访谈李继刚:从哲学层面与大模型对话

相信不少人和我一样,是从“
汉语新解
”这段爆火提示词中知道李继刚这位“神人”的。直到看到11月4日公众号
“数字生命卡兹克”
对继刚做了专访文章
《专访"Prompt之神"李继刚 - 我想用20年时间,给世界留一句话》
,让我初步了解到继刚其实是一位有理想、爱读书、善思考的人。这激发了我的强烈好奇心和沟通欲,于是11月13日我专程前往北京,约继刚进行了一次深度面谈。别具一格的是,作为赠送给“粉丝”的签名纪念,也是他刚使用Claude生成的一句话:
“写越简,用越广;删越多,存越精”
。

还是熟悉的地方(望京·聚宝源),还是熟悉的话题(提示工程),期间继刚思绪翻飞、滔滔不绝,完全不像一个“i人”,从这也能看出他对这个领域的专注与热爱,以至于饭后大家都意犹未尽,对我个人来说也是受益良多,故记述此文,以享诸位。
1. 提示词的本质
饭桌上火锅的温度刚上来,隐约中冒着热气,二人略作寒暄,我们便直入主题了。
继刚首先问:“你觉得提示词的本质是什么?”,并追加道:“我花了半年多的时间,终于把这个问题想明白了。”
“这个问题我尝试想过,但确实未做过深度思考,可能短时间也很难有确定结论。”,我略显尴尬并如实回复说。
“无妨,你放开想、敞开说,即便不对也没有关系,这个思考过程也很重要。”,继刚安慰我道,希望我不要有额外的压力。
我略作沉吟,细想了一会说道:“可能我现在还没法用合适的语言组织起来,但是可以用一些词描述我的理解,如自然形式的编程语言、大模型的解压密码、大模型推理方向的向导诸如此类。”
看我已绞尽脑汁,继刚决定不再“折磨”我了,回应我说:“你说的这些主要在描述提示词是什么,还是停留在表象,并非提示词的本质。就像射向标靶的无数根长矛,每根矛都指向靶心,但矛本身并不是靶心。”
“在我看来,提示词的本质,是表达。”
,继刚直接说出了他的结论。
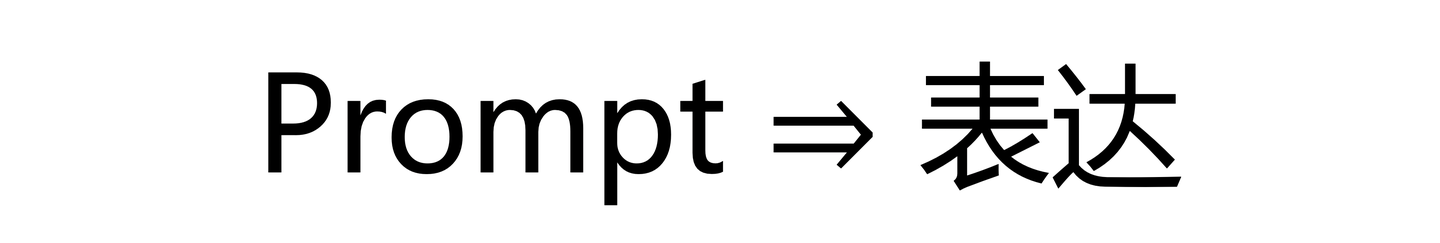
相信大多未对提示词本质做过相关思考的人,可能和我是相似的反应,面对这个结论仍是一脸懵逼,得其形,而不知其义。有一定的哲学基础的人,很清楚这就是继刚所理解的提示词的“道”,或者说是他认为的提示词的“第一性原理”。但是知“道”,并不意味着可以践“道”。
正如《道德经》所述:
有物混成,先天地生。……独立而不改,周行而不殆,……吾不知其名,强字之曰道,强为之名曰大。……
道就摆在那里,一直存在,但想做到知行合一并不容易。你可能理解“表达”是什么含义,但不一定能理解“提示词所表达的表达”是什么含义。道过于抽象,需要利用“实现”去对其进一步剖析,继刚给出了表达的第一步解析。

简而言之,本意是人的脑海中的想法,表示想做什么。文意是本意的符号化(提示词),表示想法如何描述。解意是让大模型理解人的想法,表示想法如何解读。通过这三个阶段的拆解,可以细致地还原提示词从人到大模型的过程,也就是提示词的本质。
提示词的目的是把人脑海中的想法(本意),精准无误地提供给大模型去理解(解意)。优秀的提示工程师善于通过控制提示词(文意),缓解本意与解意之间的差距。而首当其冲的,就是如何精准地描绘本意,告诉大模型,你到底想做什么?然后才是优化文意,尽量把本意无损的传递给大模型,也就是优化提示词。最后才是大模型,虽然不能通过提示词提升大模型的理解能力,但可以选择理解能力更好的大模型。
2. 如何清晰表达
继刚花了一年的时间去琢磨如何清晰地描述脑海中的想法,也就是如何描绘本意。

