新型大语言模型的预训练与后训练范式,阿里Qwen

前言:
大型语言模型(LLMs)的发展历程可以说是非常长,从早期的GPT模型一路走到了今天这些复杂的、公开权重的大型语言模型。最初,LLM的训练过程只关注预训练,但后来逐步扩展到了包括预训练和后训练在内的完整流程。后训练通常涵盖监督指导微调和对齐过程,而这些在ChatGPT的推广下变得广为人知。
自ChatGPT首次发布以来,训练方法学也在不断进化。在这几期的文章中,我将回顾近1年中在预训练和后训练方法学上的最新进展。
关于LLM开发与训练流程的概览,特别关注本文中讨论的新型预训练与后训练方法
每个月都有数百篇关于LLM的新论文提出各种新技术和新方法。然而,要真正了解哪些方法在实践中效果更好,一个非常有效的方式就是看看最近最先进模型的预训练和后训练流程。幸运的是,在近1年中,已经有四个重要的新型LLM发布,并且都附带了相对详细的技术报告。
在本文中,我将重点介绍以下模型中的Qwen 2预训练和后训练流程:
• 阿里巴巴的 Qwen 2
• 苹果的 智能基础语言模型
• 谷歌的 Gemma 2
• Meta AI 的 Llama 3.1
我会完整的介绍列表中的全部模型,但介绍顺序是基于它们各自的技术论文在arXiv.org上的发表日期,这也巧合地与它们的字母顺序一致。
1. 阿里的 Qwen 2
我们先来说说 Qwen 2,这是一个非常强大的 LLM 模型家族,与其他主流的大型语言模型具有竞争力。不过,不知为何,它的知名度不如 Meta AI、微软和谷歌那些公开权重的模型那么高。
1.1 Qwen 2 概览
在深入探讨 Qwen 2 技术报告中提到的预训练和后训练方法之前,我们先简单总结一下它的一些核心规格。
