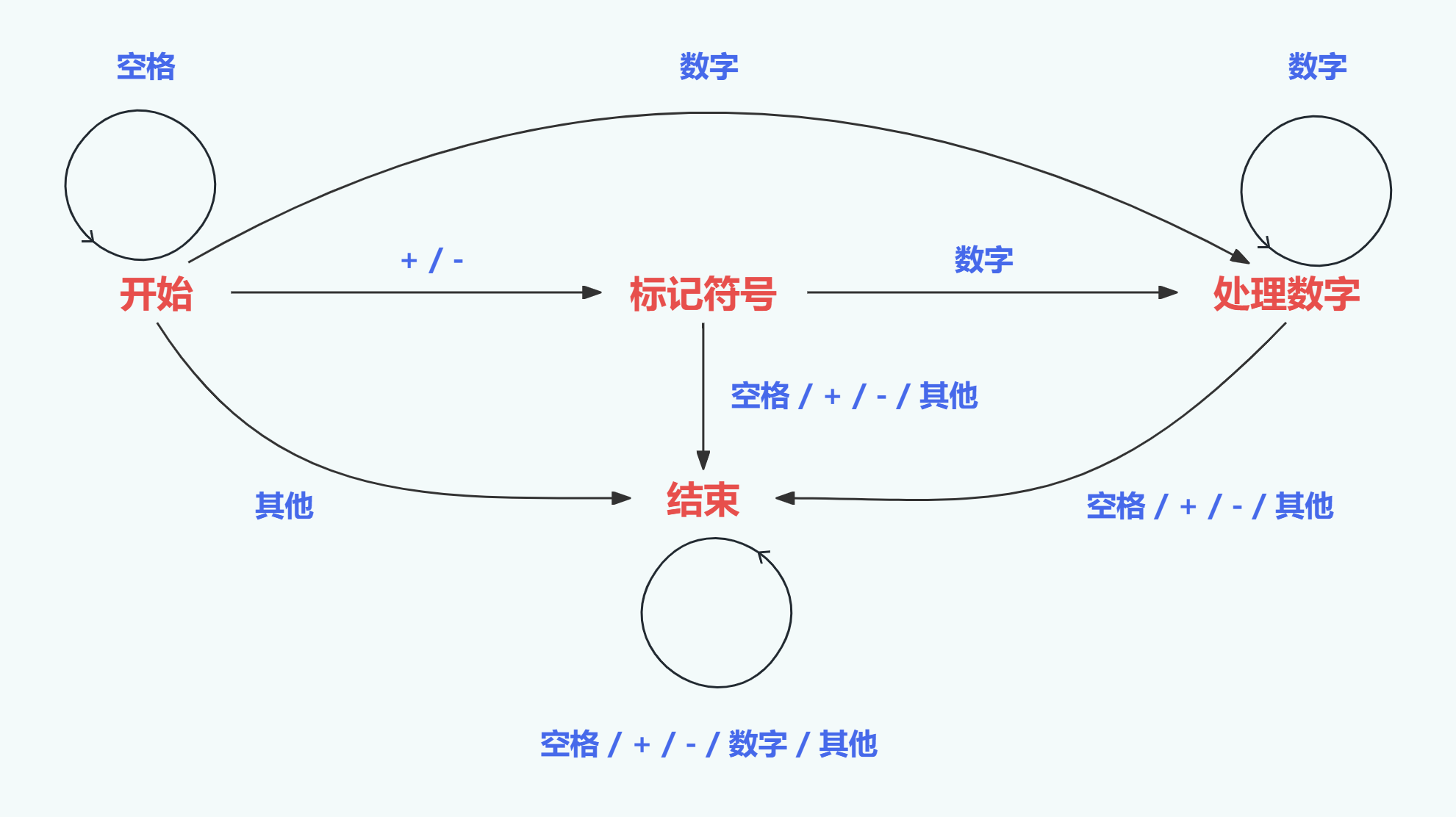
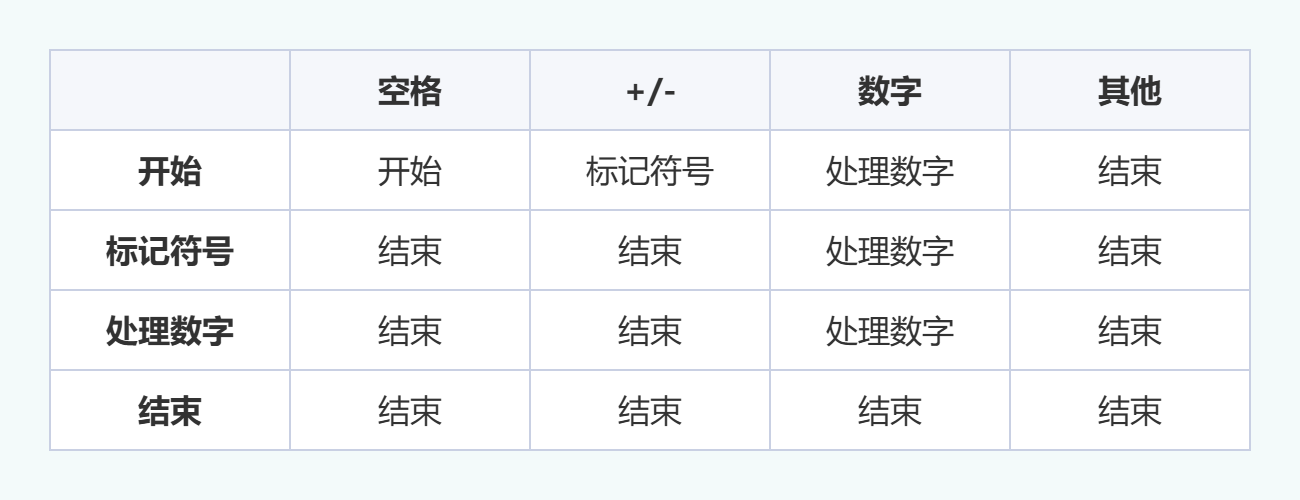
Modbus新手教程
REDISANT 提供互联网与物联网开发测试套件
#
互联网与中间件:
第七章:Modbus 总结
#
Modbus 是工业通信设备中最常用的协议之一,网关向 Modbus 设备发送命令以获取设备的值。
在 Modbus 网络上的所有设备中,通常只有一个主设备,它会向其他从设备发送不同的命令。Modbus 主设备会向网络上的所有设备广播消息,但只有分配了 Modbus 地址来接受命令的设备才会接受该命令,其余设备将拒绝该命令。基本的 Modbus 命令可以指示 RTU 更改其某个寄存器中的值、控制或读取 I/O 端口,以及命令设备发回其寄存器中包含的一个或多个值。
在工业环境中使用 Modbus 的主要原因是:
- 它是专为工业应用而开发的
- 它是公开发布的,免版税
- 它易于部署和维护
- 它移动原始位或字,而不会对供应商施加太多限制
- 在 Modbus 协议上轻松获得 SCADA 系统
Modbus 协议有多种类型:
- Modbus TCP
- Modbus RTU
- Modbus ASCII
- Modbus Plus
- Modbus Daniels
- Modbus Tek-Air
- Modbus Omniflow
其中最流行的是 Modbus RTU 和 Modbus TCP/IP。
ModbusRTU 是一种串行通信协议,可连接同一网络上的不同设备,并使它们之间可以进行通信。
