记一次go应用在k8s pod已用内存告警不准确分析
版权说明: 本文章版权归本人及博客园共同所有,转载请在文章前标明原文出处( https://www.cnblogs.com/mikevictor07/p/17968696.html ),以下内容为个人理解,仅供参考。
一、背景
起因:
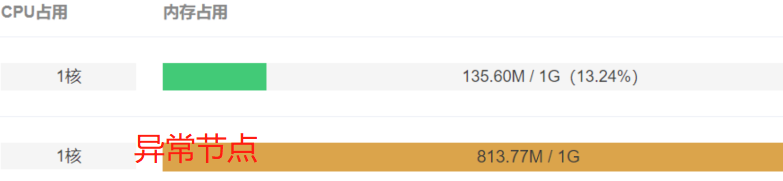
自监控应用凌晨告警:
Pod 内存使用率大于80%(规格为1c1G)
。内存缓慢增长,持续到早上内存使用率停止在81%左右。
疑点:
此模块是一个轻任务模块(基于go开发),请求量很低并且数据量非常少,平常内存占用一直以来都在100MB左右,出现内存不足的概率极小,而且运行了几个月无故障。
初步定位:
登录平常查看指标,确实有一个节点内存异常,但另一个节点正常(这模块有个特性是主备模式,
同一时间只有一个节点工作
,通过日志确定异常的节点正是工作节点)。
二、初步分析过程
登录k8s查看内存情况,通过 kubectl top pod 查看内存占用果然已经有800MB+,但理论上这模块不应该占用这么多内存(截图时间点不一样,有部分回收)。

继续登录pod内,通过 cat /sys/fs/cgroup/memory/ 查看内存统计 (注意,在pod中使用 free -m 等类似的命令只能统计到宿主机的内存信息,固无用)
# cd /sys/fs/cgroup/memory/
# cat memory.usage_in_bytes
显示输出 962097152(即约917MB,即将超过1GB限额,超过则会激活OOM Kill)
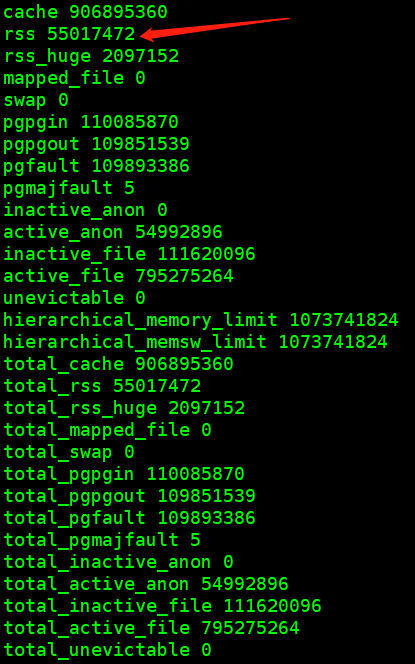
# cat memory.stat 后输出如下图
其中的
rss
标识当前应用进程实际使用内存量,
55017472 = 约52MB
,此数据证实了一般的设定:这个应用一般占用都在100MB以内。
三、怀疑监控指标不准确?
通过了解到,激活自监控告警的指标是通过k8s的
container_memory_working_set_bytes
指标超过80%告警。
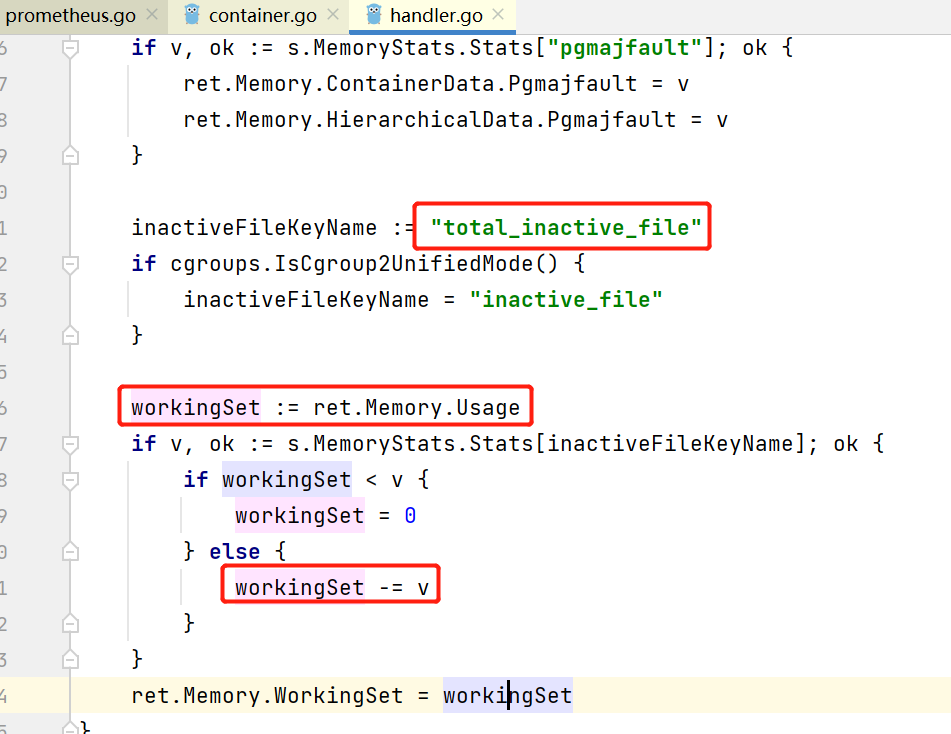
通过查阅k8s源码 promethus.go 的 Memory.WorkingSet 相关引用发现,此参数是通过计算
Memory.Usage - total_inactive_file
得出(即本案例是
962097152 - 666666620096 = 811MB
)
(其中的
Memory.Usage 即为memory.usage_in_bytes文件中的值:962097152
)
按照此情况看,数据取值确实没问题,同时,关注到一个指标
total_active_file
(795275264 = 758MB),此参数加上rss刚好与已用内存接近
,源码中未找到此指标的相关信息,通过查阅官方资料发现,此参数认为是一个不能被计算为可用内存的值。
也就是说 k8s 作者们认为
此active_file内存不认定为可用内存
(官方地址为:https://kubernetes.io/docs/concepts/scheduling-eviction/node-pressure-eviction/#active-file-memory-is-not-considered-as-available-memory )


此参数作为文件缓存是否要被计算进已用内存中,github上的讨论已经有了6年之久仍然是Open状态 (地址为: https://github.com/kubernetes/kubernetes/issues/43916)。
四、应用分析
此应用只有日志才用到写文件的操作,是否是日志文件导致的file cache呢? 进入到日志文件目录 ,通过 > xxx.log 清理文件后,再次 cat memory.stat

其中的 total_active_file 立即缩小,在通过之前的命令查看内存占用,立即恢复正常,也就是
日志文件导致的 total_active_file 增长从而导致Pod内存使用量增大
。
五、回溯代码 & 修复措施
此应用使用了 zap日志框架,通过配置 MaxSize 设定日志轮转文件大小为1G,在故障时日志文件大小已经达到了 889M。

日志一直要达到1G才会激活轮转,此前系统将此cache住,但是k8s认为此内存无法被利用,就导致了内存一直在增长,直到产生告警。
解决方案:
为保证Pod 不被 OOM Kill,通过修改MaxSize 修改文件大小进行轮转(比如改为200-300M),file cache即可在日志轮转后释放。