vue2-脚手架
Vue 脚手架是 Vue 官方提供的标准化开发工具(开发平台)
使用脚手架
安装脚手架
npm install -g @vue/cli使用脚手架创建一个项目
vue create vue-demo进入目录启动服务
npm run serve
脚手架结构
├── node_modules
├── public
│ ├── favicon.ico: 页签图标
│ └── index.html: 主页面
├── src
│ ├── assets: 存放静态资源
│ │ └── logo.png
│ │── component: 存放组件
│ │ └── HelloWorld.vue
│ │── App.vue: 汇总所有组件
│ │── main.js: 入口文件
├── .gitignore: git版本管制忽略的配置
├── babel.config.js: babel的配置文件
├── package.json: 应用包配置文件
├── README.md: 应用描述文件
├── package-lock.json:包版本控制文件
├── vue.config.js:脚手架配置文件
// 默认的main.js
// 整个项目的入口文件
// 引入vue
import Vue from 'vue'
// 引入App组件,所有组件的父组件
import App from './App.vue'
// 关闭vue的生产提示
Vue.config.productionTip = false
// 创建vue实例对象 vm
new Vue({
// 将App组件放入容器中
render: h => h(App),
}).$mount('#app') // 挂载app容器
<!-- 默认index文件-->
<!DOCTYPE html>
<html lang="">
<head>
<meta charset="utf-8">
<!-- 针对ie浏览器的配置,让ie浏览器以最高级别渲染页面-->
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<!-- 开启移动端的理想视口-->
<meta name="viewport" content="width=device-width,initial-scale=1.0">
<!-- 配置页签图标 -->
<link rel="icon" href="<%= BASE_URL %>favicon.ico">
<!-- 配置网页标题-->
<title><%= htmlWebpackPlugin.options.title %></title>
</head>
<body>
<!-- 浏览器不支持js 的时候, noscript中的元素会被渲染-->
<noscript>
<strong>We're sorry but <%= htmlWebpackPlugin.options.title %> doesn't work properly without JavaScript enabled.
Please enable it to continue.</strong>
</noscript>
<!-- 容器-->
<div id="app"></div>
<!-- built files will be auto injected -->
</body>
</html>
render函数
在main.js文件中,
import Vue from 'vue’
,此处导入的vue不是完整的,缺少模板解析器,所以不能使用template属性去设置组件标签
, vue代码完成之后是要打包的, 其中少不了vue的核心代码,当我们打包好之后, 我们其实是不需要再来解析模板的, 那么, vue的核心代码中的模板解析器根本用不着, 所以,vue为了使代码的体积减少, 就去掉了模板解析器,但是我们开发的时候, 又要使用, 所以就创建了一个 render 方法来解析模板,总之, 它的目的就是让打包后的代码体积尽量小,提升性能
关于不同版本的Vue:
vue.js与vue.runtime.xxx.js的区别:
(1).vue.js是完整版的Vue,包含:核心功能+模板解析器。
(2).vue.runtime.xxx.js是运行版的Vue,只包含:核心功能;没有模板解析器。因为vue.runtime.xxx.js没有模板解析器,所以不能使用template配置项
需要使用render函数接收到的createElement函数去指定具体内容
render
函数主要用于创建虚拟 DOM 节点(VNode)。它是一个 JavaScript 函数,接收一个名为
createElement
(通常缩写为
h
)的函数作为参数。这个
createElement
函数用于构建 VNode
render(createElement){
// 创建一个节点 <h1>hello world</h1> 并在页面渲染
return createElement("h1","hello world")
}
// 将App组件传入,将APP中的template模版交给render渲染
// 简写的箭头函数
render: h => h(App),
脚手架默认配置
脚手架默认隐藏了webpack的相关配置,使用下面命令将相关配置输出为一份js文件供查看(仅查看)
vue inspect > output.js
默认情况下,public文件夹下的index、favicon ,src下的App.vue和main.js不允许修改,vue默认是从该路径找对应的文件
可修改的配置
,可以修改脚手架规则,进行个性化定制
ref属性
被用来给元素或子组件注册引用信息(id的替代者)
应用在html标签上获取的是真实DOM元素、组件标签上是组件实例对象(vc)
<template>
<div id="app">
<!-- 设置标题DOM的ref是title-->
<h1 ref="title">标题</h1>
<button @click="showDOm">点击获取标题的DOM元素</button>
<!-- 设置组件ref是studen-->
<StudentComp ref="student"></StudentComp>
</div>
</template>
<script>
import StudentComp from "./components/StudentComp.vue";
export default {
name: 'App',
components: {
StudentComp
},
data() {
return {name: "app->vue", address: "Beijing"}
},
methods: {
showDOm() {
// 这里的this是vc
//模版标签里ref="title", 在vc上面的结构是 在vc的$refs对象里面有title的key,value就是对应的DOM
