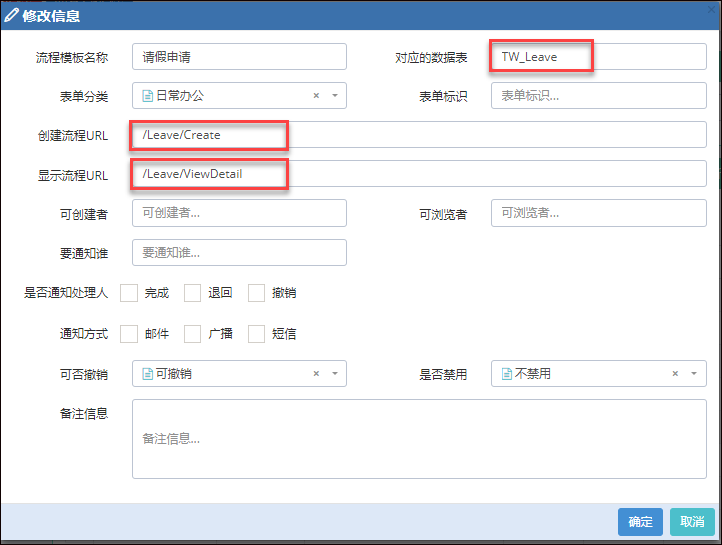
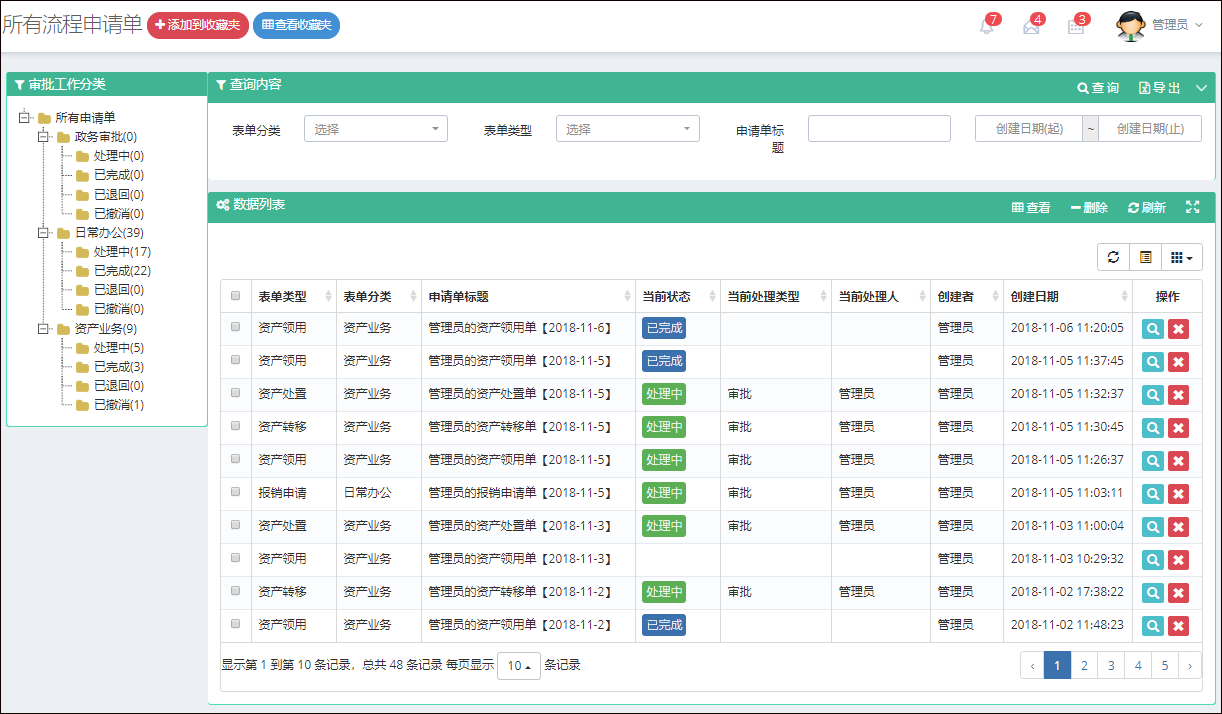
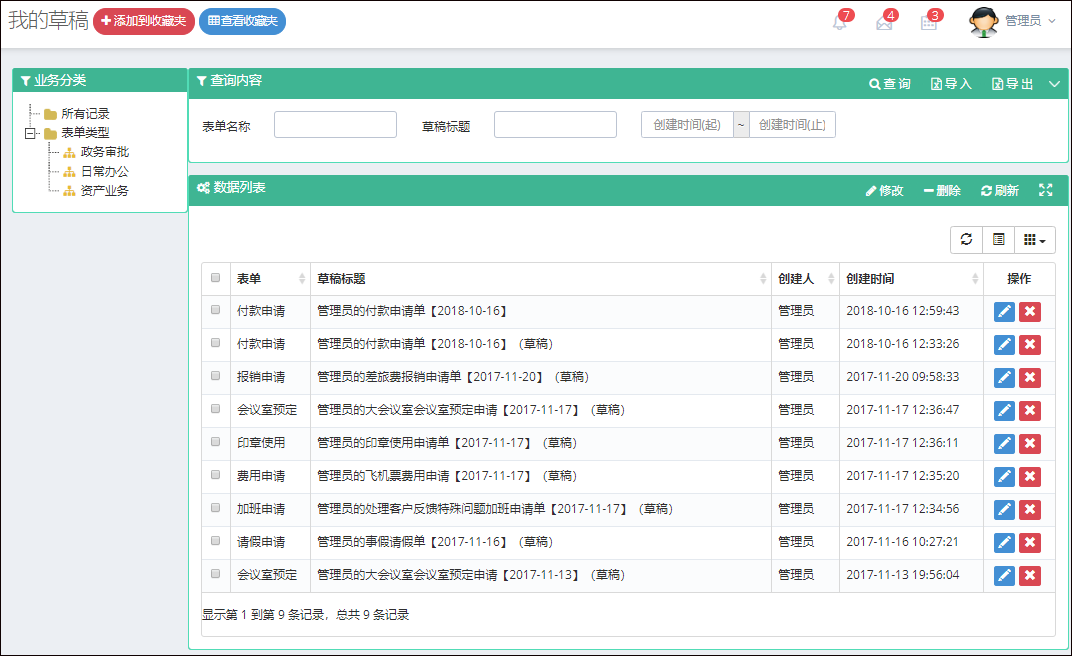
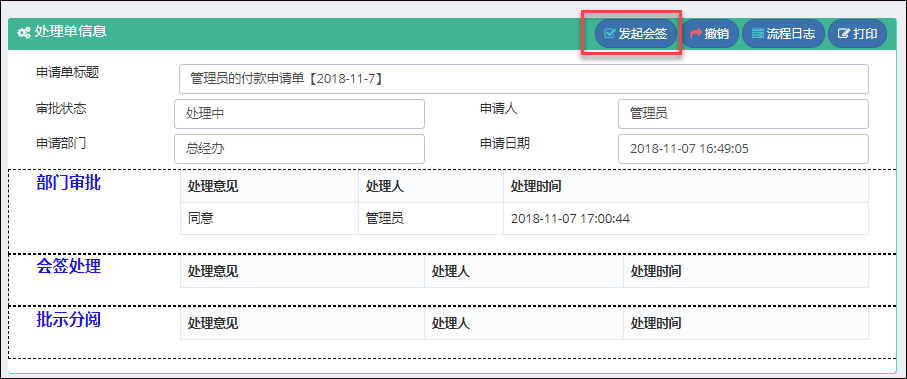
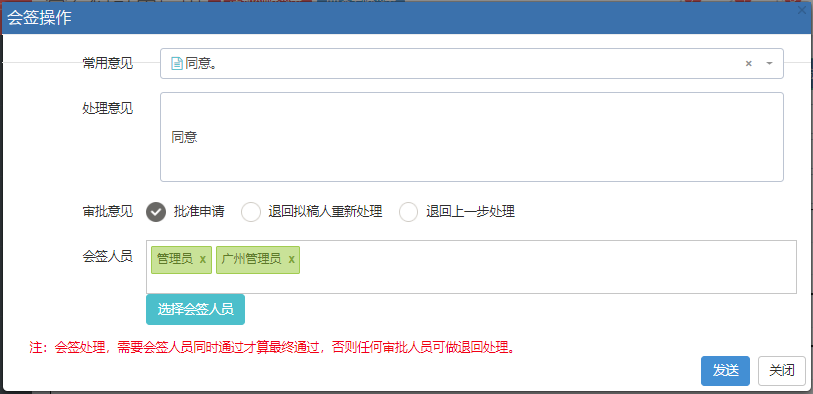
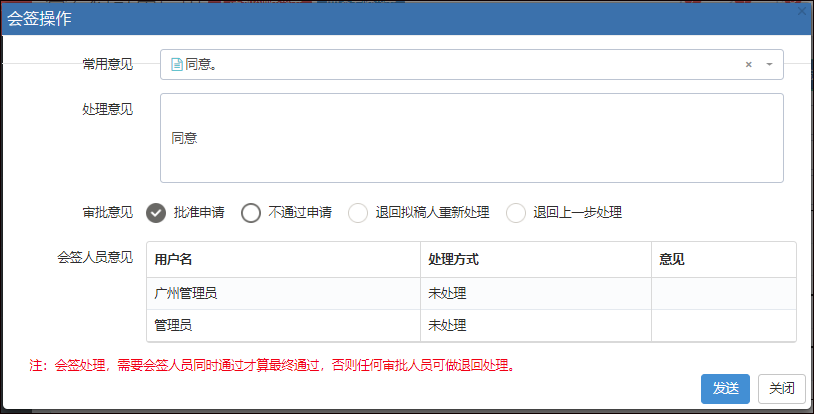
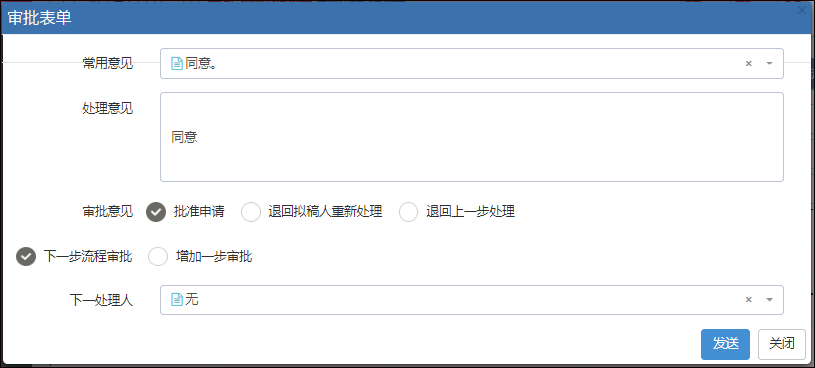
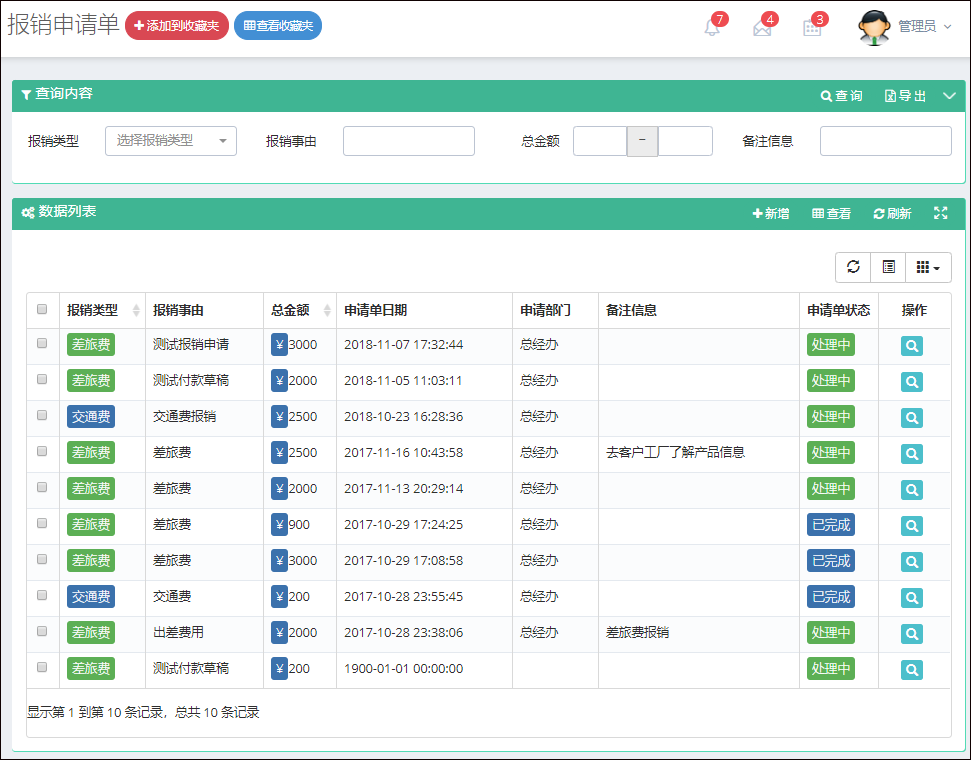
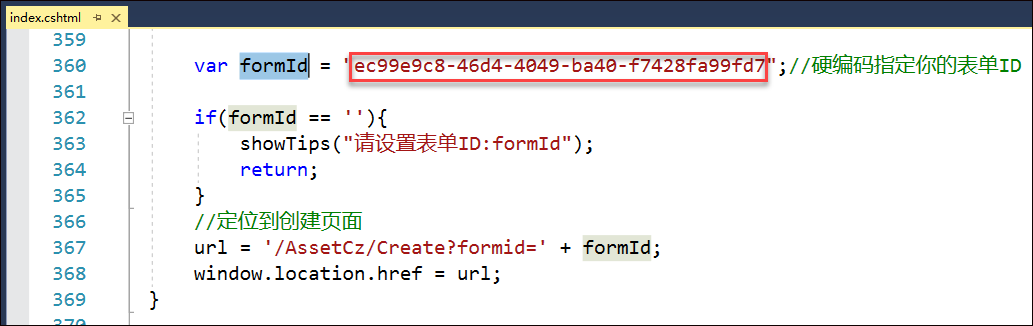
在Bootstrap开发框架的前端视图中使用@RenderPage实现页面内容模块化的隔离,减少复杂度
