人工智能模型训练中的数据之美——探索TFRecord

上一篇:《构建人工智能模型基础:TFDS和Keras的完美搭配》
序言:
在人工智能模型的训练过程中,如何高效管理和处理大量数据是一个重要的课题。TensorFlow 的 TFRecord 格式为大规模数据存储和处理提供了一种灵活且高效的解决方案。在本节知识中,我们将介绍如何利用 TFRecord 结合 TensorFlow 的 Dataset API 进行数据的提取、转换和加载(ETL),从而更好地支持人工智能模型的训练和优化。通过 TFRecord,您可以将原始数据存储为一种轻量且易于处理的二进制格式,从而在大规模数据集的加载和解析上获得显著的性能提升。我们将详细探索如何构建 ETL 数据管道,通过并行处理、批处理和预取等技术,让数据加载与模型训练过程更加流畅、快速。这种数据处理方式不仅在单台机器上表现出色,还能在多核 CPU、GPU 或 TPU 上扩展,实现更大规模的人工智能模型训练。无论您是处理图像、文本,还是其他类型的大规模数据,理解并掌握 TFRecord 及其优化技术将为构建高效的数据管道奠定基础,使您能够更快速、智能地训练人工智能模型。
理解 TFRecord
当您使用 TFDS 时,数据会被下载并缓存到磁盘,因此您无需每次使用时都重新下载。TFDS 使用 TFRecord 格式进行缓存。如果您仔细观察下载过程,就会发现这一点——例如,图 4-1 展示了 cnn_dailymail 数据集如何被下载、打乱并写入 TFRecord 文件。

图 4-1. 将 cnn_dailymail 数据集下载为 TFRecord 文件
在 TensorFlow 中,TFRecord 是存储和检索大量数据的首选格式。这是一种非常简单的文件结构,按顺序读取以提高性能。在磁盘上,文件的结构相对直接,每条记录由一个表示记录长度的整数、其对应的循环冗余校验(CRC)、一个数据的字节数组及该字节数组的 CRC 组成。这些记录被连接成一个文件,如果数据集很大,则会进行分片。

例如,图 4-2 显示了 cnn_dailymail 的训练集在下载后被分成了 16 个文件。
为了更直观地了解一个简单的示例,可以下载 MNIST 数据集并打印其信息:
data, info = tfds.load("mnist", with_info=True)
print(info)
在 info 中,您会看到其特征是这样存储的:
features=FeaturesDict({
'image': Image(shape=(28, 28, 1), dtype=tf.uint8),
'label': ClassLabel(shape=(), dtype=tf.int64, num_classes=10),
}),
与 CNN/DailyMail 的示例类似,文件会被下载到 /root/tensorflow_datasets/mnist/
您可以像这样将原始记录作为 TFRecordDataset 加载:
filename="/root/tensorflow_datasets/mnist/3.0.0/mnist-test.tfrecord-00000-of-00001"
raw_dataset = tf.data.TFRecordDataset(filename)
for raw_record in raw_dataset.take(1):
print(repr(raw_record))
请注意,文件名的位置可能会根据您的操作系统而有所不同。
<tf.Tensor: shape=(), dtype=string, numpy=b"\n\x85\x03\n\xf2\x02\n\x05image\x12\xe8\x02\n\xe5\x02\n\xe2\x02\x89PNG\r \n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x00\x1c\x00\x00\x00\x1c\x08\x00\x00\x00\x00Wf \x80H\x00\x00\x01)IDAT(\x91\xc5\xd2\xbdK\xc3P\x14\x05\xf0S(v\x13)\x04,.\x82\xc5A q\xac\xedb\x1d\xdc\n.\x12\x87n\x0e\x82\x93\x7f@Q\xb2\x08\xba\tbQ0.\xe2\xe2\xd4\x b1\xa2h\x9c\x82\xba\x8a(\nq\xf0\x83Fh\x95\n6\x88\xe7R\x87\x88\xf9\xa8Y\xf5\x0e\x 8f\xc7\xfd\xdd\x0b\x87\xc7\x03\xfe\xbeb\x9d\xadT\x927Q\xe3\xe9\x07:\xab\xbf\xf4\ xf3\xcf\xf6\x8a\xd9\x14\xd29\xea\xb0\x1eKH\xde\xab\xea%\xaba\x1b=\xa4P/\xf5\x02\ xd7\\x07\x00\xc4=,L\xc0,>\x01@2\xf6\x12\xde\x9c\xde[t/\xb3\x0e\x87\xa2\xe2\ xc2\xe0A<\xca\xb26\xd5(\x1b\xa9\xd3\xe8\x0e\xf5\x86\x17\xceE\xdarV\xae\xb7_\xf3 I\xf7(\x06m\xaaE\xbb\xb6\xac\r