console.log(this.$refs.title)
// 在组件标签上面使用ref,这里获取到的是对应组件的实例对象
console.log(this.$refs.student)
}
}
}
</script>
props配置
可以让组件接收外部传过来的数据,动态传参
只接受参数
<script> export default { name: "StudentComp", data: function () { return {name: "vue", address: "Beijing"} }, // 数组形式->使用props选项,配置city和age参数 props:["city","age",] } </script> <template> <div class="student"> <h1>名字:{{ name }}</h1> <h1>地址:{{ address }}</h1> {{city}} <!-- 接受到age之后加1,age默认是字符串,所以不会正常计算,只会字符串拼接 --> {{age + 1}} </div> </template>
<!-- 在使用组件标签的时候,传入对应的数据 --> <StudentComp city="beijing" age="18"></StudentComp> <!-- 如果要传入的是个表达式 ,用数据绑定语法 :age="xxxxx"-->接收参数-限制类型
<script> export default { name: "StudentComp", data: function () { return {name: "vue", address: "Beijing"} }, // 对象形式 props: { city: String, // 定义city参数,字符串类型 age: Number // 定义age参数,Number类型 } } </script> <template> <div class="student"> <h1>名字:{{ name }}</h1> <h1>地址:{{ address }}</h1> {{ city }} <!-- age限制是Number类型,可以正常计算--> {{ age + 1 }} </div> </template>接收参数-类型限制-必填限制-默认值设置
// 对象嵌套对象 props:{ city:{ type:String, // 字符串类型 required:true // 必填项,如果不传递,默认是false }, age:{ type:Number,// number类型 required: false,// 非必填 default:18 // 默认值,如果不传参,走默认项 } }props是只读的
props是只读的,模版标签中传递什么就是什么,Vue底层会监测你对props的修改,如果进行了修改,就会发出警告,若业务需求确实需要修改,那么请复制props的内容到data中一份,然后去修改data中的数据
// props的渲染优先级比data高 // 页面使用myCity进行渲染,myCity的初始值是props的city,从模版标签传入 // 修改myCity即修改页面效果 data: function () { return {name: "vue", address: "Beijing",myCity:this.city} }通过props传递数据
<template>
<div>
<Student :demo="demo"></Student>
</div>
</template>
<script>
import Student from "@/components/Student.vue";
export default {
name: 'App',
components: {
Student
},
methods: {
demo(name) {
console.log("子组件data name", name)
}
}
}
<script>
export default {
// eslint-disable-next-line vue/multi-word-component-names
name: "Student",
// 定义props属性
props:["demo"],
data: function () {
return {name: "vue", address: "Beijing"}
},
methods: {
sendStudentName(){
this.demo(this.name)
}
}
}
</script>
mixin混入
可以把多个组件共用的配置提取成一个混入对象
第一步:定义混合
// mixin.js文件 export const mixin = { // 回调 methods:{ showName(){ alert(this.name) } } }第二步:组件配置
<script> // 导入mixin import {mixin} from "@/mixin"; export default { name: "StudentComp", data: function () { return {name: "vue", address: "Beijing"} }, // 配置混合(局部混入),导入的mixin // 如果有多个 ,数组可以配置多个 mixins:[mixin] } </script>
Vue.mixin(mixin) // 全局混入第三部:正常使用
<button @click="showName">按钮</button>一个mixin对象可以报警data、methods、computed等各种组件选项
理论上可以组件配置所有选项都可以使用,template和el可能会存在一定限制和合并问题
export const mixin = { // 回调 methods: { showName() { alert(this.name) } }, mounted() { console.log("test") }, data() { // 如果混合和组件内的data使用了同样的属性,以组件内部为主,如果不相同,两个会组合起来 return {baseUrl: "xxxx"} }, // 计算 computed:{ }, }
插件
功能:用于增强Vue
本质:包含install方法的一个对象,install的第一个参数是Vue,第二个以后的参数是插件使用者传递的数据
定义插件
export const TestPlugins = { // 如果需要自定义参数,在Vue后传参即可 install(Vue){ // 可以自定义一些方法 // 过滤器 Vue.filter() // 混入 Vue.mixin() // 在Vue原型上添加方法(vm和vc都可以用) Vue.property.say = ()=>{} } }使用插件
