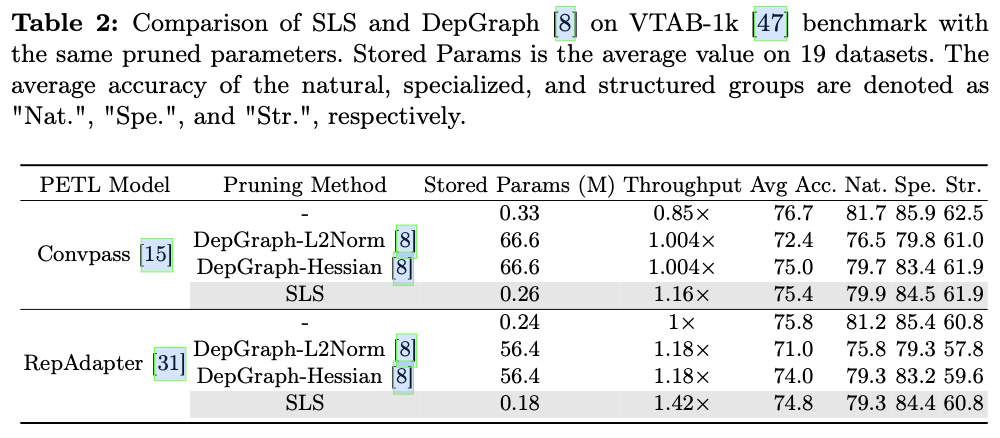
『玩转Streamlit』--页面布局
一个优秀的数据应用不仅仅是功能的强大,更在于其用户体验的打造。
而良好的
页面布局
,作为用户体验的重要组成部分,不仅能够提升信息的可读性,还能引导用户高效地完成操作。
反之,混乱的布局会让人感到困惑和挫败,甚至导致用户放弃使用应用。
在
Streamlit
中,
Sidebar
(侧边栏)、
Columns
(列布局)和
Tabs
(标签页)是三个至关重要的布局组件,它们各自有不同的使用场景,共同构成了应用界面的骨架。
1. 侧边栏 st.sidebar
Sidebar
(侧边栏)在
Streamlit
应用中主要是导航作用。
Sidebar
通常位于应用界面的左侧或右侧,它的优势在于,既不会占用主内容区域的空间,又同时保持了对关键功能的即时访问,特别适用于那些需要频繁切换功能或具有多层导航结构的应用。
Sidebar
不是菜单,一般不用于页面的切换,它的里面可以包含其他的组件。
下面构建一个简化的数据分析场景,演示
Sidebar
的使用方法。
我们在
Sidebar
中设置需要选择的数据集和数据分类(分为
测试集
和
验证集
),
然后在主页面中获取选择的数据集和数据分类,只实现操作数据的功能。
# 侧边栏中选择数据集
dataset = st.sidebar.selectbox(
"选择数据集?",
(
"手写数字数据",
"房屋成交数据",
"股市交易数据",
),
)
# 侧边栏中选择数据分类
data_type = st.sidebar.radio(
"数据分类: ",
("测试集", "验证集", "所有数据"),
)
# 右侧页面中的模拟操作
st.title(f"数据集: {dataset}")
st.divider()
st.write(f"数据分类: 【{data_type}】")
st.write(f"TODO!!!: 操作数据的功能")

2. 列布局 st.columns
Columns
布局,即列布局,是一种将页面内容分割成多个垂直排列的列,以便更有效地展示信息的布局方式。
这种布局方式不仅提升了页面的视觉吸引力,还显著增强了用户体验,使得信息获取更加直观和便捷。
在
Streamlit
中,可以使用
st.columns
函数来创建列布局。
这个函数接受一个列表作为参数,列表中的每个元素都是一个函数,代表一列的内容。
Streamlit
会按照列表的顺序和长度来渲染列。
比如,我们构造一个数据分析的示例,分3列展示内容,
- 第一列模拟选择数据
- 第二列模拟一些配置信息
- 第三列根据配置模拟绘制图形
# 绘图的类型放在session中
if "graph" not in st.session_state:
st.session_state.graph = ""
# 第一列
def column_1():
st.header("1. 选择数据")
st.selectbox(
"选择数据集?",
(
"手写数字数据",
"房屋成交数据",
"股市交易数据",
),
)
# 随机模拟的数据
data = pd.DataFrame(np.random.randn(5, 3), columns=["A", "B", "C"])
st.table(data)
def column_2():
st.header("2. 配置数据")
graph = st.radio(
"图形类型: ",
("折线图", "柱状图", "散点图"),
)
st.session_state.graph = graph
def column_3():
st.header("3. 绘制图形")
chart_data = pd.DataFrame(np.random.randn(20, 3), columns=["A", "B", "C"])
if st.session_state.graph == "散点图":
st.scatter_chart(chart_data)
if st.session_state.graph == "折线图":
st.line_chart(chart_data)
if st.session_state.graph == "柱状图":
st.bar_chart(chart_data)
col1, col2, col3 = st.columns(3)
with col1:
column_1()
with col2:
column_2()
with col3:
column_3()

3. 标签页 st.tabs
Tabs
组件的主要用途在于将复杂的信息结构分解为多个独立的、可切换的部分,每个部分(或称为“标签页”)都包含相关的内容或功能。
这种设计方式有助于减少用户在同一时间内需要处理的信息量,避免界面过载,同时也便于用户快速找到所需内容。
同样是上面的例子,如果数据的字段很多,配置数据的项目也很多,那么上面的
Columns
布局就显得很拥挤,
这时,用
Tabs
布局更好,代码调整很简单。
tab1, tab2, tab3 = st.tabs(["1. 选择数据", "2. 配置数据", "3. 绘制图形"])
with tab1:
tab_1()
with tab2:
tab_2()
with tab3:
tab_3()
上面函数
tab_1()
,
tab_2()
,
tab_3()
中的代码和
Columns
布局示例中的
column_1()
,
column_2()
,
column_3()
代码基本一样。

随着
Columns
布局的每个
Columns
内容逐渐增多时,可以考虑改用
Tabs
布局。
4. 总结
总之,这三种布局方式各有千秋,选择哪种布局取决于应用的具体需求、用户习惯以及设计目标。
Sidebar
(侧边栏)提供持续可见的导航菜单,适合功能繁多或需频繁切换的应用,帮助用户快速定位所需功能,同时保持主内容区域的清晰。
Columns
(列布局)则通过分割界面为多个并列区域,实现图文混排或数据报表的灵活展示。
它提高了信息密度,使得用户能够在同一视图中获取更多信息,适用于需要同时展示多种数据类型或视图的场景。
Tabs
(标签页)将内容划分为多个独立的、可切换的部分,每个部分包含相关功能或信息。
它有助于节省屏幕空间,同时帮助用户对信息进行逻辑分组,提高信息检索效率。
Tabs
适用于功能或信息分类明确,且用户可能需要根据不同需求切换查看的应用。