结构化异常SEH处理机制详细介绍(一)
结构化异常处理(SEH)是Windows操作系统提供的强大异常处理功能。而Visual C++中的__try{}/__finally{}和__try{}/__except{}结构本质上是对Windows提供的SEH的封装。
一、分类
- Per-Thread类型SEH(也称为线程异常处理),用来监视某线程代码是否发生异常。
- Final类型SEH(也称为进程异常处理、筛选器或顶层异常处理),用于监视整个进程中所有线程是否发生异常。在整个进程中,该类型异常处理过程只有一个,可通过SetUnhandledExceptionFilter设置。
二、SEH相关的数据结构和API
2.1、相关结构
1) 线程信息块TIB(Thread Information Block或TEB)

结构化异常SEH处理机制详细介绍(二)
本文将全面阐述__try,__except,__finally,__leave异常模型机制,它也即是Windows系列操作系统平台上提供的SEH模型。SEH实际包含两个主要功能:结束处理(termination handling)和异常处理(exception handling)。每当你建立一个try块,它必须跟随一个finally块或一个except块。一个try 块之后不能既有finally块又有except块。但可以在try - except块中嵌套try - finally块,反过来也可以。__try __finally关键字用来标出结束处理程序两段代码的轮廓。不管保护体(try块)是如何退出的。不论你在保护体中使用return,还是goto,或者是longjump,结束处理程序(finally块)都将被调用。在try使用__leave关键字会引起跳转到try块的结尾。
一、try/except框架
SEH的异常处理模型主要由try-except语句来完成,它与标准C++所定义的异常处理模型非常类似,也都是可以定义出受监控的代码模块,以及定义异常处理模块等。代码框架如下:
__try{
//被保护的代码块
……
}
__except(except fileter/*异常过滤程序*/){
//异常处理程序
}在一个函数中,可以有多个try-except语句。它们可以是一个平面的线性结构,也可以是分层的嵌套结构。为了与C++异常处理模型相区别,VC编译器对关键字做了少许变动。首先是在每个关键字加上两个下划线作为前缀,这样既保持了语义上的一致性,另外也尽最大可能来避免了关键字的有可能造成名字冲突而引起的麻烦等;其次,C++异常处理模型是使用catch关键字来定义异常处理模块,而SEH是采用__except关键字来定义。并且,catch关键字后面往往好像接受一个函数参数一样,可以是各种类型的异常数据对象;但是__except关键字则不同,它后面跟的却是一个表达式(可以是各种类型的表达式)。从这个框架我们可以看到由三块组成:__try块,__except过滤表达式和异常处理块。
①当__try块中的代码发生异常时,__except()中的过滤程序就被调用。
②过滤程序可以是一个简单的表达式或一个函数(返回值应为EXCEPTION_CONTINUE_SEARCH、EXCEPT_CONTINUE_EXECUTE或EXCEPT_EXECUTE_HANDLER之一)
当某个__try块中的代码触发了异常时(也可能是__try块中调用的函数中引发异常),操作系统会从最靠近引发异常代码的地方开始从下层往上层查找__except块(这里的层是指__try块的嵌套层),对于找到的每一个__except块,会先计算它的异常过滤器,如果过滤器返回EXCEPTION_CONTINUE_SEARCH,则说明此__except块不处理此类异常,需要继续往上层查找,如果某过滤器返回EXCEPTION_EXECUTE_HANDLER则说明此__except块可以处理此类异常,即找到了异常的处理代码,此时停止查找,但是在执行该__except块中的异常处理代码之前,要先进行全局展开。全局展开的过程与查找__except块的过程类似,只不过这次是查找从底层向上查找__finally块,查找过程中遇到的每一个__finally块中的代码都被执行,直到查找到前面说的处理异常的__except块那一层停止,这时全局展开完成,然后执行__except块中的异常处理代码。执行完异常处理代码之后,指令流从__except块后的第一条指令开始。从这里也可以看出全局展开也是为了保证__finally语义的正确性,因为指令流从引发异常代码转到到__except异常处理代码时也导致了指令流从__try块嵌套层中所有与__finally对应的__try块中流出,由前面的__finally语义说明可知,此时必须要执行全局展开过程以包成__finally语义的正确性。
③过滤表达式中可以调用GetExceptionCode和GetExceptionInformation函数取得正在处理的异常信息。但这两个函数不能在异常处理程序中使用。GetExceptionCode是个内联函数,其代码直接嵌入到被调用的地方(注意与函数调用的区别),它的返回值表明刚刚发生的异常的类型(定义在WinBase.h中,如EXCEPTION_ACCESS_VIOLATION)。GetExceptionInformation可获取异常发生时,系统向发生异常的线程栈中压入的EXCEPTION_RECORD、CONTEXT和EXCEPTION_POINTERS结构中的异常信息或CPU有关的信息
④与try/finally不同,try/except中可以使用return、goto、continue和break,它们并不会导致局部展开。