在很多开发的场景中,很多情况下我们需要考虑抽象、以及模块化等方面的内容,其目的就是为了使得开发的时候关注的变化内容更加少一些,整体开发更加简单化,从而减少开发的复杂度,在Winform开发的时候,往往可以通过定义基类模块、用户控件的方式实现这个目的,而在Web开发的时候,我们是否也可以利用这些特性呢?特别在MVC的视图模板里面的HTML,是否可以利用这些特点,实现变化部分的隔离,从而减少整个页面的复杂度,同时又可以提高模块的重用性呢?本篇随笔介绍在Asp.NET的MVC视图处理上,使用@RenderPage实现页面内容模块化的隔离,减少复杂度。
1、回顾Winform的界面处理方式
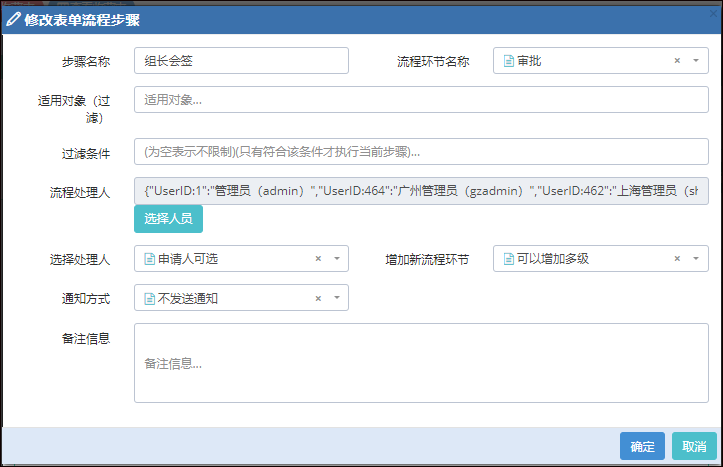
举工作流表单处理为例说明,由于在处理流程的时候,对于表单的处理,大多数情况下的规则和处理逻辑差不多,因此可以把这些不变的内容抽离到基类界面里面,对于Winform方式,我们通过继承不同的业务窗体对象就可以实现了,如下处理方式所示。