Qwen 2 系列模型共有 5 种版本,包括 4 个常规(密集型)的 LLM,分别为 5 亿、15 亿、70 亿和 720 亿参数。此外,还有一个专家混合模型(Mixture-of-Experts),参数量为 570 亿,但每次仅激活 140 亿参数。(由于这次不重点讨论模型架构细节,我就不深入讲解专家混合模型了,不过简单来说,它与 Mistral AI 的 Mixtral 模型类似,但激活的专家更多。如果想了解更高层次的概述,可以参考这一篇知识《模型融合、专家混合与更小型 LLM 的未来》中的 Mixtral 架构部分。)
Qwen 2 模型的一大亮点是它在 30 种语言中的出色多语言能力。此外,它的词汇量非常大,达到 151,642 个 token。(相比之下,Llama 2 的词汇量为 32k,而 Llama 3.1 则为 128k)。根据经验法则,词汇量增加一倍,输入 token 数量会减少一半,因此 LLM 可以在相同输入中容纳更多 token。这种大词汇量特别适用于多语言数据和编程场景,因为它能覆盖标准英语词汇之外的单词。
下面是与其他 LLM 在 MMLU 基准测试中的简要对比。(需要注意的是,MMLU 是一个多选基准测试,因此有其局限性,但仍是评估 LLM 性能的最受欢迎方法之一。)
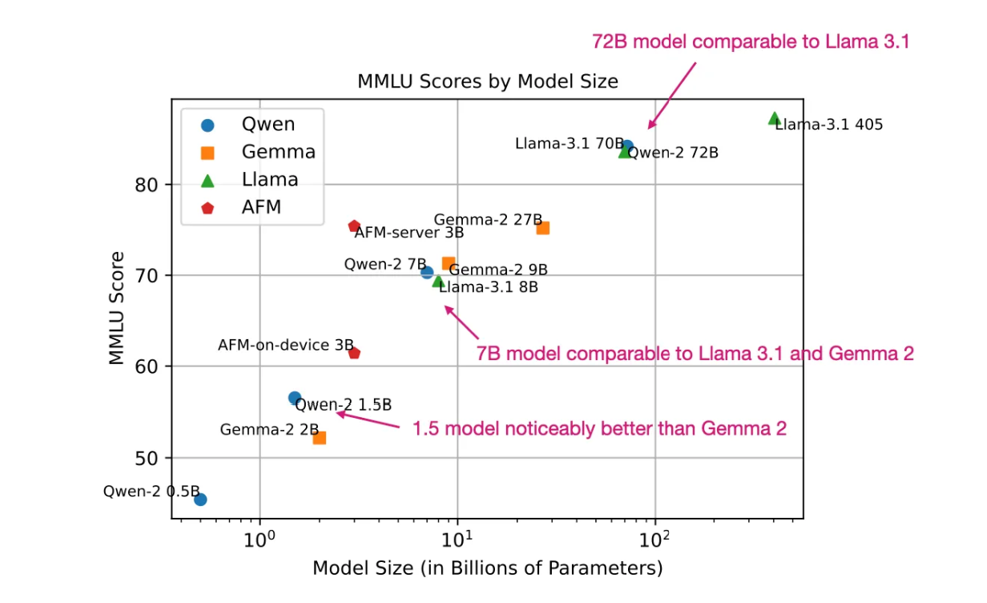
MMLU基准测试得分,针对最新的开源权重模型(分数越高越好)。这个图中的得分是从每个模型的官方研究论文中收集的。
1.2 Qwen 2 预训练
Qwen 2 团队对参数规模为 15 亿、70 亿和 720 亿的模型进行了训练,使用了 7 万亿个训练 token,这是一个合理的规模。作为对比,Llama 2 模型使用了 2 万亿个 token,Llama 3.1 模型使用了 15 万亿个 token。