二、try/finally框架
SEH的异常结束处理模型主要由try-finally语句来完成。终止处理就是保证应用程序在一段被保护的代码发生中断后(无论是异常还是其他)还能够执行清理工作,清理工作包括关闭文件、清理内存等。代码框架如下:
__try{
//被保护的代码块
……
}
__finally{
//终止处理
}
__try/__finally的特点
①finally块总是保证,无论__try块中的代码有无异常,finally块总是被调用执行。
②try块后面只能跟一个finally块或except块,要跟多个时只能用嵌套,但__finally块不可以再嵌套SEH块,except块中可以嵌套SEH块。
③利用try/finally可以使代码的逻辑更清楚,在try块中完成正常的逻辑,finally块中完成清理工作,使代码可读性更强,更容易维护。
④当指令从__try块底部自然流出时,会执行finally块
⑤局部展开时:从try块中提前退出(由goto、longjump、continue、break、return等语句引发)将程序控制流强制转入finally块,这时就会进行局部展开(但ExitProcess、ExitThread、TerminateProcess、TerminateThread等原因导致的提前离开除外,因为这会直接终止线/进程,而不能展开)。说白了,局部展开就是将__finally块的代码提前到上述那几种语句之前执行。
⑥全局展开时也会引发finally块的执行。从Vista开始,须显示保护try/finally框架,以确保抛出异常时finally会被执行。即try/finally块外面的某层要使用try/except块保护且except中的过滤函数要返回EXCEPTION_EXECUTE_HANDLER。Vista以前的Windows,会在线程的入口点处用try/except加以保护,但Vista为了提高Windows错误报告(WER)记录的可靠性,将这个入口点的异常过滤程序返回为EXCEPTION_CONTINUE_SEARCH,最后进程会被终止,从而导致finally块没有机会被执行。(关于全局展开见第24章的相关的部分)。
⑦如果异常发生在异常过滤程序里,终止处理程序也不会被执行。
⑧finally块被执行的原因总是由以上三种情况之一引起。可以调用AbnormalTermination函数来查看原因。该函数是个内联函数,当正常流出时会返回FALSE,局部或全局展开时返回TRUE。
三、__leave关键字
①该关键字只能用在try/finally框架中,它会导致代码执行控制流跳转到到try块的结尾,也可以认为是try后的闭花括号处。
②这种情况下,代码执行是正常从try块进入finally,所以不会进行局部展开。
③但一般需定义一个布尔变量,指令离开try块时,函数执行的结果是成功还是失败,然后在finally块中可根据这个(或这些)变量以决定资源是否需要释放。
参考:
https://www.cnblogs.com/5iedu/p/5228946.html
C++异常处理机制
异常处理是C++的一项语言机制,用于在程序中处理异常事件。异常事件在C++中表示为异常对象。异常事件发生时,程序使用throw关键字抛出异常表达式,抛出点称为异常出现点,由操作系统为程序设置当前异常对象,然后执行程序的当前异常处理代码块,在包含了异常出现点的最内层的try块,依次匹配catch语句中的异常对象(只进行类型匹配,catch参数有时在catch语句中并不会使用到)。若匹配成功,则执行catch块内的异常处理语句,然后接着执行try…catch…块之后的代码。如果在当前的try…catch…块内找不到匹配该异常对象的catch语句,则由更外层的try…catch…块来处理该异常;如果当前函数内所有的try…catch…块都不能匹配该异常,则递归回退到调用栈的上一层去处理该异常。如果一直退到主函数main()都不能处理该异常,则调用系统函数terminate()终止程序。
一、抛异常---throw
throw是个关键字,与抛出表达式构成了throw语句。其语法为:throw 表达式;throw语句必须包含在try块中,也可以是被包含在调用栈的外层函数的try块中。执行throw语句时,throw表达式将作为对象被复制构造为一个新的对象,称为异常对象。异常对象放在内存的特殊位置,该位置既不是栈也不是堆,在window上是放在线程信息块TIB中。这个构造出来的新对象与本级的try所对应的catch语句进行类型匹配。如下:
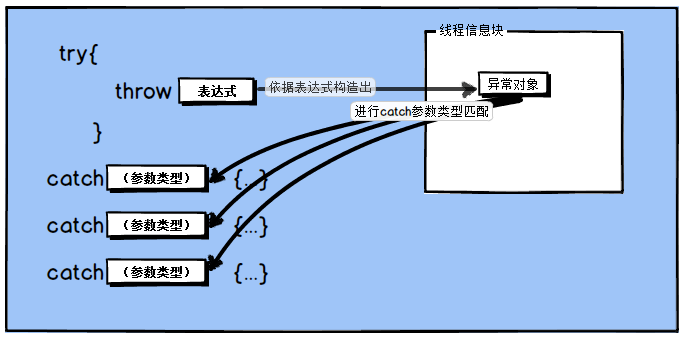
在vc++里,throw关键字其实是对RaiseException函数的封装,代码如下:
__declspec(noreturn) extern "C" void __stdcall
#if !defined(_M_ARM) || defined(_M_ARM_NT)
_CxxThrowException(
#else
__CxxThrowException(
#endif
void* pExceptionObject, // The object thrown
_ThrowInfo* pThrowInfo // Everything we need to know about it
) {
EHTRACE_ENTER_FMT1("Throwing object @ 0x%p", pExceptionObject);
static const EHExceptionRecord ExceptionTemplate = { // A generic exception record