首先是经验,经验是想法的具象化,这是人理解想法的基础,没有体感经验的想法是空中楼阁。其次是词汇,词汇是经验在语言上的映射,是想法的符号化形式。最后是知识,知识是对词汇含义的详细解读和描述,是想法符号化为精确词汇的基础。有了以上的基础,才可以准确地表达脑海中的想法,实现清晰表达。
3. 怎样提升效果
分析如何提升大模型的问答效果,继刚给出了这样的思考。
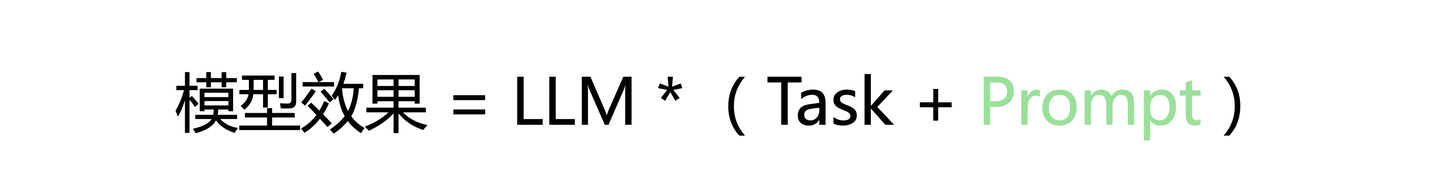
首先要认清的是,大模型是放大器,不是许愿器。种什么因,结什么果,提示词的的输入直接影响大模型的输出,这里对应解意的部分。
其次,要定义清楚要解决的问题或任务是什么,描述清楚本意。这里继刚给了一个非常形象的描述:“人要比AI凶”。说白了就是不要惧怕AI,要有信心操纵好AI,有种“战略上要藐视敌人”的意思。
最后才是提示词,通过文本把想法表达出来,对应的就是文意。提示词要足够精准,有助于大模型在Embedding语义空间的准确定位。提示词要足够简练,有助于大模型Attention机制实现重点意义的关联。
4. 提示工程方法论
以上,是继刚总结的提示工程的“道”,接下来描述提示工程的“术”,即如何写好提示词。
4.1 乔哈里视窗
提示词到底怎么写?乔哈里视窗本是关于沟通技巧的理论,继刚巧妙地将其迁移到人与大模型沟通的场景下,描绘了提示工程的基本沟通框架,有点“见人说人话,见鬼说鬼话”的莫明体感。
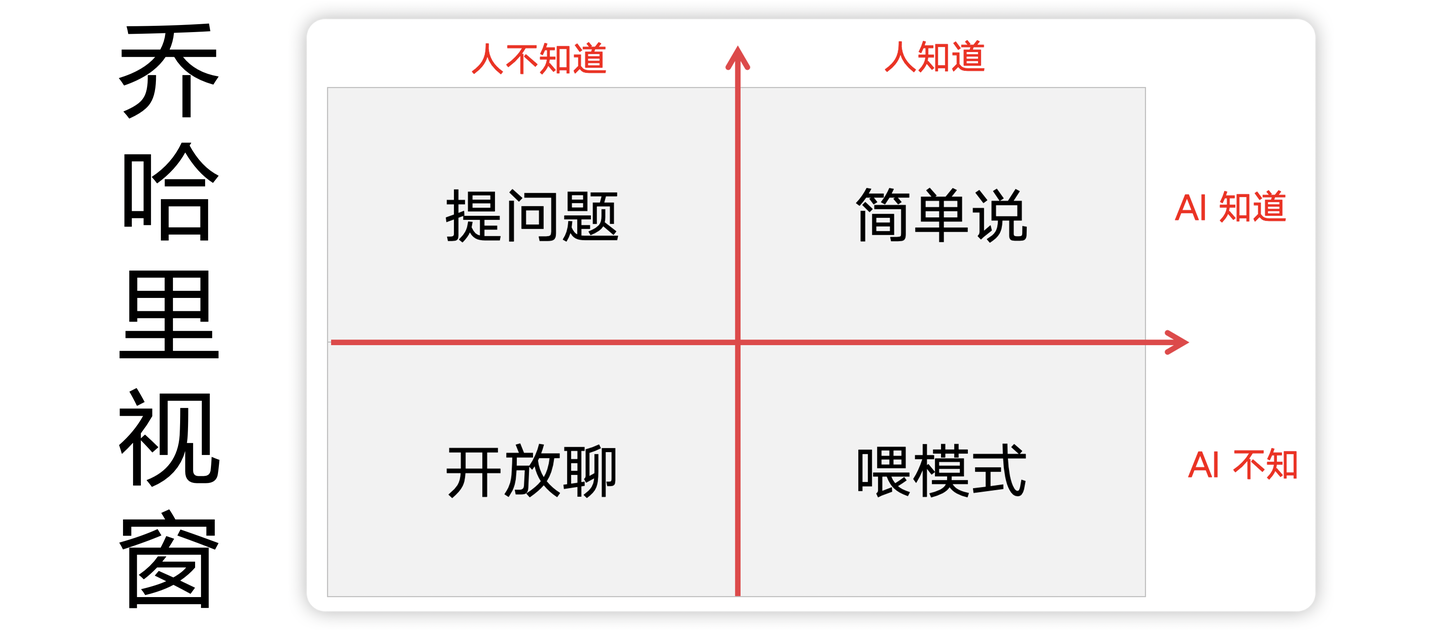
静态来看,视窗中的一、四象限所描述的是大多数人比较熟悉的方式,第二象限对提问的能力有比较高的要求,需要人不断地学习(可参考:
问题之锤
),第三象限需要人和大模型协同探索未知的领域和边界。
动态来看,未来大模型知道的会越来越多(X轴不断下移),那么对人的每个个体来说,如何丰富自身的认知边界就显得非常重要了(控制Y轴)。
最后,针对不同的象限,可以灵活地调节提示词的描述方式,从小到大,从简到繁地优化提示词的整体状态(Debug提示词),这就是提示工程的基本逻辑。
4.2 极致压缩
继刚对自己的提示词风格做过总结,去年他致力于提示词的清晰表达,而今年则专注于提示词的压缩表达。
提示词怎么简化?对于大模型来说,最容易理解的符号是向量,既而是token、单词、句子等,而人则反之。显然,单词是人和大模型沟通中最高效的形式。而作为将函数作为一等公民的LISP语言(首个函数式语言),代码形式与数据形式完全相同,这种高度的简洁性设计极度适合充当单词之间的“粘合剂”,构建最极致压缩的提示词表示,简直是天作之合!