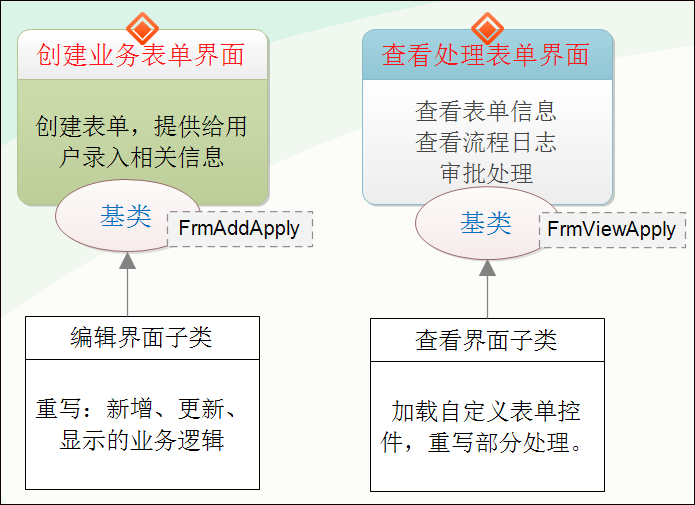
由于基类确定了,封装了大多数的处理规则,那么在子类界面的时候,需要处理的只是和业务界面有关的赋值或者读取值的操作了,我们对于不同的业务表单,做起来就很容易了,只需要把变化的部分内容放在子窗体即可。
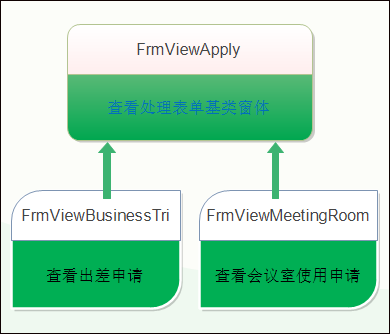
例如对于出差申请和会议室使用申请的表单,它们的窗体界面继承关系如下所示。
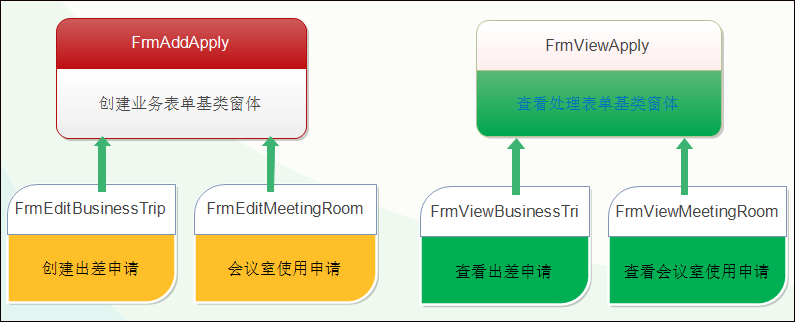
这个就是Winform界面处理的方式, 对于在Bootstrap开发框架的前端视图中,如何以类似的规则处理这些界面的分离操作呢?
答案是使用@RenderPage实现页面内容模块化的隔离。
2、使用@RenderPage实现页面内容模块化的隔离