EH_EXCEPTION_NUMBER, // Exception number
EXCEPTION_NONCONTINUABLE, // Exception flags (we don't do resume)
NULL, // Additional record (none)
NULL, // Address of exception (OS fills in)
EH_EXCEPTION_PARAMETERS, // Number of parameters
{ EH_MAGIC_NUMBER1, // Our version control magic number
NULL, // pExceptionObject
NULL,
#if _EH_RELATIVE_OFFSETS
NULL // Image base of thrown object
#endif
} // pThrowInfo
};
EHExceptionRecord ThisException = ExceptionTemplate; // This exception
ThrowInfo* pTI = (ThrowInfo*)pThrowInfo;
if (pTI && (THROW_ISWINRT( (*pTI) ) ) )
{
ULONG_PTR *exceptionInfoPointer = *reinterpret_cast<ULONG_PTR**>(pExceptionObject);
exceptionInfoPointer--; // The pointer to the ExceptionInfo structure is stored sizeof(void*) infront of each WinRT Exception Info.
WINRTEXCEPTIONINFO** ppWei = reinterpret_cast<WINRTEXCEPTIONINFO**>(exceptionInfoPointer);
pTI = (*ppWei)->throwInfo;
(*ppWei)->PrepareThrow( ppWei );
}
//
// Fill in the blanks:
//
ThisException.params.pExceptionObject = pExceptionObject;
ThisException.params.pThrowInfo = pTI;
#if _EH_RELATIVE_OFFSETS
PVOID ThrowImageBase = RtlPcToFileHeader((PVOID)pTI, &ThrowImageBase);
ThisException.params.pThrowImageBase = ThrowImageBase;
#endif
//
// If the throw info indicates this throw is from a pure region,
// set the magic number to the Pure one, so only a pure-region
// catch will see it.
//
// Also use the Pure magic number on Win64 if we were unable to
// determine an image base, since that was the old way to determine
// a pure throw, before the TI_IsPure bit was added to the FuncInfo
// attributes field.
//
if (pTI != NULL)
{
if (THROW_ISPURE(*pTI))
{
ThisException.params.magicNumber = EH_PURE_MAGIC_NUMBER1;
}
#if _EH_RELATIVE_OFFSETS
else if (ThrowImageBase == NULL)
{
ThisException.params.magicNumber = EH_PURE_MAGIC_NUMBER1;
}
#endif
}
//
// Hand it off to the OS:
//
EHTRACE_EXIT;
#if defined(_M_X64) && defined(_NTSUBSET_)
RtlRaiseException( (PEXCEPTION_RECORD) &ThisException );
#else
RaiseException( ThisException.ExceptionCode,
ThisException.ExceptionFlags,
ThisException.NumberParameters,
(PULONG_PTR)&ThisException.params );
#endif
}
WinDbg常用命令系列---查看线程调用栈命令K*简介
Windbg里的K*命令显示给定线程的堆栈帧以及相关信息,对于我们调试时,进行调用栈回溯有很大的帮助。
一、K*命令使用方式
在不同平台上,K*命令的使用组合如下
User-Mode, x86 Processor
[~Thread] k[b|p|P|v] [c] [n] [f] [L] [M] [FrameCount] [~Thread] k[b|p|P|v] [c] [n] [f] [L] [M] =BasePtr[FrameCount] [~Thread] k[b|p|P|v] [c] [n] [f] [L] [M] =BasePtrStackPtrInstructionPtr [~Thread] kd [WordCount]