\x9b$e<\xb8\xd7\xa2\x0e\x00\xd0l\x92\xb2\xd5\x15\ xcc\xae'\x00\xf4m\x08O'+\xc2y\x9f\x8d\xc9\x15\x80\xfe\x99[q\x962@CN|i\xf7\xa9!=\ \xab\x19\x00\xc8\xd6\xb8\xeb\xa1\xf0\xd8l\xca\xfb]\xee\xfb]
\x9fV\xe1\x07\xb7\xc 9\x8b55\xe7M\xef\xb0\x04\xc0\xfd&\x89\x01<\xbe\xf9\x03*\x8a\xf5\x81\x7f\xaa/2y\x 87ks\xec\x1e\xc1\x00\x00\x00\x00IEND\xaeB`\x82\n\x0e\n\x05label\x12\x05\x1a\x03\ n\x01\x02">
它是一个包含记录详细信息的长字符串,里面还包括校验和等内容。但是如果我们已经知道特征,我们就可以创建一个特征描述,然后用它来解析数据。代码如下:
创建特征描述
feature_description = {
'image': tf.io.FixedLenFeature([], dtype=tf.string),
'label': tf.io.FixedLenFeature([], dtype=tf.int64),
}
def _parse_function(example_proto):
使用上面的字典解析输入的
tf.Example
proto
return tf.io.parse_single_example(example_proto, feature_description)
parsed_dataset = raw_dataset.map(_parse_function)
for parsed_record in parsed_dataset.take(1):
print((parsed_record))
这样输出的内容就友好多了!首先,您可以看到图像是一个 Tensor,并且它包含一个 PNG。PNG 是一种压缩图像格式,头部由 IHDR 定义,图像数据位于 IDAT 和 IEND 之间。如果仔细观察字节流,您可以看到它们。同时也有标签,它以整数形式存储,包含值 2:
{
'image': <tf.Tensor: shape=(), dtype=string,
numpy=b"\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x00\x1c\x00\x00\x00\x1c\x08\x00\x00\x00\x00Wf\x80H\x00\x00\x01)IDAT(\x91\xc5\xd2\xbdK\xc3P\x14\x05\xf0S(v\x13)\x04,.\x82\xc5Aq\xac\xedb\x1d\xdc\n.\x12\x87n\x0e\x82\x93\x7f@Q\xb2\x08\xba\tbQ0.\xe2\xe2\xd4\xb1\xa2h\x9c\x82\xba\x8a(\nq\xf0\x83Fh\x95\n6\x88\xe7R\x87\x88\xf9\xa8Y\xf5\x0e\x8f\xc7\xfd\xdd\x0b\x87\xc7\x03\xfe\xbeb\x9d\xadT\x927Q\xe3\xe9\x07:\xab\xbf\xf4\xf3\xcf\xf6\x8a\xd9\x14\xd29\xea\xb0\x1eKH\xde\xab\xea%\xaba\x1b=\xa4P/\xf5\x02\xd7\\x07\x00\xc4=,L\xc0,>\x01@2\xf6\x12\xde\x9c\xde[t/\xb3\x0e\x87\xa2\xe2\xc2\xe0A<\xca\xb26\xd5(\x1b\xa9\xd3\xe8\x0e\xf5\x86\x17\xceE\xdarV\xae\xb7_\xf3AR\r!I\xf7(\x06m\xaaE\xbb\xb6\xac\r*\x9b$e<\xb8\xd7\xa2\x0e\x00\xd0l\x92\xb2\xd5\x15\xcc\xae'\x00\xf4m\x08O'+\xc2y\x9f\x8d\xc9\x15\x80\xfe\x99[q\x962@CN|i\xf7\xa9!=\xd7
\xab\x19\x00\xc8\xd6\xb8\xeb\xa1\xf0\xd8l\xca\xfb]\xee\xfb]
\x9fV\xe1\x07\xb7\xc9\x8b55\xe7M\xef\xb0\x04\xc0\xfd&\x89\x01<\xbe\xf9\x03
\x8a\xf5\x81\x7f\xaa/2y\x87ks\xec\x1e\xc1\x00\x00\x00\x00IEND\xaeB`\x82">,
'label': <tf.Tensor: shape=(), dtype=int64, numpy=2>
}
到这里,您可以读取原始的 TFRecord 并使用类似 Pillow 的 PNG 解码库将其解码为 PNG。
在 TensorFlow 中管理数据的 ETL 过程
无论规模大小,ETL 都是 TensorFlow 用于训练的核心模式。我们在本书中探索了小规模的单台计算机模型构建,但相同的技术可以用于大规模训练,跨多台机器并处理海量数据集。
ETL 过程的提取阶段是将原始数据从存储位置加载,并准备成可以转换的形式。转换阶段是对数据进行操作,使其适合或优化用于训练。例如,将数据进行批处理、图像增强、映射到特征列等逻辑,都可以算作转换阶段的一部分。加载阶段则是将数据加载到神经网络中进行训练。