import {TestPlugins} from "@/plugins"; Vue.use(TestPlugins)
scoped样式
多个不同的组件编写的样式,选择器最终是汇总在一起的,有可能出去类名、ID名字冲突,scoped可以让样式在局部生效,防止冲突,原理是在对应的元素上加上一个 data-v-xxxxx,唯一标识
<style scoped ></style>
组件化编码流程
- 实现静态组件:抽取组件,使用组件实现静态页面效果
- 拆分静态组件:组件要按照功能点拆分,命名不要与html元素冲突
- 展示动态数据:数据类型、名称、保存在哪个组件等等
- 考虑好数据的存放位置,数据是一个组件在用,还是一些组件在用
- 一个组件在用:放在组件自身即可
- 一些组件在用:放在他们共同的父组件上(状态提升)
- 交互:绑定事件监听等等
- props适用于:
- 父组件 ==> 子组件 通信
- 子组件 ==> 父组件 通信(要求父先给子一个函数)
浏览器本地存储
存储储内容大小一般支持5MB左右(不同浏览器可能还不一样)
LocalStorage
LocalStorage存储的内容,需要手动清除才会消失,关闭浏览器不会消失
// 本地存储-> 存储到Local Storage // key和value都是字符串,若value不是字符串,会默认调toString方法 // 如果key已经存在,更新数据 localStorage.setItem("name","vue") // 读取数据,如果没有该key,读取的是null localStorage.getItem("name") // 删除数据 localStorage.removeItem("name") // 清空数据-所有的数据 localStorage.clear()sessionStorage
SessionStorage存储的内容会随着浏览器窗口关闭而消失
// 本地存储-> 存储到Session Storage sessionStorage.setItem("name","vue") // 读取数据,如果没有该key,读取的是null sessionStorage.getItem("name") // 删除数据 sessionStorage.removeItem("name") // 清空数据-所有的数据 sessionStorage.clear()
组件的自定义事件
在 Vue 中,组件自定义事件是一种用于组件间通信的重要机制。它允许子组件向父组件传递信息。当子组件发生某些操作或者状态变化时,可以通过触发自定义事件来通知父组件
例如,在一个包含表单组件(子组件)和显示数据组件(父组件)的应用中,当用户在表单组件中提交数据后,表单组件可以通过自定义事件将数据传递给父组件,以便父组件进行后续处理
通过自定义事件传递数据
- 定义自定义事件-第一种方式
<template>
<div>
<!-- 给Student这个组件实例对象Vc绑定了一个事件-->
<!-- 给谁绑定了事件,就找谁触发事件-->
<!-- v-on:自定义事件名="对应方法 "-->
<!-- 若想让自定义事件只能触发一次,可以使用once修饰符,或$once方法 -->
<!-- 可以简写为@testDemo="demo" -->
<Student v-on:testDemo="demo"></Student>
</div>
</template>
<script>
import Student from "@/components/Student.vue";
export default {
name: 'App',
components: {
Student
},
methods: {
demo(name) {
console.log("子组件data name", name)
}
}
}
</script>
- 定义自定义事件-第二种方式
<template>
<div>
<!-- 给组件设置ref属性 -->
<Student ref="student"></Student>
</div>
</template>
<script>
import Student from "@/components/Student.vue";
export default {
name: 'App',
components: {
Student
},
methods: {
demo(name) {
console.log("子组件data name", name)
}
},
// 当组件加载完毕之后
mounted() {
// student组件实例对象,绑定testDemo事件,触发Demo回调
// 更加灵活,可以做一些前后置操作再绑定事件
// 该方式回调要么配置在methods中,要么用箭头函数,写普通函数中的this是要绑定的组件实例对象
this.$refs.student.$on("testDemo",this.demo)
}
}
</script>
- 触发自定义事件
<script>
export default {
name: "Student",
data: function () {
return {name: "vue", address: "Beijing"}
},
methods: {
sendStudentName(){
// 通过$emit方法触发事件,传入自定义事件的名字
// 触发testDemo事件
this.$emit("testDemo",this.name)
}
}
}
</script>
<template>
<div class="student">
<h1>名字:{{ name }}</h1>
<h1>地址:{{ address }}</h1>
<button @click="sendStudentName">按钮</button>
</div>
</template>
解绑自定义事件
// 在要解绑的组件上调用解绑指定组件
this.$off("testDemo")
// 解绑多个指定事件
this.$off(["testDemo","xxxx"])
// 所有的自定义事件都解绑
this.$off()
native
如果在组件标签上绑定原生的事件,组件标签也会当成自定义事件去寻找自定义的方法
<!-- 使用native修饰符,告诉组件这个是原生事件 -->
<Student ref="student" @click.native="show"></Student>
全局事件总线
一种组件间通信的方式,用于任意组件间通信,在应用程序中实现事件通信的机制,它允许不同的组件之间进行解耦的通信。可以把它想象成一个消息中心,各个组件或模块可以向这个中心发布(触发)事件,也可以从这个中心订阅(监听)事件。当一个事件被发布时,所有订阅了该事件的组件或模块都会收到通知并可以执行相应的操作
创建全局事件总线
VueComponent.prototype.