虽然这是继刚最初的个人猜想,但经过无数的实验验证,大模型(尤其是Claude)具备理解这种提示词形式的能力,真正做到了《庄子》中所说的“得其意,忘其言”,妙到毫颠!
荃者所以在鱼,
得鱼而忘荃
;蹄者所以在兔,
得兔而忘蹄
;言者所以在意,
得意而忘言
。
4.3 点亮星星
那么,如何找到最合适的单词呢?既然大模型具备理解单词的能力,那么选用哪个单词就是很关键的问题。如前面拆解本意时提到的“词汇”与“知识”概念,尽量选用词汇的定义而非词汇的描述(可参考:
定义之矛
),让提示词中的单词“直击本质”。
这件事情说起来容易,做起来一点也不简单……
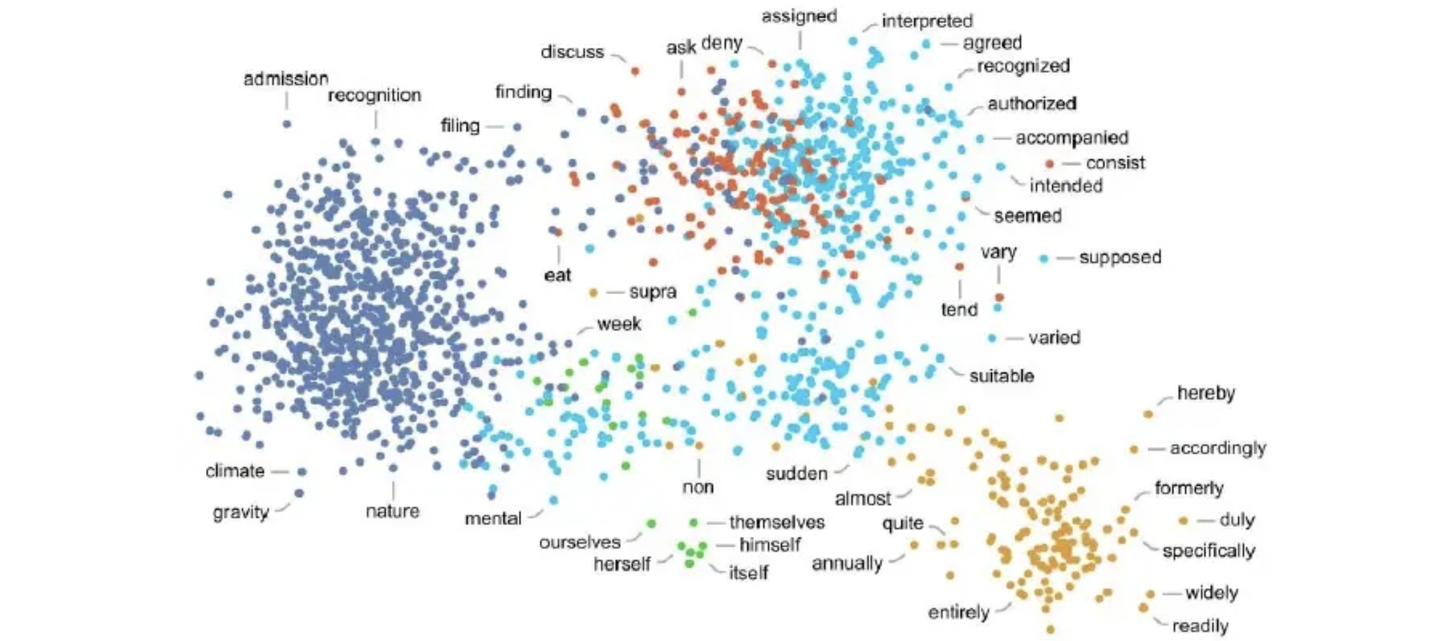
继刚常用“点亮星星”的比喻(可参考:
类比之弓
)来描述自己寻找本质词汇的过程。
想象我在一间没有灯光的屋子里(向量空间),周围都是黯淡无光的星星(单词向量),我可以喊星星的名字去点亮星星,当我按照顺序点亮星星时,它们之间的连线构成了一个星象图,大模型可以理解这个星象图的模式含义并做泛化输出,当我写提示词时,我的脑海其实在放烟花。