一般在开始的时候,我们注意到了,在MVC视图中使用母版的操作中,已经隔离了页面布局相同部分,子窗体只需要定义不同部分的视图代码即可。

而进一步,我们还可以在子页面中使用@RenderPage来区分隔离不同业务界面的内容的。
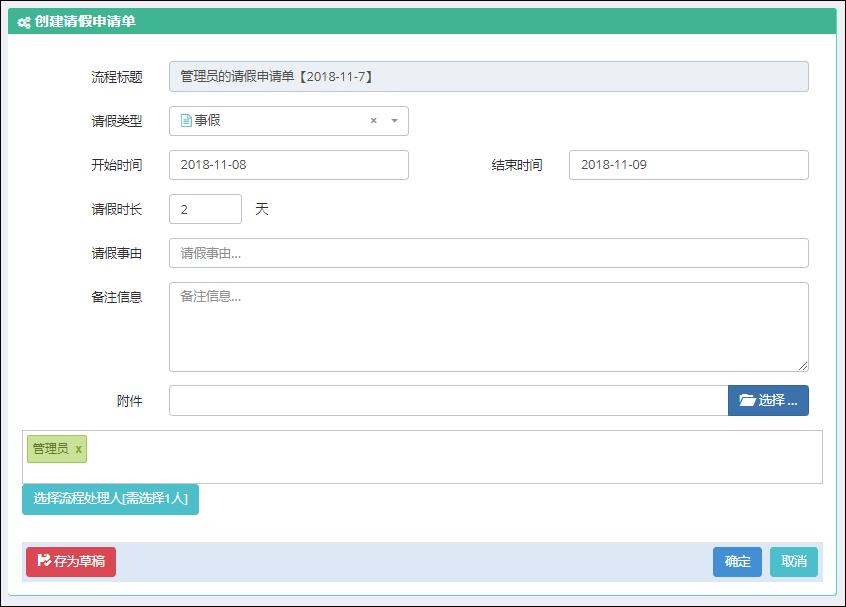
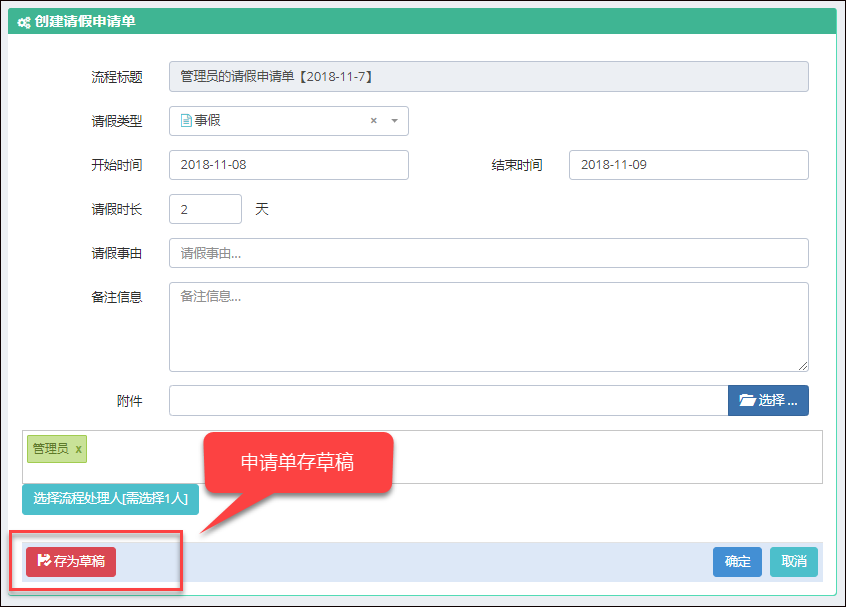
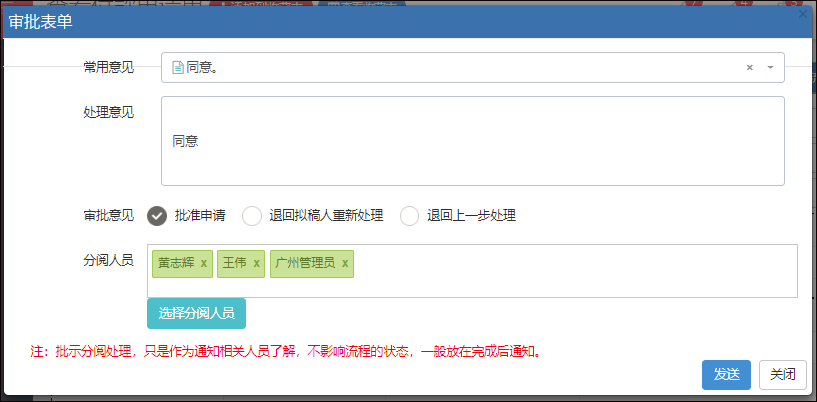
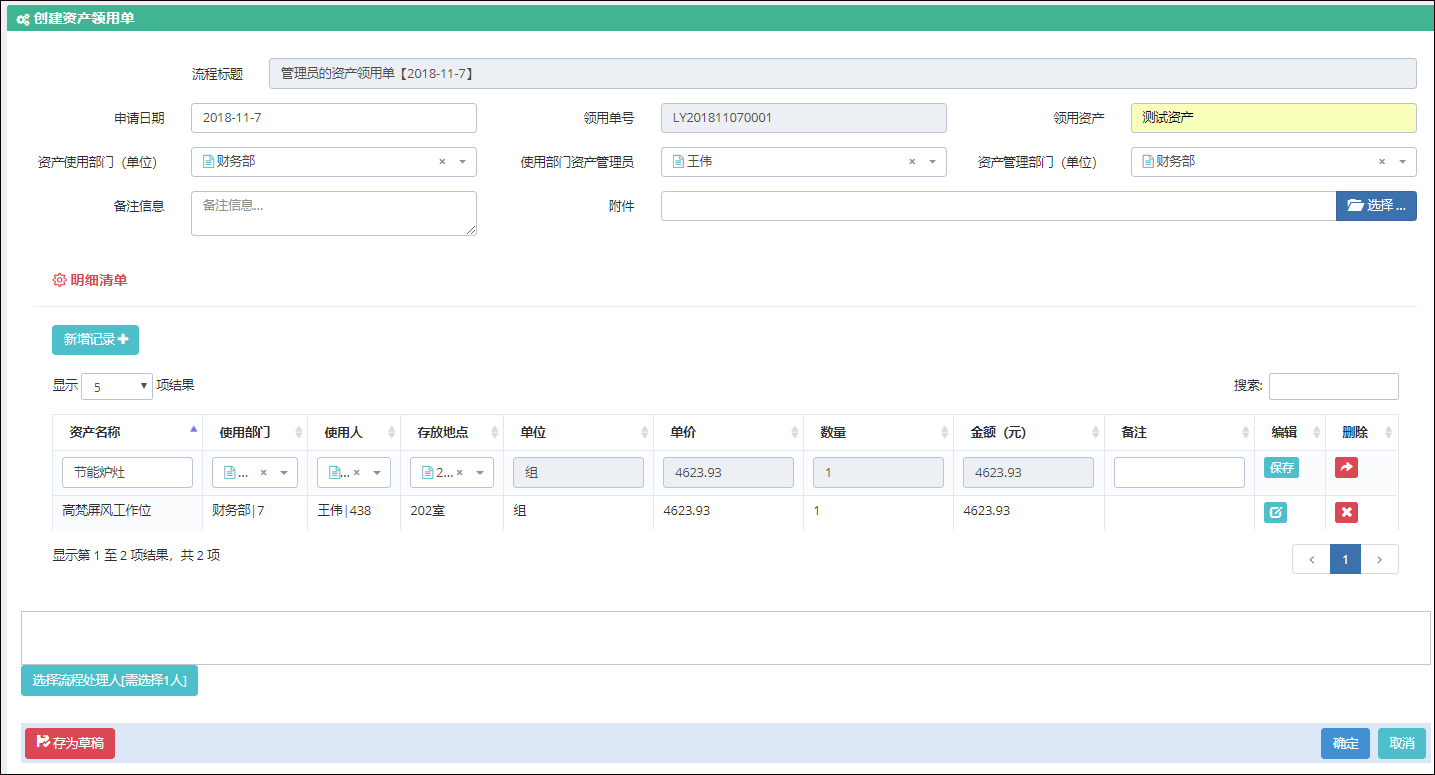
例如对于创建表单界面的视图内容。
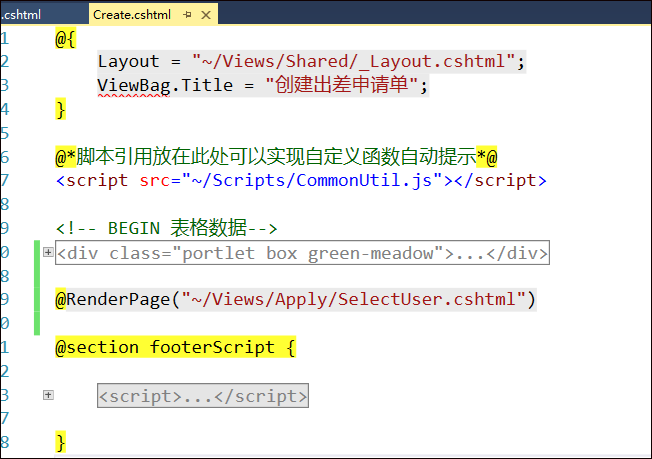
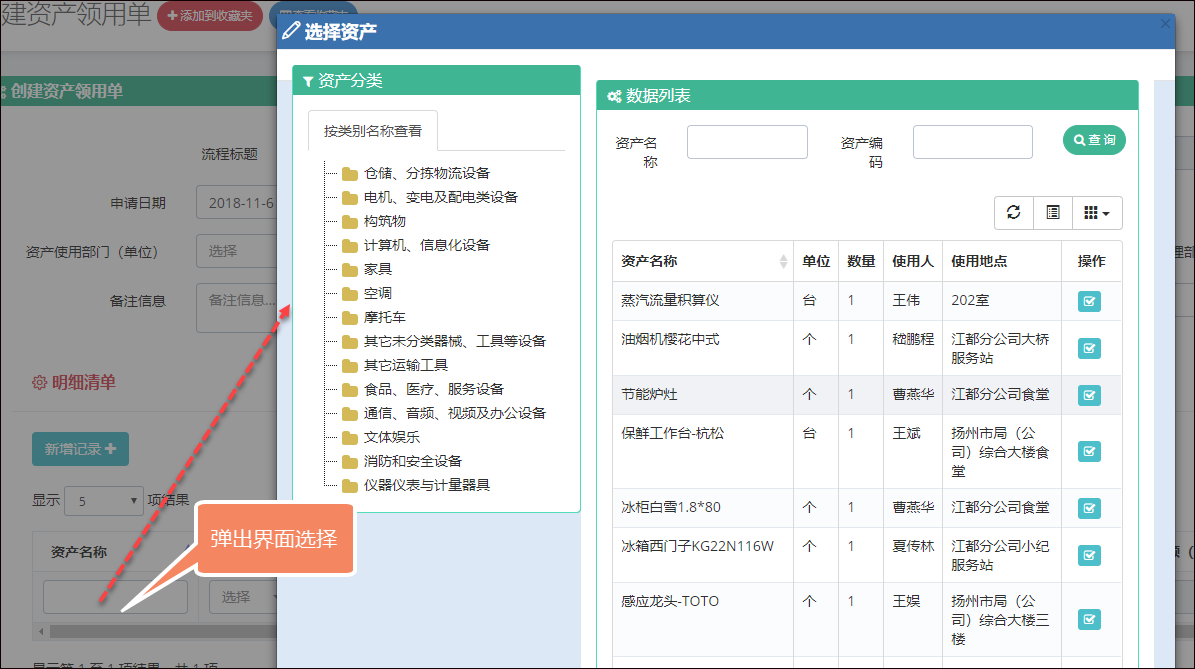
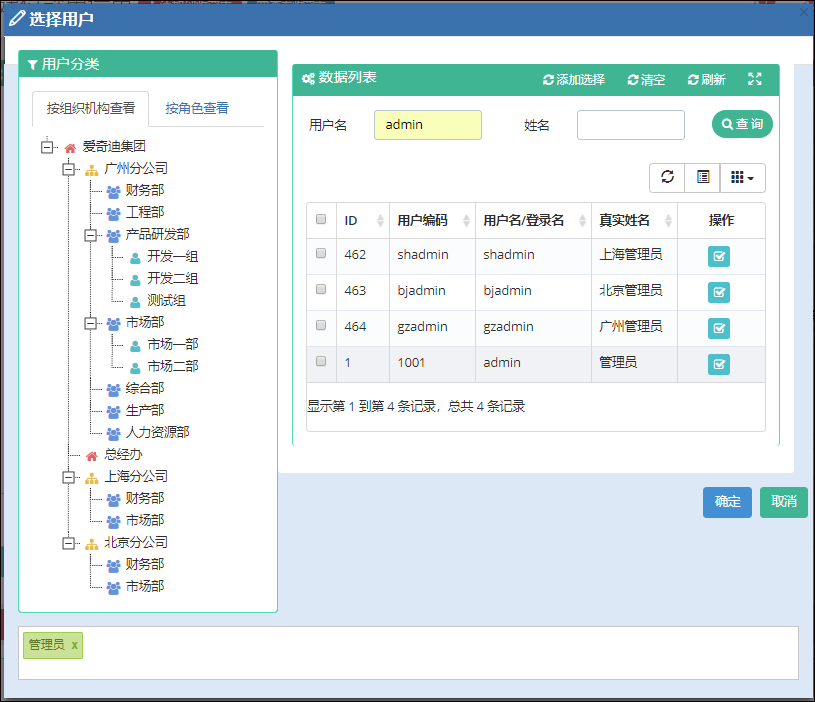