__proto__
=== Vue.prototype$on、$off、$emit都是Vue原型上的方法,组件实例对象(vc)可以访问到Vue原型上的属性、方法
可以通过创建一个新的 Vue 实例来作为全局事件总线。通常在项目的入口文件中进行设置
// 入口文件
new Vue({
render: h => h(App),
// 生命周期函数:beforeCreate 组件实例刚被创建时调用
beforeCreate() {
// 在vue的原型上添加一个$bus属性,值是当前vue实例
Vue.prototype.$bus = this
}
}).$mount('#app')
使用全局事件总线
接收数据:A组件想接收数据,则在A组件中给$bus绑定自定义事件,事件的回调留在A组件自身
// 子组件A
// 组件挂载后绑定事件
mounted() {
// 在bus(vue)上绑定一个test事件
this.$bus.$on("test",(data)=>{
console.log("收到数据",data)
})
},
// 组件销毁之前解绑
beforeDestroy(){
this.$bus.$off("test")
}
触发全局事件总线
// 子组件B
sendData(){
// 触发bus(vue)的test事件
this.$bus.$emit("test","data数据")
}
消息订阅与发布
PubSub 的概念
PubSub 是 Publish - Subscribe(发布 - 订阅)的缩写,它本质上是一种消息传递模式。在这种模式下,有发布者(Publishers)和订阅者(Subscribers)两类角色。发布者负责产生消息并将其发送到一个消息中心(也称为消息代理,Message Broker),订阅者则向消息中心表达自己对某些消息类型的兴趣,当消息中心收到发布者发送的匹配订阅者兴趣的消息时,就会将消息转发给订阅者
一种组件间通信的方式,适用于任意组件间通信
有一些专门的 PubSub 库可以帮助实现消息的发布和订阅。例如pubsu-js库
使用pubsub
安装pubsu-js库
npm install -g pubsub-js引入pubsub
import pubsub from 'pubsub-js'订阅消息
A组件想接收数据,则在A组件中订阅消息,订阅的回调留在A组件自身
// 组件挂载完之后订阅消息 mounted() { // 参数:主题、回调函数(主题名、数据) // 订阅了testTopic主题的消息,如果有人给testTopic主题发消息,会接受到 // pubsub.subscribe会返回一个订阅id this.pid = pubsub.subscribe("testTopic",function (msgName,data){ // 此时this是undefined,因为使用的三方库 // 可以使用箭头函数,this是当前vc 或者配置回调函数在这里调用 console.log(data) }) }, // 组件销毁前 beforeDestroy(){ // 取消订阅(订阅id) pubsub.unsubscribe(this.pid) }发布消息
// 给订阅testTopic主题的发送消息,发送消息内容是helloworld pubsub.publish("testTopic","helloworld")
$nextTick
$nextTick
是 Vue.js 提供的一个实例方法,它的主要作用是在下次 DOM 更新循环结束之后执行延迟回调。在 Vue 中,数据的变化到 DOM 的更新是异步的,当数据发生改变时,Vue 会开启一个异步更新队列,将同一事件循环中的所有数据变化引起的 DOM 更新操作合并到一个更新任务中,等本轮事件循环结束后,再一次性执行 DOM 更新。
$nextTick
就是用于在这个 DOM 更新完成后执行一些操作
edit(todo){
if(todo.hasOwnProperty('isEdit')){
todo.isEdit = true
}else {
this.$set(todo,'isEdit',true)
}
this.$refs.inputTitle.focus()
}
// 问题示例:我们想修改一个状态,状态是true的时候输入框可以获取获取焦点
// 问题在于,todo.isEdit = true修改后,vue不是立马渲染的,而是等代码都执行完才渲染
// 相当于this.$refs.inputTitle.focus() 执行完 再去渲染,
// 执行的时候页面还没有渲染,是false,从而获取焦点失败
// 当页面渲染完后,再去获取焦点
this.$nextTick(function (){
this.$refs.inputTitle.focus()
})
作用:在下一次 DOM 更新结束后执行其指定的回调。
什么时候用:当改变数据后,要基于更新后的新DOM进行某些操作时,要在nextTick所指定的回调函数中执行
过渡与动画
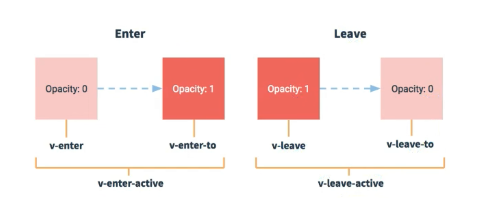
在插入、更新或移除 DOM元素时,在合适的时候给元素添加样式类名
动画默认名称效果
vue会根据规则自动实现动画效果,适用一个动画
<template>
<div>
<button @click="isShow = !isShow"> 显示/隐藏</button>
<!-- 让谁有动画效果,就用transition 把谁包起来 -->
