用于航空发动机故障诊断的深度分层排序网络
标题:
Deep hierarchical sorting networks for fault diagnosis of aero-engines
期刊:
Computers in Industry (中科院
1
区top
, JCR
Q1
, IF=
8.2
) 2024年12月发表
原文链接:
https://doi.org/10.1016/j.compind.2024.104229
原文引用格式:
Jinlei Wu, Lin Lin, Dan Liu, Song Fu, Shiwei Suo, Sihao Zhang, Deep hierarchical sorting networks for fault diagnosis of aero-engines, Computers in Industry, Volume 165, 2025, 104229, ISSN 0166-3615, https://doi.org/10.1016/j.compind.2024.104229
前言
本文开发了一种高效的故障诊断框架FSHSM-PCNN,用于进行航空发动机故障诊断,该架构由一个新提出的
基于故障影响力的分层排序模块
(FSHSM)和
并行卷积神经网络
组成。其中,FSHSM用于对状态点数据按照其对故障诊断的影响力进行分层排序,以捕获不同时间点数据间的
协同效应
;并行卷积神经网络分别以原始样本和经过排序模块排序后的样本作为输入,获取数据的
时序状态信息
和
协同信息
,合并后的特征用于进行航空发动机故障的准确诊断。
1. 论文解决的问题
- 在进行多传感器信号采集时,受到自身或硬件设备的影响,部分传感器信号会出现迟滞,导致传感器在时间上不同步,导致部分时间点数据上的
关键信息被淹没
。 - 航空发动机的性能退化并非是线性的,受到工况和操作习惯的影响,它的性能退化更体现在部分的关键时间点数据上,而这些关键时间点数据之间存在的
协同效应
并未被考虑。 - 航空发动机发生故障的概率较低,因此大多采集的是正常数据,故障数据较少,导致深度学习模型对故障样本学习不足,引发
误诊和漏诊
。
2. 论文贡献
- 应用
双池化模块
对不同时间点数据进行
信号形貌指标提取
(平均值和最大值),平均值和最大值突出的时间点可能展现出迟滞信号的峰值。 - 提出一个
基于故障影响力的分层排序模块
FSHSM
,对所得信号形貌指标索引值进行分层排序,进而对样本中状态点数据进行分层排序,相同层级中的状态点数据存在更强的
协同效应
。 - 设计了
并行卷积神经网络
PCNN
,分别接受原始样本和分层排序后的样本作为输入,这样能从数量远小于正常样本的故障样本中,提取到
更多的特征
信息。
3. 方法框架

架构可分为三部分:数据预处理、状态点数据分层排序、并行卷积神经网络特征提取。数据预处理主要包含数据介绍、数据标准化、样本构造等,下面对所提架构以及基础模型进行介绍。
3.1 所提方法架构
(1) 状态点数据分层排序模块FSHSM
用于获取不同时间点数据对航空发动机故障诊断的故障影响力层级,以在同层级中加强不同时间点数据间的协同效应。
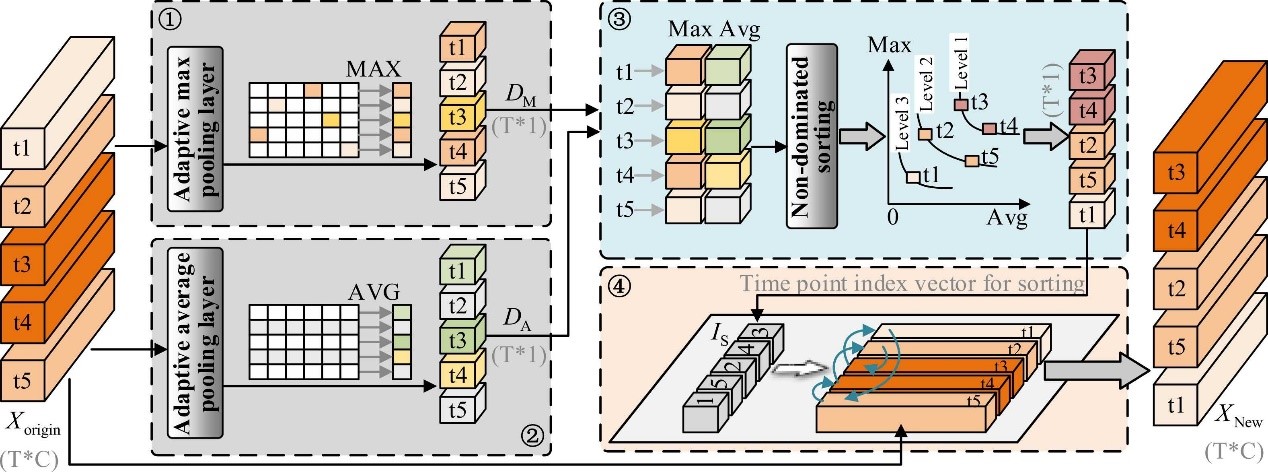
(2) 并行卷积神经网络PCNN
用于获取数据的时序状态特征和协同强化特征,以深入挖掘数据中包含的故障信息,提高故障诊断精度。