上面视图分为了几个部分的内容,一个是创建表单的界面处理,其中涉及到的选择用户界面,是一个弹出的用户选择框,由于选择用户处理是一个常见的操作,我们需要把它抽离到一个视图页面里面,可以在需要的时候,直接通过使用@RenderPage实现页面内容模块化。
@RenderPage("~/Views/Apply/SelectUser.cshtml")
当用户单击【选择流程处理人】的按钮的时候,弹出一个DIV层,这个就是我们刚才使用@RenderPage实现的选择用户界面了,这种处理方式比较弹性化,在需要的时候,包含进来即可,不用把大段大段的代码重复复制过来,方便了维护代码。

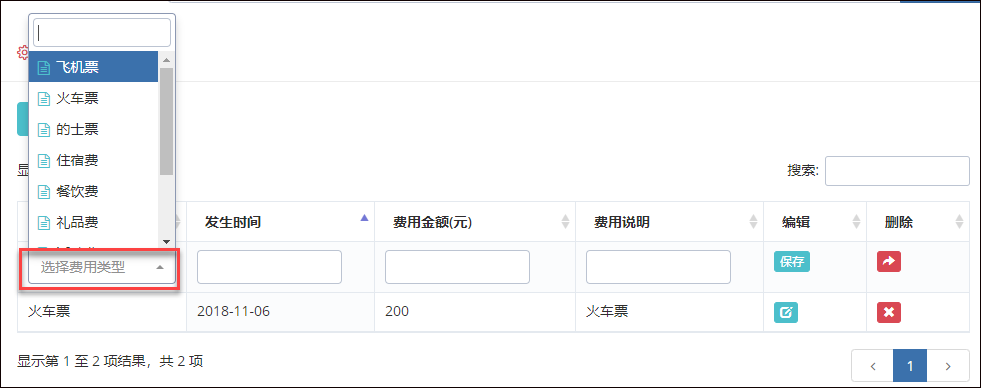
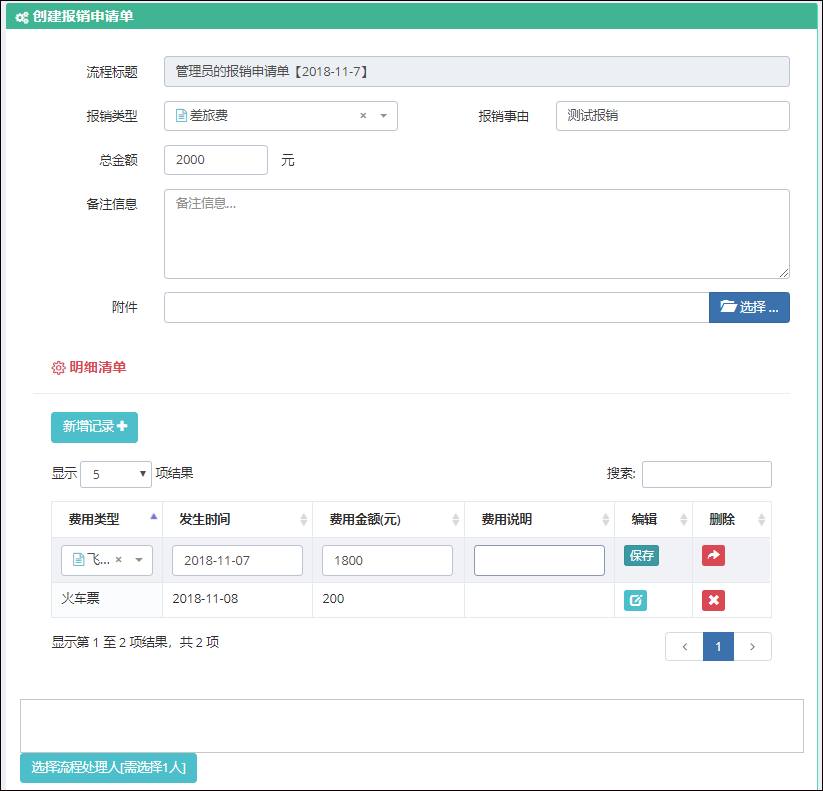
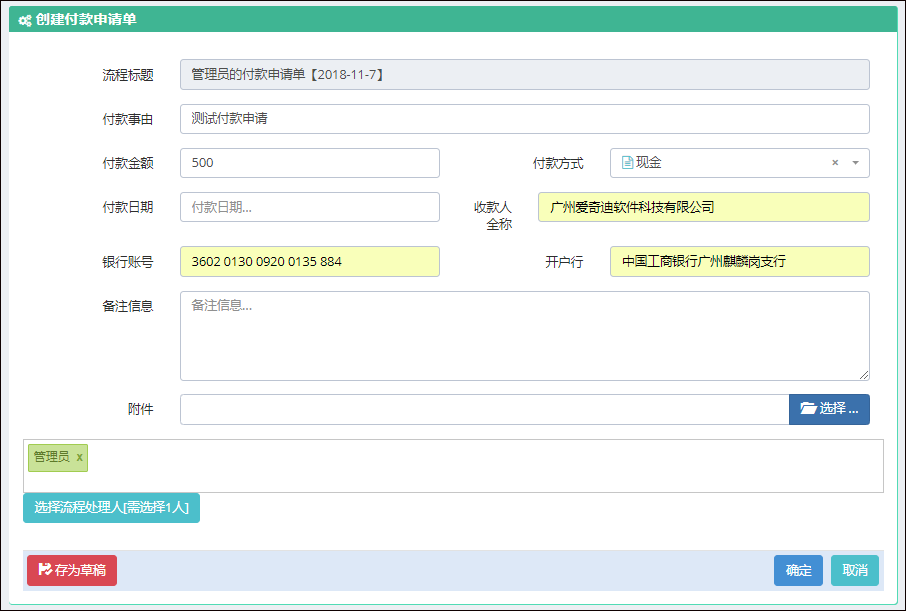