ModbusTCP 涵盖使用 TCP/IP 协议通过“内部网”或“互联网”环境进行 Modbus 通信。目前,该协议最常见的用途是将 PLC、I/O 模块和网关通过以太网连接到其他简单现场总线或 I/O 网络。
总会有这样一个问题:为什么使用面向连接的 TCP/IP 协议而不是面向数据报的 UDP。主要原因是通过将单个“通信”隔离在可以识别、取消和监督的连接中来保持对单个“通信”的控制,而无需对客户端和服务器应用程序执行特定操作。这使该机制能够容忍网络性能变化,并且还提供了添加防火墙和代理等安全功能的空间。
MODBUS/TCP/IP 处理两种不同的情况。在协议层面上,连接很容易被识别。单个连接可用于执行多个独立通信。此外,TCP/IP 允许大量并发连接,因此用户决定重新使用旧连接或重新连接到常用连接。
MODBUS 内存模型/MODBUS 存储模型
#
MODBUS 具有独特的寻址模式。Modbus 设备会将其中的每个值存储在特定地址。例如,功率计将仅在 Modbus 地址 40001 处存储 Volt A-N 值。
有四种 Modbus 数据类型:
| Modbus 数据类型 | 数据格式和通用名称 | 地址起始位置 | |
|---|---|---|---|
| 线圈状态 | 位,二进制值 | 00001 | 此类数据可由 I/O 系统提供。 |
| 离散输入状态 | 二进制值 | 10001 | 此类型数据可由应用层更改。 |
| 输入寄存器 | 二进制值 | 30001 | 此类数据可由 I/O 系统提供。 |
| 保持寄存器 | 模拟值 | 40001 | 此类数据可由应用层更改。 |
MODBUS RTU 如何工作?
