connectors.mysql.source.MySqlSource
//com.alibaba.ververica.cdc.connectors.mysql.MySQLSource.Builder#build | flink cdc 1.3.0
// 返回: com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction
// public class DebeziumSourceFunction<T> extends RichSourceFunction<T> implements CheckpointedFunction, CheckpointListener, ResultTypeQueryable<T>
//public abstract class org.apache.flink.streaming.api.functions.source.RichSourceFunction<OUT> extends AbstractRichFunction implements SourceFunction<OUT>
public DebeziumSourceFunction<T> build() {
Properties props = new Properties();
props.setProperty("connector.class", MySqlConnector.class.getCanonicalName());
props.setProperty("database.server.name", "mysql_binlog_source");
props.setProperty("database.hostname", (String)Preconditions.checkNotNull(this.hostname));
props.setProperty("database.user", (String)Preconditions.checkNotNull(this.username));
props.setProperty("database.password", (String)Preconditions.checkNotNull(this.password));
props.setProperty("database.port", String.valueOf(this.port));
props.setProperty("database.history.skip.unparseable.ddl", String.valueOf(true));
if (this.serverId != null) {
props.setProperty("database.server.id", String.valueOf(this.serverId));
}
...
}
//com.ververica.cdc.connectors.mysql.source.MySqlSourceBuilder#build | flink cdc 2.3.0
//// 返回:
public MySqlSource<T> build() {
return new MySqlSource(this.configFactory, (DebeziumDeserializationSchema)Preconditions.checkNotNull(this.deserializer));
}
- 使用变化Demo: Flink cdc 1.3.0
Properties properties = new Properties();
properties.setProperty("database.hostname", "localhost");
properties.setProperty("database.port", "3306");
properties.setProperty("database.user", "your_username");
properties.setProperty("database.password", "your_password");
properties.setProperty("database.server.id", "1"); // 设置唯一的 server id
properties.setProperty("database.server.name", "mysql_source");
DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder()
.hostname("localhost")
.port(3306)
.username("your_username")
.password("your_password")
.databaseList("your_database")
.tableList("your_table")
.includeSchemaChanges(true) // 开启监听表结构变更
.deserializer(new StringDebeziumDeserializationSchema())
.build();
DataStreamSource<String> stream = env.addSource(sourceFunction);//可以使用 addSource
stream.print();
env.execute("MySQL CDC Job");
- 使用变化Demo: Flink cdc 2.3.0
https://flink-tpc-ds.github.io/flink-cdc-connectors/release-2.3/content/connectors/mysql-cdc(ZH).html
无法使用
env.addSource(SourceFunction, String sourceName)
,只能使用
env.fromSource(Source<OUT, ?, ?> source, WatermarkStrategy<OUT> timestampsAndWatermarks, String sourceName)
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
public class MySqlSourceExample {
public static void main(String[] args) throws Exception {
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("yourHostname")
.port(yourPort)
.databaseList("yourDatabaseName") // 设置捕获的数据库, 如果需要同步整个数据库,请将 tableList 设置为 ".*".
.tableList("yourDatabaseName.yourTableName") // 设置捕获的表
.username("yourUsername")
.password("yourPassword")
.deserializer(new JsonDebeziumDeserializationSchema()) // 将 SourceRecord 转换为 JSON 字符串
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置 3s 的 checkpoint 间隔
env.enableCheckpointing(3000);
env
.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
// 设置 source 节点的并行度为 4
.setParallelism(4)
.print().setParallelism(1); // 设置 sink 节点并行度为 1
env.execute("Print MySQL Snapshot + Binlog");
}
}
StartupOptions : 包路径被调整(2.0.0及之后)
import com.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions
| flink 1.3.0
com.ververica.cdc.connectors.mysql.table.StartupOptions
| flink 2.3.0
DebeziumDeserializationSchema : 包路径被调整(flink-cdc2.0.0及之后)
com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema
| flink cdc 1.3.0
com.ververica:flink-connector-debezium:1.3.0
https://github.com/apache/flink-cdc/blob/release-1.3.0/flink-connector-debezium/src/main/java/com/alibaba/ververica/cdc/debezium/DebeziumDeserializationSchema.java
com.ververica.cdc.debezium.DebeziumDeserializationSchema
| flink cdc 2.3.0
com.ververica:flink-connector-debezium:2.3.0
https://github.com/apache/flink-cdc/blob/release-2.3.0/flink-connector-debezium/src/main/java/com/ververica/cdc/debezium/DebeziumDeserializationSchema.java
X 参考文献
- Flink+Flink CDC版本升级的依赖问题总结 - CSDN
- apache flink cdc
- https://github.com/apache/flink-cdc
- https://github.com/apache/flink-cdc/blob/master/docs/content/docs/faq/faq.md
- https://github.com/apache/flink-cdc/tree/master/flink-cdc-connect/flink-cdc-source-connectors/flink-sql-connector-mysql-cdc
com.alibaba.ververica:flink-connector-mysql-cdc:1.3.0https://github.com/apache/flink-cdc/blob/release-1.3.0/flink-connector-mysql-cdc/pom.xml
【推荐】 Flink 1.12.6
com.ververica:flink-connector-mysql-cdc:2.0MYSQL (Database: 5.7, 8.0.x / JDBC Driver: 8.0.16 ) | Flink 1.12 + | JDK 8+
https://github.com/apache/flink-cdc/tree/release-2.0
https://github.com/apache/flink-cdc/blob/release-2.0/flink-connector-mysql-cdc/pom.xml
com.ververica:flink-connector-mysql-cdc:2.3.0https://github.com/apache/flink-cdc/blob/release-2.3.0/flink-connector-mysql-cdc/pom.xml
【推荐】 Flink 1.15.4
org.apache.flink:flink-connector-mysql-cdc:${flink.cdc.version}
- apache flink
- apache flink-connector-kafka