有趣的是,参数规模为 5 亿的模型使用了 12 万亿个 token 进行训练。然而,研究人员并没有用这个更大的 12 万亿 token 数据集来训练其他模型,因为在训练过程中并未观察到性能提升,同时额外的计算成本也难以合理化。
他们的一个重点是改进数据过滤流程,以去除低质量数据,同时增强数据混合,从而提升数据的多样性——这一点我们在分析其他模型时会再次提到。
有趣的是,他们还使用了 Qwen 模型(尽管没有明确说明细节,我猜是指前一代的 Qwen 模型)来生成额外的预训练数据。而且,预训练包含了“多任务指令数据……以增强模型的上下文学习能力和指令遵循能力。”
此外,他们的训练分为两个阶段:常规预训练和长上下文预训练。在预训练的最后阶段,他们使用了“高质量、长文本数据”将上下文长度从 4,096 token 增加到 32,768 token。
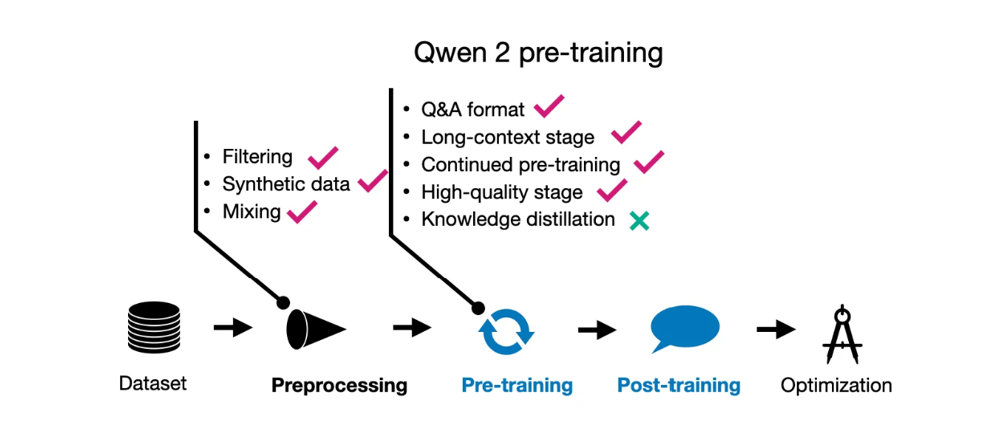
Qwen 2 预训练技术总结。‘持续预训练’指的是两阶段预训练,研究人员先进行了常规预训练,然后接着进行长上下文的持续预训练。
(遗憾的是,这些技术报告的另一个特点是关于数据集的细节较少,因此如果总结看起来不够详细,是因为公开的信息有限。)
1.3 Qwen 2 后训练
Qwen 2 团队采用了流行的两阶段后训练方法,首先进行监督式指令微调(SFT),在 50 万个示例上进行了 2 个 epoch 的训练。这一阶段的目标是提高模型在预设场景下的响应准确性。

典型的大语言模型开发流程
在完成 SFT 之后,他们使用直接偏好优化(DPO)来将大语言模型(LLM)与人类偏好对齐。(有趣的是,他们的术语将其称为基于人类反馈的强化学习,RLHF。)正如我几周前在《LLM预训练和奖励模型评估技巧》文章中所讨论的,由于相比其他方法(例如结合 PPO 的 RLHF)更加简单易用,SFT+DPO 方法似乎是当前最流行的偏好调优策略。