具体的实现步骤如下所示:
① 信号形貌指标提取:应用最大池化和平均池化计算状态点数据的最大值和平均值,以此作为信号形貌指标。
② 信号形貌指标索引值分层排序:以最大值和平均值为目标函数,对状态点数据的索引值进行分层排序。
③ 样本内部数据重新排序:基于②得到的排序索引,对样本内部的状态点数据按照索引映射重新排序,样本内部形成不同故障影响力等级的区域。
④ 时序状态信息提取:第一个卷积网络从原始样本中通过学习提取时序状态信息。
⑤ 强化协同信息提取:另一个并行的卷积网络从排序后的样本中提取拥有不同影响力等级的数据间的强化协同信息。
⑥ 特征融合及分类:将⑤和⑥中的信息进行拼接并分类。
⑦ 损失计算及反向传播。
3.2 基础模型介绍
3.2.1 快速非支配排序算法 (FNSA)
快速非支配排序(Fast Non-Dominated Sorting)算法是多目标优化中常用的一种排序方法,尤其在遗传算法中应用广泛(如NSGA-II算法)。它的目标是将种群中的个体根据非支配关系进行排序,以便选出更优的个体进行选择和交叉。
在多目标优化问题中,一个个体被称为支配另一个个体,若其在所有目标上都优于或等于另一个个体,并且至少在一个目标上严格优于另一个个体。非支配排序的过程是将种群中的个体分成不同的等级,每个等级包含了一组非支配的个体。
快速非支配排序的基本步骤是:
(1) 对于种群中的每个个体,计算其被其他个体支配的情况。
(2) 将不被任何个体支配的个体放入第一层(等级0)。
(3) 对于第一层的每个个体,查找它支配的个体,并将这些个体加入下一层。
(4) 重复此过程,直到所有个体都被分配到某一层,最终得到每个个体的排序。
本研究中仅涉及两个目标函数(最大值x
i
和平均值x
j
),最大化任意两个解决方案只存在两种情况:
x
i
支配x
j
或
x
i
与x
j
互不支配
。

3.2.2 一维卷积神经网络
一维卷积神经网络(1DCNN)是一种用于处理序列数据的深度学习模型,通过滑动卷积核在输入序列上提取局部特征,常用于时间序列分析、自然语言处理和语音识别等任务。它通过卷积层提取特征、池化层降低维度,并最终通过全连接层进行分类或回归。相比传统的全连接网络,1D-CNN能够减少计算复杂度并提高模型的鲁棒性,适用于捕捉序列数据中的局部模式。所选用的1DCNN除了拥有卷积层和池化层外,在卷积层和池化层中间还有批归一化层和激活函数,目的是为了解决深度神经网络中的梯度消失和梯度爆炸问题,并引入非线性特征,使得网络能够学习到更加复杂的映射关系。

4. 实验及结果
作者进行了三种实验,分别为
消融实验
、
不均衡数据集验证实验
、
独立性验证实验
。消融实验证明了所提排序模块FSHSM的增加,以及并行卷积神经网络的设计,是非常有效的;不均衡数据集验证实验证明了所提方法在解决不均衡样本上具有一定的优势;独立性验证实验可以说明,所提的FSHSM能够作为一个简捷的模块进行使用,可以无缝衔接到现有的深度学习模块中并且提高模型的学习能力。
具体内容见原文的
Experiment and discussion
部分:https://doi.org/10.1016/j.compind.2024.104229