来看一下完整的代码,用来训练“马匹或人类”分类器。这里我添加了注释,展示提取、转换和加载阶段的所在位置:
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_addons as tfa
模型定义开始
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(300, 300, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='Adam', loss='binary_crossentropy', metrics=['accuracy'])
模型定义结束
提取阶段开始
data = tfds.load('horses_or_humans', split='train', as_supervised=True)
val_data = tfds.load('horses_or_humans', split='test', as_supervised=True)
提取阶段结束
转换阶段开始
def augmentimages(image, label):
image = tf.cast(image, tf.float32)
image = (image/255)
image = tf.image.random_flip_left_right(image)
image = tfa.image.rotate(image, 40, interpolation='NEAREST')
return image, label
train = data.map(augmentimages)
train_batches = train.shuffle(100).batch(32)
validation_batches = val_data.batch(32)
转换阶段结束
python
转换阶段结束
加载阶段开始
history = model.fit(train_batches, epochs=10, validation_data=validation_batches, validation_steps=1)
加载阶段结束
通过这样的流程,您的数据管道可以更少地受到数据和底层模式变化的影响。当您使用 TFDS 提取数据时,无论数据是小到可以放入内存,还是大到无法放入简单的机器中,都可以使用相同的底层结构。用于转换的 tf.data API 也是一致的,因此无论底层数据源是什么,都可以使用类似的 API。当然,一旦数据被转换,加载数据的过程也是一致的,无论您是在单个 CPU、GPU、多个 GPU 集群,甚至是 TPU 群组上进行训练。
然而,加载数据的方式可能对训练速度产生巨大影响。接下来,我们来看看如何优化加载阶段。
优化加载阶段
在训练模型时,我们可以深入了解提取-转换-加载(ETL)过程。我们可以认为数据的提取和转换可以在任何处理器上进行,包括 CPU。事实上,这些阶段的代码执行诸如下载数据、解压缩数据、逐条记录处理等任务,这些都不是 GPU 或 TPU 的强项,所以这部分代码通常会在 CPU 上运行。但是在训练阶段,GPU 或 TPU 能显著提升性能,因此如果有条件,最好在这一阶段使用 GPU 或 TPU。
因此,在有 GPU 或 TPU 的情况下,理想的做法是将工作负载分配到 CPU 和 GPU/TPU 上:提取和转换在 CPU 上完成,而加载则在 GPU/TPU 上完成。
假设您正在处理一个大型数据集。由于数据量大,必须以批次方式准备数据(即,执行提取和转换),这样就会出现类似图 4-3 所示的情况。当第一个批次正在准备时,GPU/TPU 处于空闲状态。当这个批次准备好时,它会被发送到 GPU/TPU 进行训练,但此时 CPU 则空闲,直到训练完成,CPU 才能开始准备第二个批次。在这里会有大量的空闲时间,因此我们可以看到优化的空间。
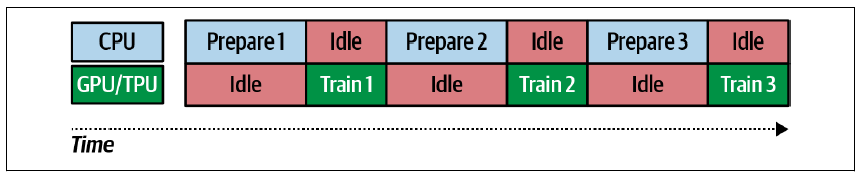
图 4-3. 在 CPU/GPU 上训练
逻辑上的解决方案是并行处理,让数据准备和训练同时进行。这种过程称为流水线处理,见图 4-4。
图 4-4. 流水线处理
在这种情况下,当 CPU 准备第一个批次时,GPU/TPU 仍然没有任务,因此处于空闲状态。当第一个批次准备好后,GPU/TPU 可以开始训练——同时,CPU 开始准备第二个批次。当然,训练第 n-1 批次和准备第 n 批次所需的时间并不总是相同的。如果训练时间更快,GPU/TPU 会有一段空闲时间;如果训练时间更慢,CPU 会有一段空闲时间。选择合适的批次大小可以帮助优化这里的性能——由于 GPU/TPU 的时间往往更昂贵,您可能会尽量减少它们的空闲时间。
您可能已经注意到,当我们从 Keras 中的简单数据集(如 Fashion MNIST)转向使用 TFDS 版本时,必须在训练之前对它们进行批处理。这就是原因:流水线模型的存在使得无论数据集有多大,您都可以使用一致的 ETL 模式来处理它。
并行 ETL 以提高训练性能
TensorFlow 为您提供了所有并行化提取和转换过程所需的 API。让我们通过 Dogs vs. Cats 数据集和底层 TFRecord 结构来看看它们的样子。
首先,使用 tfds.load 获取数据集:
train_data = tfds.load('cats_vs_dogs', split='train', with_info=True)
