模态内重叠优化,简单有效的CLIP微调方法 | BMVC'24 Oral
来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: CLIP Adaptation by Intra-modal Overlap Reduction

创新点
- 提出一种基于轻量级适配的新方法,直接在图像空间中减少
CLIP
中的模态内重叠(
IMO
)。新特征与任何利用缓存模型的无训练方法兼容,这些新特征提高了所有被检查的无训练方法的整体性能。 - 表明直接减少模态内重叠(
IMO
)与性能之间存在正相关关系。 - 探索了通过在监督和自监督方式下训练轻量级适配器来减少模态内重叠(
IMO
)的可能性。
内容概述
许多方法尝试将预训练的基础
CLIP
模型适应于少样本分类,因为
CLIP
在大规模语料库上进行训练,它能够通过适应少样本分类而具有良好的泛化能力。但当尝试在与预训练数据的分布差异显著的数据集上使用这一基础模型时,观察到性能并不理想。
论文分析了图像空间内的模态重叠,从嵌入表示的角度出发。由于对比训练最大化了配对图像和文本之间的余弦相似性(跨模态),而忽略了图像与图像之间的相似性(模态内),在图像空间中比较来自
CLIP
的嵌入是有问题的。这导致了非配对(不同类别的图像)和配对图像(同一类别的图像)之间存在显著的模态内重叠(
IMO
),这影响了依赖于图像空间相似性进行预测的少样本无训练分类方法的性能。
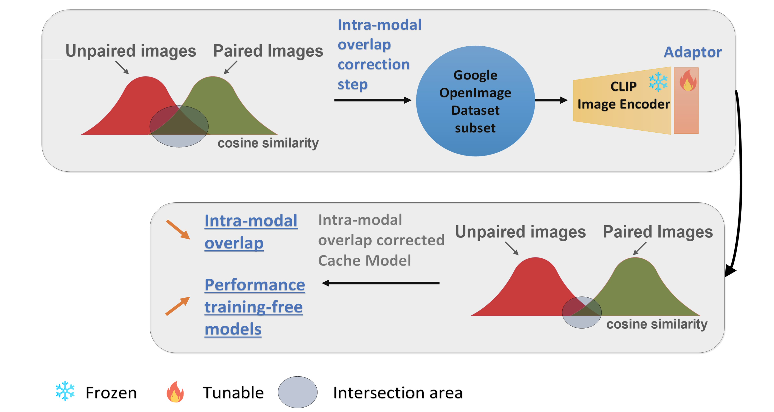
为了解决模态内的重叠,在
Google Open Images
数据集的通用样本集上训练一个轻量级适配器。只需训练一个
epoch
,即可提高少样本无训练分类的准确性。
通过广泛的证明了其有效性,减少模态内重叠可以带来 a ) 在多个标准数据集上提高性能,b ) 增强对分布变化的鲁棒性,以及 c ) 提高特征方差,使特征在下游任务中更具区分能力。
模态内重叠
模态内重叠分析
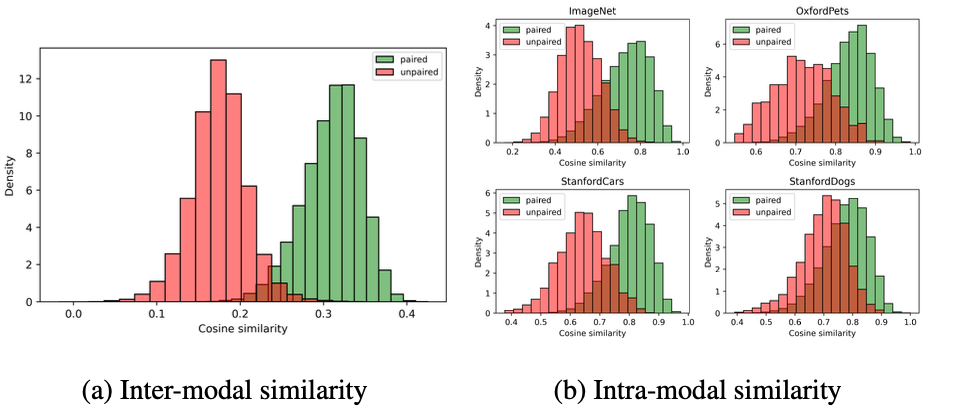
由于对比学习最大化了成对图像与文本之间的余弦相似度(模态间),但忽略了图像与图像之间的相似度(模态内),导致模态内重叠(
IMO
)。
通过适应校正模态内重叠(
IMO
)
为了在
CLIP
视觉编码器中校正模态内重叠(
IMO
),引入了瓶颈适配器并在来自
Google Open Images
数据集的小样本图像上以监督方式进行微调。适配器是轻量级组件,向模型中添加了
0.80%
(大约
1M
)的新参数。
微调得到新的
CLIP
视觉编码器(
VEimo
)后,利用它创建一个改进的缓存模型,类似于
Tip-Adapter
。使用校正了
IMO
的编码
N
个类别各
K
张的训练图像
\(G_{train} \in \mathbb{R}^{NK\times d}\)
,将这些编码作为键,它们对应的
one-hot
编码标签
\(L_k, k \in \{1, NK\}\)
作为值,以形成键值缓存模型,目的是增强
CLIP
模型的先验知识。
给定一个通过
VEimo
编码的测试图像
\(U_i \in \mathbb{R}^{d}\)
,
Affinity
矩阵
\(Y\)
和
Tip-Adapter
++(
TA
++)的对数计算如下(用于
softmax
标签预测):
Y = exp(-\beta(1-U_i G_{train}^T)), Y \in \mathbb{R}^{NK}
\label{eq:ta_affinity_modgap}
\end{equation}
\]
\text{TA++logits} = T_i W^T + \alpha YL_{train}, \text{TA++logits} \in \mathbb{R}^{N}
\end{equation}
\]
同样,通过用校正后的
IMO
矩阵
\(Y\)
替换标准
Tip-X
的亲和矩阵
\(A\)
来改进标准
Tip-X
,从而获得
Tip-X
++(
TX
++)的对数值(用于
softmax
标签预测):
\text{TX++logits} = T_i W^T + \alpha YL_{train} + \gamma \phi(-M) L_{train}, \text{TX++logits} \in \mathbb{R}^{N}
\end{equation}
\]
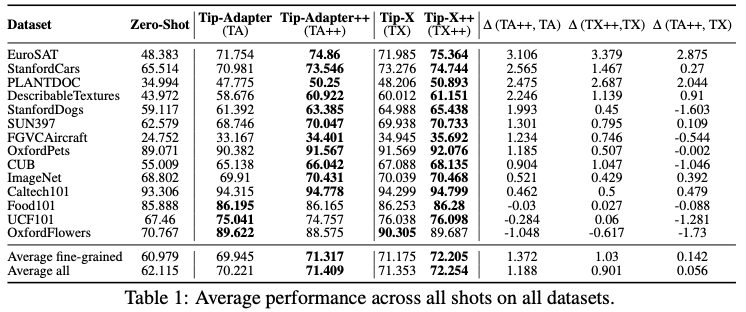
主要实验
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