4.5 Read in. Prompt out.
最后,怎么写好提示词呢?大家应该可以看到,丰富的知识积累、深度的词汇理解、成熟的工程素养,对于写好提示词都至关重要,这里没有捷径,套用《卖油翁》中的话,可以表述为:“无他,惟读书尔”。多读、多思、多写,每个人才能悟出自己的提示词之“道”。
5. 提示词工程师
再回头看提示词工程师这个角色,他是一个交叉领域的岗位。借用继刚的原话:“提示词工程师,既要有提示词的写作能力,又要有工程师的素养,谜底就在谜面上。”

热爱协作的技术人,或者喜欢技术的创作者,将是提示词工程师的最佳人才画像。王小波必然是创作者的典型,而技术人中,有一类角色也将十分契合,他们叫“开源布道师”……
6. 尾记
13日和继刚聊完后,脑子一直处于发热的状态,14-15这两天又赶上全球机器学习大会,开启了“疯狂社交”模式,根本无暇整理思路。比较巧合的是,16日PEC 2024(提示工程峰会)继刚又给了《提示词的道与术》的演讲,主题与我们面谈的内容基本一致,所以文章我也直接引用了他演讲PPT中的内容作为辅助素材。
建了一个小群,大家一块聊聊提示词技术,感兴趣的同学可以进群保持关注。致未来优秀的提示词工程师们,一起加油!!!

窗外灯光点点,总算对这部分的心得做完了细致整理,还被家里人偷拍深夜码字的状态……
另外,大家也可以直接关注云中江树的“结构词AI”公众号,找到
“Prompt设计的艺术与构建AI原生产品”
分论坛的直播回顾视频直接观看(第47min开始)。
7. 参考资料
- 专访"Prompt之神"李继刚 - 我想用20年时间,给世界留一句话:
https://mp.weixin.qq.com/s/JT2oOG2SYw2pDYEHlEmcyQ - Claude Prompt: 汉语新解:
https://mp.weixin.qq.com/s/7CYRPFQxi37ONTlX0hfzRQ - Claude Prompt:问题之锤:
https://mp.weixin.qq.com/s/KlkomVKEYKjVAb6NEXcjSg - Claude Prompt:定义之矛:
https://mp.weixin.qq.com/s/eNcqU-_-8SMpVBXAcgeQRQ - Claude Prompt:类比之弓:
https://mp.weixin.qq.com/s/p1viD22cPtD3iLzOIb_FMg - 关于说话的一切:
https://weread.qq.com/book-detail?type=1&senderVid=4000012&v=10132d20813ab77a6g012034 - 为什么伟大不能被计划:
https://weread.qq.com/book-detail?type=1&senderVid=101531&v=0bf32020813ab7e6bg016510 - 深度学习的数学:
https://weread.qq.com/web/bookDetail/01d327c071a122c701d71f3 - 拐点:
https://weread.qq.com/web/bookDetail/08732220811e7ef55g012f82 - GPT图解大模型是怎样构建的:
https://weread.qq.com/web/bookDetail/e0d32f10811e7ee55g010619 - 这就是ChatGPT:
https://weread.qq.com/web/bookDetail/74332a90813ab86c4g019d98