#
- Modbus通过设备之间的串行线路传输。最简单的设置是使用一条串行电缆连接两个设备(主设备和从设备)上的串行端口。
- 数据以一系列 1 和 0(称为位)的形式发送。每个位都以电压的形式发送。0以正电压的形式发送,1以负电压的形式发送。位发送得非常快。典型的传输速度为 9600 波特(每秒位数)。
Modbus TCP 如何工作?
#
可以使用网关上的以太网端口连接 Modbus 设备。我们可以使用任何标准 Modbus 扫描仪进行查询,以从 Modbus 设备中提取值。所有请求都通过注册端口 502 上的 TCP/IP 发送。
Modbus RTU、TCP 和 ASCII 之间有什么区别?
#
Modbus 协议定义了一个独立于底层通信层的协议数据单元 (PDU)。 Modbus RTU 是最常用的,它是 PDU 的二进制表示,在 PDU 之前有寻址,末尾附加有 CRC。Modbus ASCII 是使用所有可打印字符(通常是两倍的字节数)表示的相同 PDU。Modbus TCP 本质上与 Modbus RTU 完全相同,只是 CRC 不在应用层字节字符串中,而留给 TCP 层自动处理。RTU 数据包的 TCP 封装中还有一些额外的寻址字节。
无论协议变体如何,功能代码、寄存器编号和寻址都是相同的。寄存器类型相同,即为 Modbus 设备定义了相同的数据块。
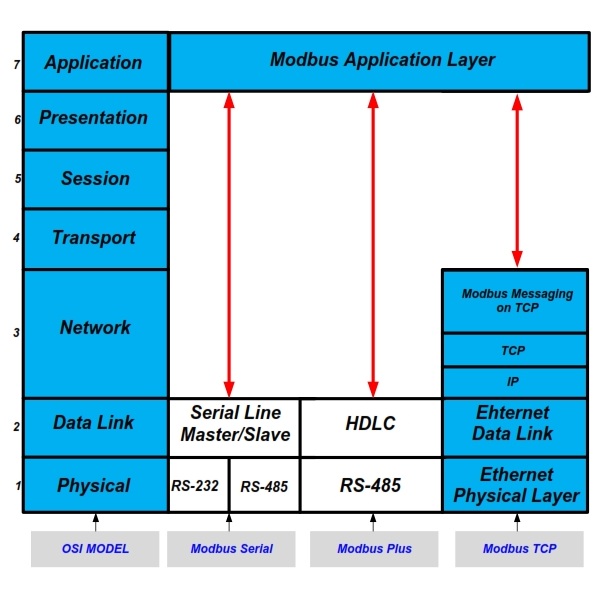
OSI 模型上的 MODBUS 协议
#
标准 Modbus 中如何存储数据?
#
- 从设备中的信息存储在四个不同的表中。
- 每个表有 9999 个数据点,可以存储不同的值。
每个线圈有 1 位,并给出 x0000 和 x9999 之间的数据地址。
每个寄存器是 1 个字 = 16 位 = 2 个字节,并且数据地址在 x0000 和 x9999 之间。
数字40001、10000等应作为位置的地址。这些数字永远不会显示在实际消息中。实际地址将是存储数字的偏移量。因此,如果设备具有 Modbus 的 ADU(应用程序定义单元)寻址,则地址 0001 将位于偏移量 40001 处,而对于 PDU(协议定义单元),它将位于偏移量 40002 处。
Modbus 中的从属 ID 或设备 ID
#
网络中的每个设备都必须分配一个唯一的单元地址,该地址可以介于 1 和 255 之间。当主设备请求数据时,它发送的第一个字节是设备/从属地址。因此,只有在发送第一个字节后,从属设备才会决定响应或忽略。
Modbus 映射
#
Modbus 映射是支持 Modbus 作为通信协议的任何特定设备的简单点列表。
Modbus 映射应包含以下信息:
- 设备读取和存储什么类型的数据(例如温度或压力)
- 数据存储在哪个地址(例如 40001 处的电压 A-N)
- 数据存储的格式是什么(例如位、UINT16、SINT16 等)
- 如果需要,提供点的工程单位。
- 有关设备是否具有 ADU 或 PDU 寻址的信息。
大多数设备都预装了 Modbus 寄存器。在某些情况下,制造商还允许操作员根据自己的要求配置设备。
MODBUS 错误检查
#
MODBUS 网络采用两种错误检查方法:奇偶校验
- 数据字符帧的奇偶校验(偶校验、奇校验或无奇偶校验)
- 消息帧内的帧校验(RTU 模式下的循环冗余校验或 ASCII 模式下的纵向冗余校验)。
奇偶校验
#
MODBUS 设备可以配置为偶校验或奇校验,或无奇偶校验。这决定了字符数据帧的奇偶校验位的设置方式。如果选择偶校验或奇校验,则计算每个字符帧数据部分中的 1 位数量。RTU 模式下的每个字符包含 8 位。然后,奇偶校验位将设置为 0 或 1,从而导致 1 位总数为偶数(偶校验)或奇数(奇校验)。
帧检查
#
LRC 纵向冗余校验(仅限 ASCII 模式)在 ASCII 传输模式下,字符帧包含一个 LRC 字段,作为 CRLF 字符之前的最后一个字段。此字段包含两个 ASCII 字符,表示除起始冒号字符和结束 CR LF 字符对之外的所有字段的纵向冗余计算结果。