如果您想使用底层的 TFRecords,您需要访问下载的原始文件。由于数据集较大,它被分成多个文件(在 4.0.0 版本中分为 8 个)。
您可以创建这些文件的列表,并使用 tf.data.Dataset.list_files 来加载它们:
file_pattern = f'/root/tensorflow_datasets/cats_vs_dogs/4.0.0/cats_vs_dogs-train.tfrecord*'
files = tf.data.Dataset.list_files(file_pattern)
获取文件后,可以使用 files.interleave 将它们加载到数据集中,如下所示:
train_dataset = files.interleave(
tf.data.TFRecordDataset,
cycle_length=4,
num_parallel_calls=tf.data.experimental.AUTOTUNE
)
这里有几个新概念,我们来花点时间解释一下。
cycle_length 参数指定同时处理的输入元素数量。稍后您会看到解码记录的映射函数,它会在从磁盘加载时解码记录。因为 cycle_length 设置为 4,所以这个过程会一次处理四条记录。如果不指定该值,它会根据可用的 CPU 核心数量自动确定。
num_parallel_calls 参数用于指定要执行的并行调用数量。在这里设置为 tf.data.experimental.AUTOTUNE 可以使代码更具可移植性,因为值会根据可用的 CPU 动态调整。结合 cycle_length 参数,您就设置了并行度的最大值。例如,如果在自动调整后 num_parallel_calls 设置为 6 而 cycle_length 是 4,那么会有六个独立线程,每个线程一次加载四条记录。
现在提取过程已经并行化了,我们来看看如何并行化数据的转换。首先,创建加载原始 TFRecord 并将其转换为可用内容的映射函数——例如,将 JPEG 图像解码成图像缓冲区:
def read_tfrecord(serialized_example):
feature_description = {
"image": tf.io.FixedLenFeature((), tf.string, ""),
"label": tf.io.FixedLenFeature((), tf.int64, -1),
}
example = tf.io.parse_single_example(serialized_example, feature_description)
image = tf.io.decode_jpeg(example['image'], channels=3)
image = tf.cast(image, tf.float32)
image = image / 255
image = tf.image.resize(image, (300, 300))
return image, example['label']
如您所见,这是一个典型的映射函数,没有做任何特定的工作来使它并行化。并行化将在调用映射函数时完成。以下是实现方法:
import multiprocessing
cores = multiprocessing.cpu_count()
print(cores)
train_dataset = train_dataset.map(read_tfrecord, num_parallel_calls=cores)
train_dataset = train_dataset.cache()
首先,如果您不想自动调优,可以使用 multiprocessing 库获取 CPU 的数量。然后,在调用映射函数时,您可以将此 CPU 数量作为并行调用的数量传入。就是这么简单。
cache 方法会将数据集缓存到内存中。如果您的 RAM 足够多,这会显著加快速度。不过,如果在 Colab 中使用 Dogs vs. Cats 数据集尝试此操作,可能会导致虚拟机崩溃,因为数据集无法完全装入内存。在这种情况下,Colab 的基础设施会为您提供一个新的、更高 RAM 的机器。
加载和训练过程同样可以并行化。在对数据进行打乱和批处理时,还可以根据可用 CPU 核心数量进行预取。代码如下:
train_dataset = train_dataset.shuffle(1024).batch(32)
train_dataset = train_dataset.prefetch(tf.data.experimental.AUTOTUNE)
当训练集完全并行化后,您可以像以前一样训练模型:
model.fit(train_dataset, epochs=10, verbose=1)
我在 Google Colab 中试验了这一点,发现这些用于并行化 ETL 过程的额外代码将每个 epoch 的训练时间从 75 秒减少到约 40 秒。如此简单的更改几乎将我的训练时间减半!
总结
到此为止我们完成了介绍谷歌的 TensorFlow Datasets,这是一个可以让您访问各种数据集的库,从小规模学习数据集到用于研究的全规模数据集。您看到它们使用了通用 API 和格式,以减少您获取数据时所需编写的代码量。我们还讨论了 ETL 过程,它是 TFDS 设计的核心,特别是我们探索了并行化提取、转换和加载数据以提高训练性能。在接下来的知识中,我们将细分学习当今最热的人工智能主题,自然语言处理技术。