对齐阶段本身也分为两个步骤。第一步是在现有数据集上使用 DPO(离线阶段);第二步是利用奖励模型形成偏好对,并进入“在线”优化阶段。在这里,模型在训练中会生成多个响应,奖励模型会选择优化步骤中更符合偏好的响应,这种方法也常被称为“拒绝采样”。
在数据集构建方面,他们使用了现有语料库,并通过人工标注来确定 SFT 的目标响应,以及识别偏好和被拒绝的响应(这是 DPO 的关键)。研究人员还合成了人工注释数据。
此外,团队还使用 LLM 生成了专门针对“高质量文学数据”的指令-响应对,以创建用于训练的高质量问答对。
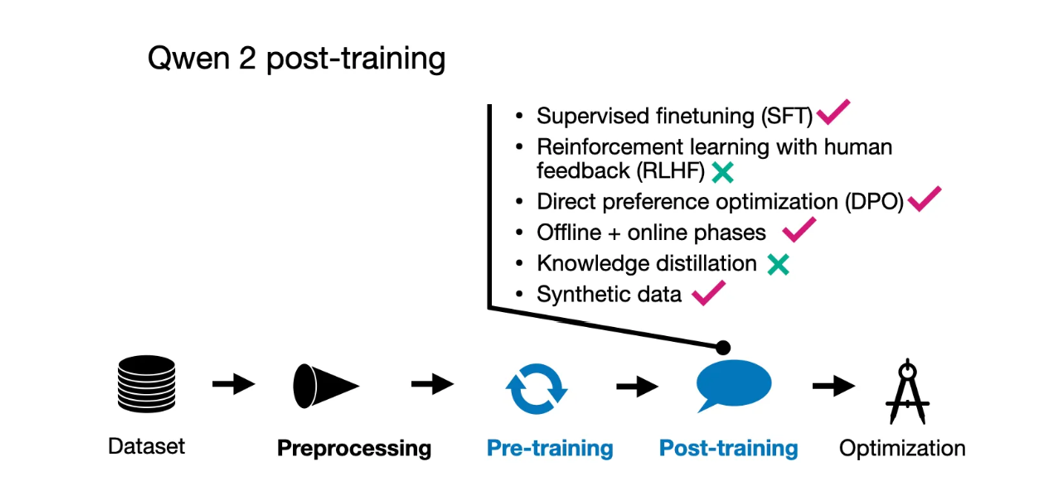
Qwen2后训练技术汇总
1.4 结论
Qwen 2 是一个相对能力较强的模型,与早期的 Qwen 系列类似。在 2023 年 12 月的 NeurIPS LLM 效率挑战赛中,我记得大部分获胜方案都涉及 Qwen 模型。
关于 Qwen 2 的训练流程,值得注意的一点是,合成数据被用于预训练和后训练阶段。同时,将重点放在数据集过滤(而不是尽可能多地收集数据)也是 LLM 训练中的一个显著趋势。在我看来,数据确实是越多越好,但前提是要满足一定的质量标准。
从零实现直接偏好优化(DPO)对齐 LLM
直接偏好优化(DPO)已经成为将 LLM 更好地与用户偏好对齐的首选方法之一。这篇文章中你会多次看到这个概念。如果你想学习它是如何工作的,Sebastian Raschka博士有一篇很好的文章,即:《从零实现直接偏好优化(DPO)用于 LLM 对齐》,你可以看看它。在介绍完本文列表中的模型扣会根据它用中文语言为大家重新编写一篇发布出来。
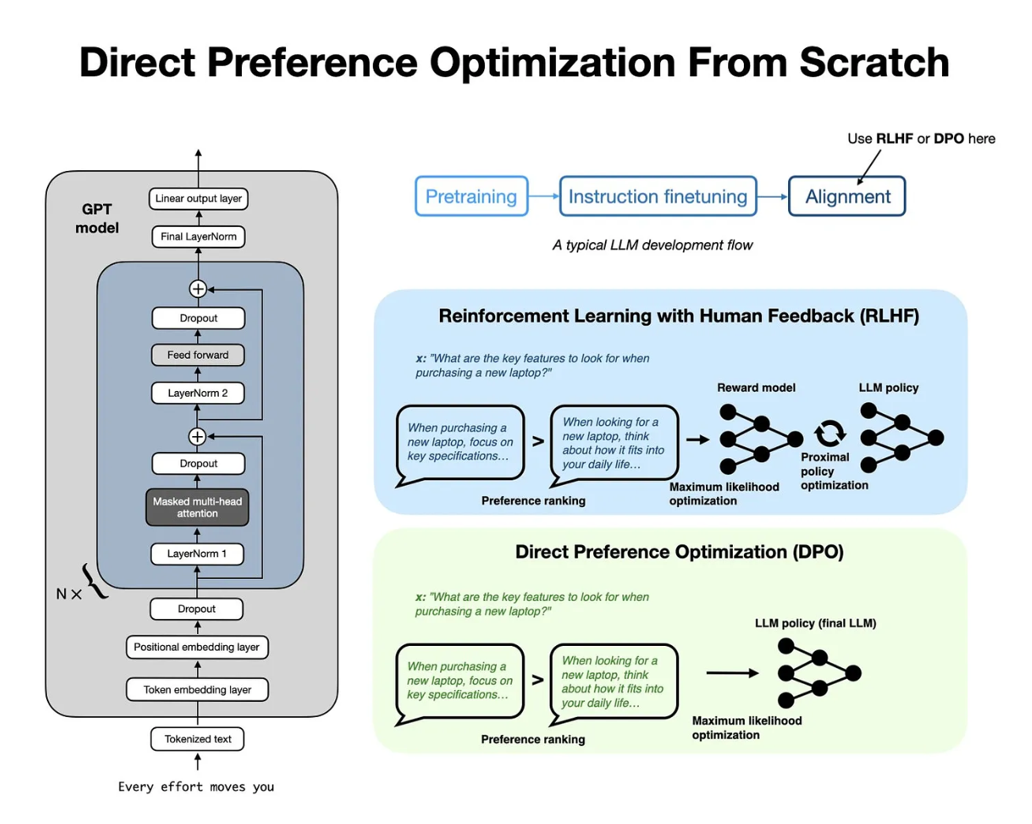
利用DPO技术实现人工智能大语言模型与人类对齐流程概览