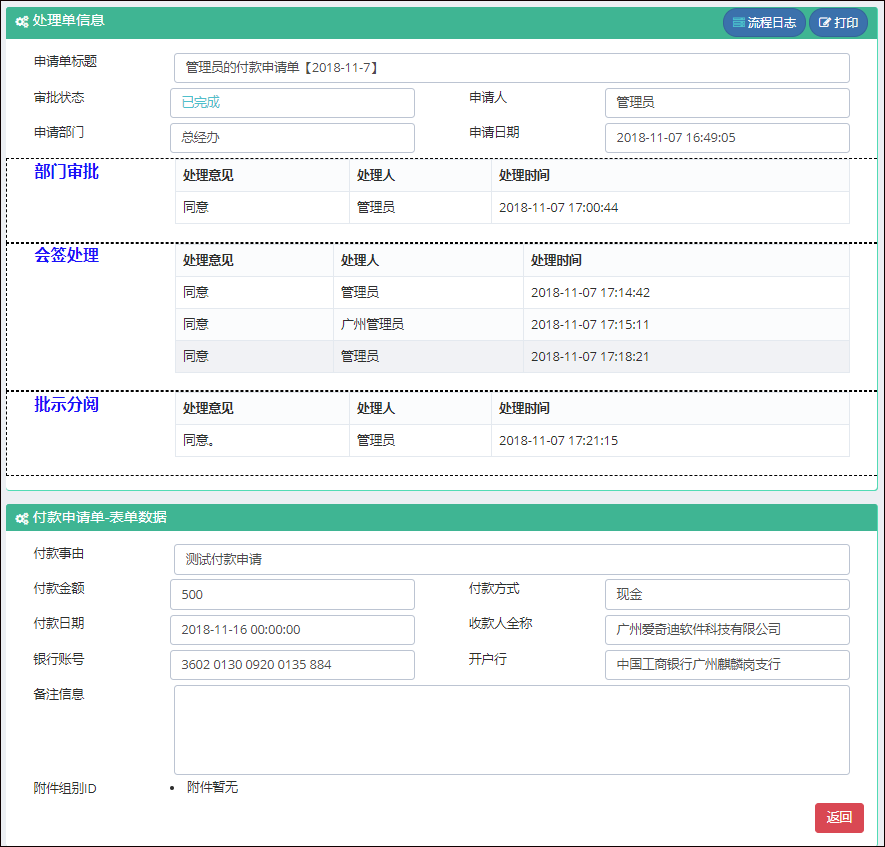
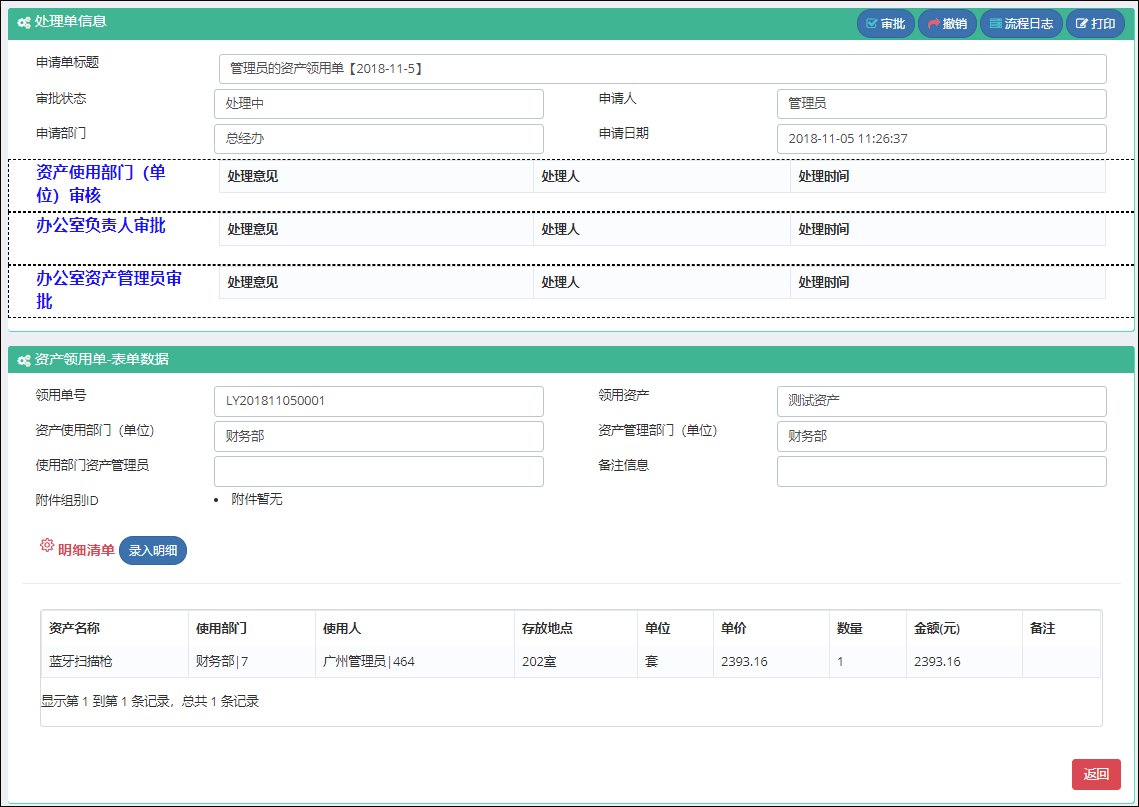
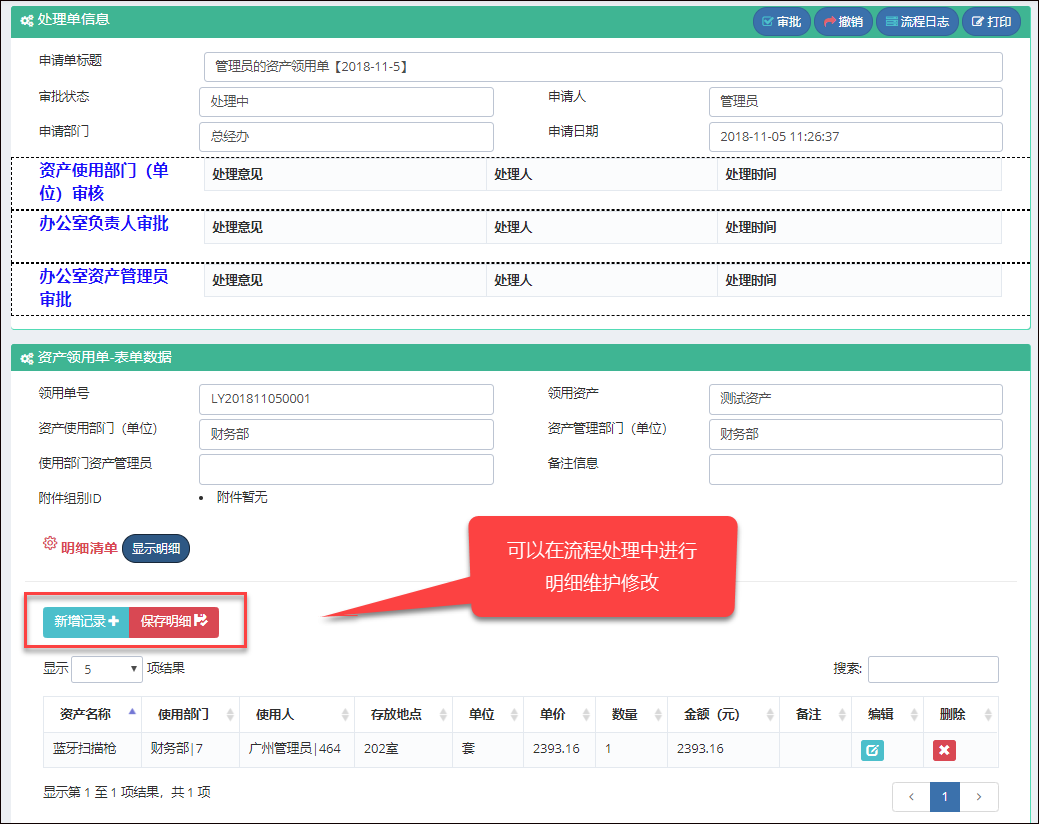
同样,对于查看表单界面来说,虽然它的界面内容比新建业务表单的界面复杂很多,但是使用的是一样的处理方式。
刚才我们看到了,在Winform界面里面,使用的是下面的视图继承的方式。
而在MVC视图界面里面,采用的是@RenderPage实现页面内容的模块化。
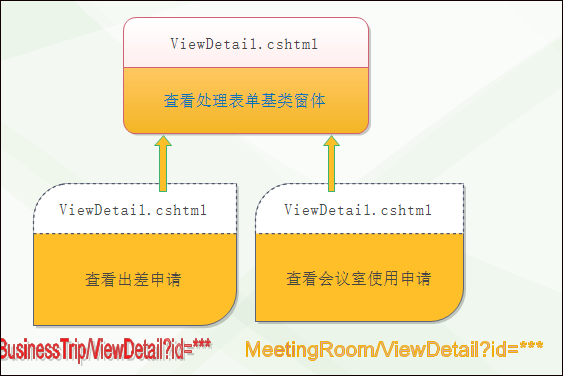
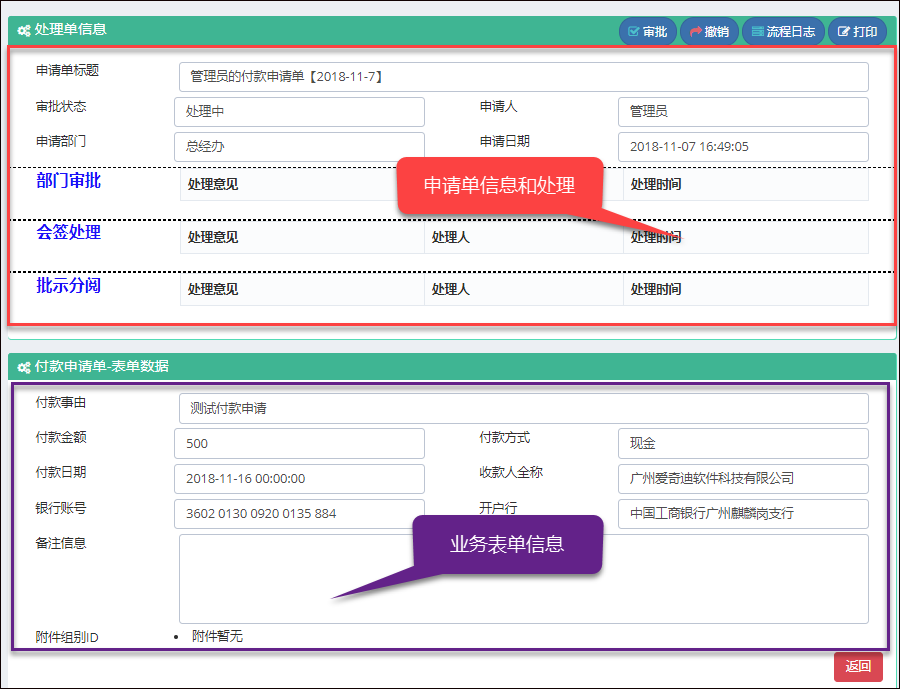
这样主视图和子视图虽然同名,但是它们是在不同的控制器名下,这样我们在父页面视图的ViewDetail.cshtml就可以封装一些常见的处理界面内容,而留下部分和具体业务表单相关的展示内容放在子页面的ViewDetail.cshtml里面即可。