CRC 错误检查(仅限 RTU 模式)
#
RTU 模式消息帧包括一种基于循环冗余校验 (CRC) 的错误检查方法。消息帧的错误检查字段包含一个 16 位值(两个 8 位字节),其中包含对消息内容执行的循环冗余校验 (CRC) 计算的结果。
Modbus 定义的功能代码:
#
主设备发送的第二个字节是功能代码。此数字告诉从设备要访问哪个表以及是否从表中读取或写入。
| 功能代码 | 操作 | 表名称 |
|---|---|---|
| 01 (十六进制 01) | 读取 | 离散输出线圈 |
| 05 (十六进制 05) | 写入单个 | 离散输出线圈 |
| 15 (十六进制 0F) | 写入多个 | 离散输出线圈 |
| 02 (十六进制 02) | 读取 | 离散输入触点 |
| 04 (十六进制 04) | 读取 | 模拟输入寄存器 |
| 03 (十六进制 03) | 读取 | 模拟输出保持寄存器 |
| 06 (十六进制 06) | 写入单个 | 模拟输出保持寄存器 |
| 16 (十六进制 10) | 写入多个 | 模拟输出保持寄存器 |
Modbus 异常代码
#
| 代码 | 名称 | 含义 |
|---|---|---|
| 01 | 非法功能 | 查询中收到的功能代码不是服务器(或从属设备)允许的操作。这可能是因为功能代码仅适用于较新的设备,并且未在所选单元中实现。它也可能表明服务器(或从属设备)处于错误状态,无法处理此类请求,例如因为它未配置并被要求返回寄存器值。 |
| 02 | 非法数据地址 | 查询中收到的数据地址不是服务器(或从属设备)允许的地址。更具体地说,参考编号和传输长度的组合无效。对于具有 100 个寄存器的控制器,PDU 将第一个寄存器的地址设为 0,将最后一个寄存器的地址设为 99。如果提交的请求的起始寄存器地址为 96,寄存器数量为 4,则该请求将成功(至少在地址方面)对寄存器 96、97、98、99 进行操作。如果提交的请求的起始寄存器地址为 96,寄存器数量为 5,则该请求将失败,并出现异常代码 0x02“非法数据地址”,因为它尝试对寄存器 96、97、98、99 和 100 进行操作,而没有地址为 100 的寄存器。 |
| 03 | 非法数据值 | 查询数据字段中包含的值不是服务器(或从属设备)允许的值。这表明复杂请求的其余部分的结构存在错误,例如隐含的长度不正确。它具体并不意味着提交存储在寄存器中的数据项具有超出应用程序预期的值,因为 MODBUS 协议不知道任何特定寄存器的任何特定值的意义。 |
| 04 | 从设备故障 | 当服务器(或从设备)尝试执行请求的操作时发生不可恢复的错误。 |
| 05 | 确认 | 专门与编程命令结合使用。服务器(或从设备)已接受请求并正在处理它,但这样做需要很长时间。返回此响应是为了防止客户端(或主设备)中发生超时错误。客户端(或主设备)接下来可以发出轮询程序完成消息来确定处理是否完成。 |
| 06 | 从设备忙 | 专门与编程命令结合使用。服务器(或从设备)正在处理长时间的程序命令。客户端(或主设备)应在服务器(或从设备)空闲时重新传输该消息。 |
| 08 | 内存奇偶校验错误 | 专门与功能代码 20 和 21 以及引用类型 6 结合使用,表示扩展文件区域未能通过一致性检查。服务器(或从设备)尝试读取记录文件,但检测到内存中的奇偶校验错误。客户端(或主设备)可以重试该请求,但服务器(或从设备)设备上可能需要服务。 |
| 0A | 网关路径不可用 | 专门与网关结合使用,表示网关无法分配从输入端口到输出端口的内部通信路径来处理请求。通常意味着网关配置不正确或过载。 |
| 0B | 网关目标设备响应失败 | 专门与网关结合使用,表示未从目标设备获得响应。通常意味着该设备不在网络上。 |
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。 原文链接:
https://blog.redisant.cn