<!-- appear属性用于控制元素在初始渲染时是否应用过渡效果 不加则初始渲染不应用-->
<!-- 只适用于包裹单个元素 -->
<transition appear>
<h1 v-show="isShow">hello world</h1>
</transition>
</div>
</template>
<style scoped>
h1 {
background-color: orange;
}
/* v-enter-active主要用于定义元素进入(插入)时过渡动画的行为 */
.v-enter-active {
animation: test 1s;
}
/* v-leave-active用于定义元素离开(移除)时过渡动画的行为 */
.v-leave-active {
animation: test 1s reverse;
}
/* 定义动画关键帧 */
@keyframes test {
from {
transform: translateX(-100%);
}
to {
transform: translateX(0px);
}
}
</style>
动画自定义名称
设置自定义名称,可以指定多个不同的效果
<!-- 指定name名称-->
<transition appear name="hello">
<h1 v-show="isShow">hello world</h1>
</transition>
/* 使用指定name */
.hello-enter-active {
animation: test 1s;
}
/* 使用指定name */
.hello-leave-active {
animation: test 1s reverse;
}
过渡效果
<template>
<div>
<button @click="isShow = !isShow"> 显示/隐藏</button>
<!-- 让谁有动画效果,就用transition 把谁包起来 -->
<!-- appear属性用于控制元素在初始渲染时是否应用过渡效果 不加则初始渲染不应用-->
<transition appear>
<h1 v-show="isShow">hello world</h1>
</transition>
</div>
</template>
<style scoped>
h1{
background-color: orange;
transition: 0.5s linear;
}
/* 进入的起点 */
.hello-enter {
transform: translateX(-100%);
}
/* 进入的终点 */
.hello-enter-to {
transform: translateX(0);
}
/* 离开的起点 */
.hello-leave{
transform: translateX(0%);
}
/* 离开的终点 */
.hello-leave-to{
transform: translateX(-100%);
}
</style>
合并写法
h1{
background-color: orange;
}
/* 进入的起点和离开的终点 */
.hello-enter,.hello-leave-to {
transform: translateX(-100%);
}
/* 不去修改h1本身的样式,使用进入和离开的时候设置效果 */
.hello-enter-active,.hello-leave-active {
transition: 0.5s linear;
}
/* 进入的终点和离开的启动 */
.hello-enter-to,.hello-leave {
transform: translateX(0);
}
多个元素过渡
<!-- transition只能包裹一个元素 -->
<!-- 包裹多个元素使用transition-group,且每个元素都有一个key值 -->
<transition-group appear name="hello">
<h1 v-show="isShow" key="1">hello world</h1>
<h1 v-show="isShow" key="2">hello vue</h1>
<h1 v-show="isShow" key="3">hello html</h1>
</transition-group>
集成第三方动画
可以使用现成的三方动画库来实现效果
安装
npm install animate.css --save引入
import "animate.css"配置
<!-- 配置name--> <!-- 配置进入的效果 在该库文档上选用对应效果的名字--> <!-- 配置离开的效果 在该库文档上选用对应效果的名字--> <transition-group appear name="animate__animated animate__bounce" enter-active-class="animate__bounceOutRight" leave-active-class="animate__fadeInDown" > <h1 v-show="isShow" key="1">hello world</h1> <h1 v-show="isShow" key="2">hello vue</h1> <h1 v-show="isShow" key="3">hello html</h1> </transition-group>