在页面地址中,得到完整的页面访问路径是:/Reimbursement/ViewDetail?id=8f32231d-852e-9f16-6e5a-79031c8ec995,这个URL其实就是访问具体业务视图下的内容,但是业务视图已经引用了父页面共同的部分。
我们来看看具体业务表单中的视图页面代码,如下所示。

其中的不变的业务界面内容(理解为父窗体也可以),我们通过引用页面的方式把它包含进来。
<!--此处放置业务表单的数据呈现,方便隔离,减少复杂性-->@RenderPage("~/Views/Apply/ViewDetail.cshtml", new { applyId = Request["id"] })
这样就把它们分开维护了,共同的部分就在这个 Views/Apply/ViewDetail.cshtml 视图页面里面了。
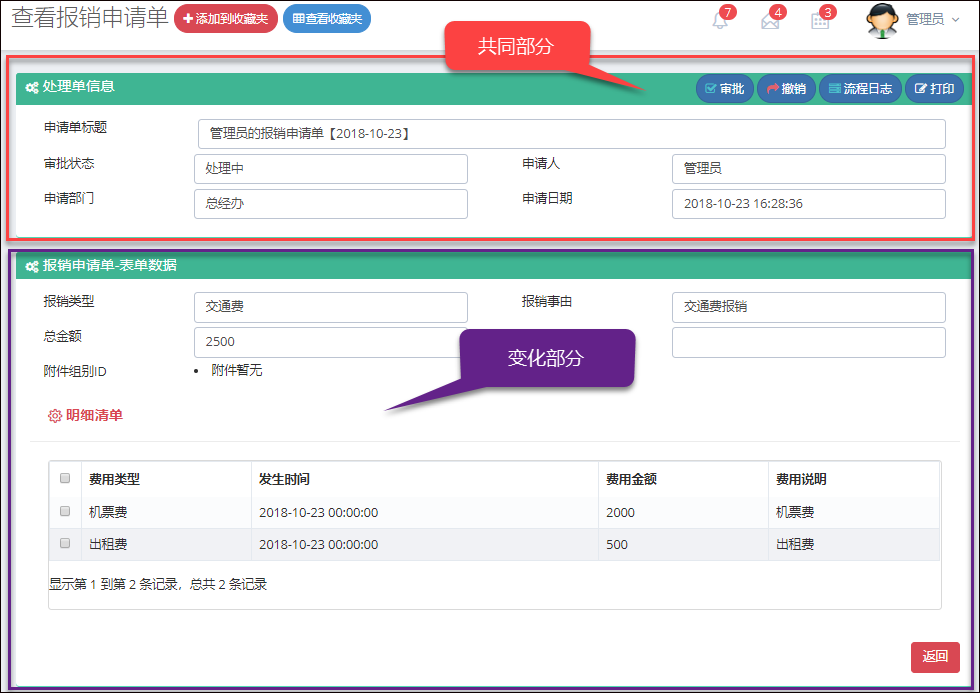
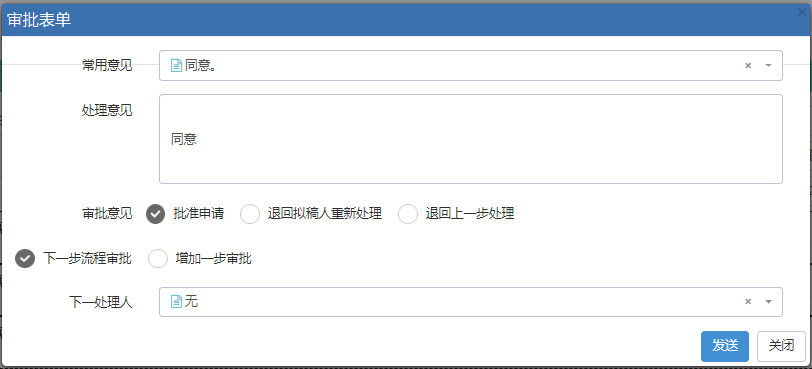
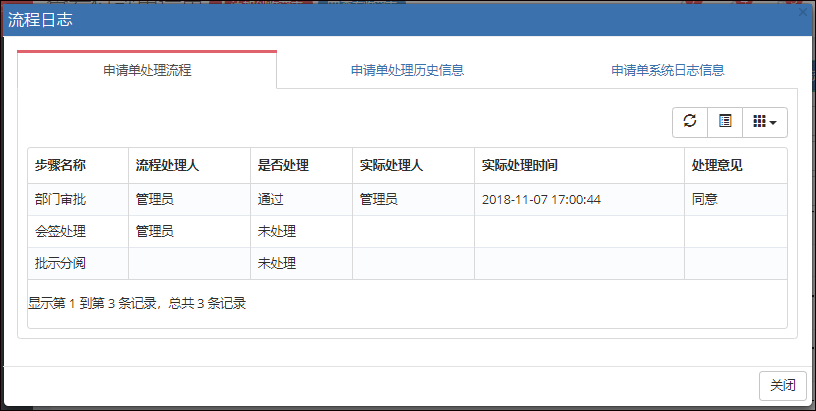
而这个共同的部分,则可以封装常规的事件处理,和界面展示,如下是界面视图的截图说明。

其中我们还可以看到通用选择用户的视图层界面
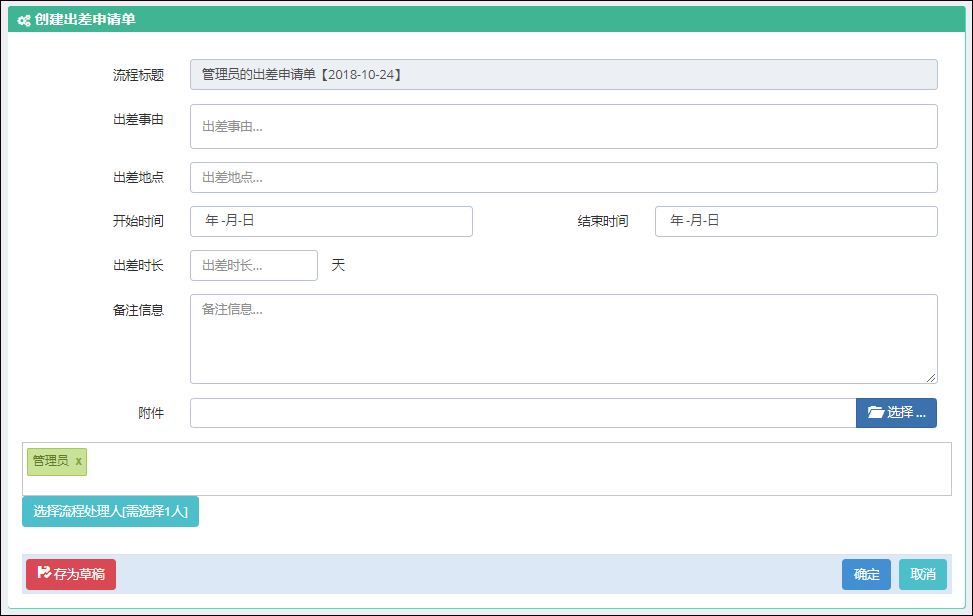
@RenderPage("~/Views/Apply/SelectUser.cshtml")最后我们来看看两个不同的视图界面效果,以烘托一下隔离界面也不影响整体效果,但是可以降低代码的维护复杂性。
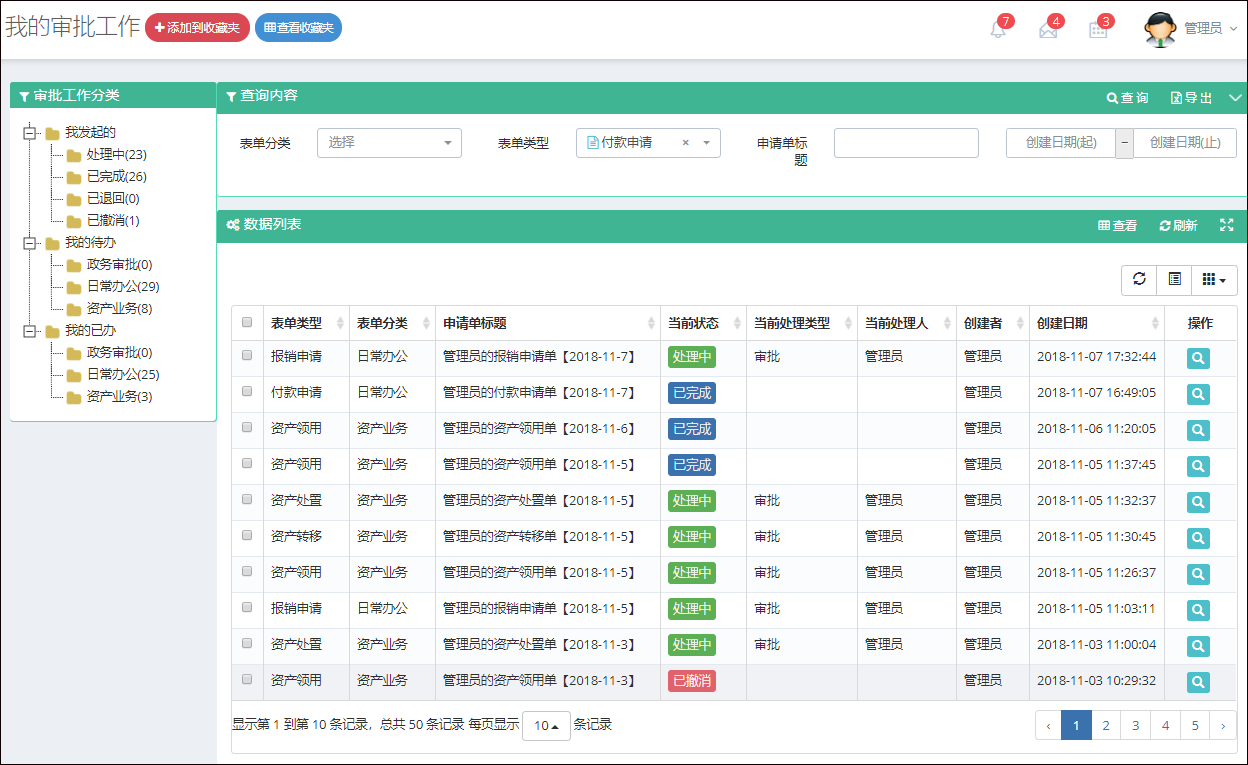
新建业务流程表单如下界面所示。
查看具体流程表单明细的界面如下所示。