Kernel-Mode, x86 Processor
[Processor] k[b|p|P|v] [c] [n] [f] [L] [M] [FrameCount] [Processor] k[b|p|P|v] [c] [n] [f] [L] [M] =StackPtrFrameCount [Processor] k[b|p|P|v] [c] [n] [f] [L] [M] =BasePtrStackPtrInstructionPtr [Processor] kd [WordCount]
User-Mode, x64 Processor
[~Thread] k[b|p|P|v] [c] [n] [f] [L] [M] [FrameCount] [~Thread] k[b|p|P|v] [c] [n] [f] [L] [M] =StackPtrFrameCount [~Thread] k[b|p|P|v] [c] [n] [f] [L] [M] =StackPtrInstructionPtrFrameCount [~Thread] kd [WordCount]
Kernel-Mode, x64 Processor
[Processor] k[b|p|P|v] [c] [n] [f] [L] [M] [FrameCount] [Processor] k[b|p|P|v] [c] [n] [f] [L] [M] =StackPtrFrameCount [Processor] k[b|p|P|v] [c] [n] [f] [L] [M] =StackPtrInstructionPtrFrameCount [Processor] kd [WordCount]
User-Mode, ARM Processor
[~Thread] k[b|p|P|v] [c] [n] [f] [L] [M] [FrameCount] [~Thread] k[b|p|P|v] [c] [n] [f] [L] [M] =StackPtrFrameCount [~Thread] k[b|p|P|v] [c] [n] [f] [L] [M] =StackPtrInstructionPtrFrameCount [~Thread] kd [WordCount]
Kernel-Mode, ARM Processor
[Processor] k[b|p|P|v] [c] [n] [f] [L] [M] [FrameCount] [Processor] k[b|p|P|v] [c] [n] [f] [L] [M] =StackPtrFrameCount [Processor] k[b|p|P|v] [c] [n] [f] [L] [M] =StackPtrInstructionPtrFrameCount [Processor] kd [WordCount]
二、参数说明
- Thread
指定要显示其堆栈的线程。如果省略此参数,将显示当前线程的堆栈。只能在用户模式下指定线程。
- Processor
指定要显示其堆栈的处理器。
- b显示传递给堆栈跟踪中每个函数的前三个参数。
win32线程栈溢出问题 (一)
一、什么是线程栈溢出
我们都知道,每一个win32线程都会开辟一个空间,用来临时存储线程执行时所调用的一系列函数的参数、返回地址和局部变量及其他上下文信息。这个空间就是线程的栈区。栈区的容量是有限的,在程序编译链接时,就固定下来了。通过VC++编译的程序,默认的栈区大小是1MB。当我们程序执行时,访问超过了这个空间的边界,就叫栈溢出,又叫Stack overflow。这时会产生代码为STATUS_STACK_OVERFLOW(0xC00000FD)的异常,从而导致程序崩溃。注意一定要与栈缓冲区溢出---STATUS_STACK_BUFFER_OVERRUN(0xC0000409)区别开来。
二、栈溢出的原因
栈溢出是用户模式线程可能会遇到的错误。 有三个可能的原因产生此错误:
线程使用为其保留的整个堆栈。这通常是由无限递归引起的。
线程无法扩展堆栈,因为页文件已最大化,因此无法提交其他页来扩展堆栈。
由于系统内使用以扩展页面文件的短时间内,线程不能扩展堆栈。
当一个线程上运行的函数分配的本地变量时,变量放线程的调用堆栈上。 函数所需的堆栈空间量可能大至所有本地变量的大小的总和。 但是,编译器通常会执行优化,降低函数所需的堆栈空间。 例如,如果两个变量,则在不同的作用域中,编译器可以为这两个这些变量使用相同的堆栈内存。 编译器还可能无法完全消除某些本地变量对计算进行优化。优化的量会影响应用在生成时的编译器设置。 例如,调试版本和发布版本具有不同的优化级别。 所需的调试版本中的函数的堆栈空间量可能会大于该发行版中的相同函数所需的堆栈空间量。
在我们编写代码时,如下情况通常引发栈溢出:
- 由于某些原因,导致函数递归深度很深或无穷递归
- 在栈里分配了很大的缓冲区
- 栈里的某缓冲区溢出
三、溢出代码举例
3.1、在栈里分配了很大的缓冲区导致溢出
代码如下:
#include "stdafx.h" int LargeBuffer(void)
{
char buf[1024 * 1024];
int a = 0;
int b = buf[2];
return a+b;
}
int _tmain(int argc, _TCHAR* argv[])
{
int n=LargeBuffer();
printf("n=%d\n", n);
return 0;
}