TimeWheel算法介绍及在应用上的探索
作者:来自 vivo 互联网服务器团队- Li Fan
本文从追溯时间轮算法的出现,介绍了时间轮算法未出现前,基于队列的定时任务实现,以及基于队列的定时任务实现所存在的缺陷。接着我们介绍了时间轮算法的算法思想及其数据结构,详细阐述了三种时间轮模型的数据结构和优劣性。
再次,我们介绍时间轮算法在 Dubbo 框架中的应用,并给出了它在 Dubbo 中的主要实现方式。
最后,我们以项目中的某个服务架构优化出发,介绍了目前设计中存在的缺陷,并借助来自中间件团队的,包含时间轮算法实现的延迟 MQ,给出了优化设计的方法。
第一章 定时任务及时间轮算法发展
1.1 时间轮算法的出现
在计算程序中,定时器用于指定一个具体的时间点去执行某一个既定的任务。而时间轮算法就是这样一种能够实现延迟功能(定时器)的巧妙算法。时间轮算法首次出现在 1997 年 George Varghese 和 Anthony Lauck 发表于 IEEE 期刊,名为“Hashed and Hierarchical Timing Wheels: Efficient Data Structures for Implementing a Timer Facility”的论文上。此文章指出,实现操作系统定时器模块的常规算法需要 O(n)的时间复杂度启动和维护计时器,对于更大问题规模 (n),这样的时间开销是巨大的,文中提出并证明了,通过一种环状桶的数据结构,可以做到使用 O(1)的时间复杂度,就可以启动,停止和维护计时器,并介绍了对时间间隔划分的处理,第一种方式是将所有的计时器时间间隔进行散列(Hash),这些时间间隔被散列到时间轮上特定的槽位中(Slot),第二种方式是利用多粒度定时轮组成具有层级结构的组合,以扩展更大的时间范围。这两种结构将在第二章中详细介绍。
1.2 基于队列的定时任务执行模型
在计算机的世界中,只有待解决的问题大规模化以后,算法的价值才能够得到最大化的体现。在介绍时间轮算法之前,我们有必要介绍另一种定时任务的实现,即基于队列的定时任务。队列这种数据结构无论是在操作系统中还是各编程语言如 Java 中都被大量使用,本文不再展开赘述。
下面从线程模型、定时任务种类和任务队列的数据结构三个方面展开详细介绍:
(1)线程模型
用户线程:负责定时任务的注册;轮询线程:负责从任务队列中扫描出符合执行条件的任务,例如任务的待执行时间已经到达,轮询线程将从队列中取出该任务,并交由异步线程池处理该任务。异步线程池:专门负责任务的执行。
(2)定时任务
定时任务主要分为一次性执行的定时任务(Dubbo 中超时判断)以及重复执行的定时任务,这两种定时任务都很好理解,一次性执行的定时任务在规定的未来某一时刻或距离现在的一段固定时长后执行,分别对应绝对值和相对值的概念。
而重复执行的定时任务是在一次性执行任务的基础上多次重复执行,这意味着,在上述线程协调工作中,当重复执行任务执行完成一次后,将被重新放回任务队列中。
(3)任务队列数据结构
从最简单的数据结构出发,假设我们选用最基本的队列,或者考虑到增减任务的方便,选择双向链表做为任务队列,为任务队列中的每个任务提供一个时间戳字段,这种实现的策略会产生哪些问题?
最大的问题是在查询上,假设任务队列中存在一些任务,那么为了找出达到规定时刻的待执行任务,轮询线程需要扫描全部任务,此种数据结构的时间复杂度为 O(n),而且存在大量的空轮询,即大部分的任务都没有达到执行时间,这种效率几乎是不可接受的。
为了提升查询效率,可以尝试从数据结构出发,利用有序队列,在计算机的算法中,有序性可以显著提高遍历的效率,这样一来,定时任务队列轮询线程从头向尾遍历时,在发现任意任务未达到规定执行时间戳后,就可以停止遍历。
但是维护有序性也需要付出代价,普通任务队列入队一个任务的时间复杂度仅仅是 O(1),而有序任务队列入队一个任务的时间复杂度为 O(nlogn)。其次,我们可以借鉴分治的思想,将任务队列分成 n 份,利用多线程遍历,在线程完全并发执行的情况下,问题规模简化到原来的 1/n。但是多线程也会 CPU 执行效率降低。
综上分析,定时任务框架需要具有如下要素:
- 严格高效的数据结构,并不能基于简单的队列结构来存储任务,否则轮询的执行效率永远无法提高。
- 简单的并发模型:CPU 的线程非常宝贵,不应占用过多线程资源。
时间轮算法解决了上述基于队列的定时任务执行模型的缺陷,因此时间轮算法思想在后面互联网技术发展中得到了大量应用,我们熟悉的 Linux Crontab,以及 Java 开发中常用的 Dubbo、Netty、Quartz、Akka、ZooKeeper、Kafka 等,几乎所有的时间任务调度都采用了时间轮算法的思想。
值得一提的是,在 Dubbo 中,为了增强系统容错,很多地方需要用到只需一次执行的任务调度,比如消费者需要知道各个 RPC 调用是否超时,而在 Dubbo 最开始的实现中,是采用将所有的返回结果(defaultFuture),都放入一个集合中,并通过一个定时任务,间隔扫描所有的 future,逐个判断是否超时。这样逻辑简单,但是浪费性能,后面 Dubbo 借鉴了 Netty,引入了时间轮。
第二章 时间轮算法思想介绍及应用场景介绍
2.1 时间轮简介
时间轮实质上是一种高效利用线程资源的任务调度模型,将大批量的任务全部整合进一个调度器中,从而对任务进行统一的调度管理,针对定时任务,延时任务等事件的调度效率非常高。
时间轮算法的核心是:第一章中描述的对任务队列进行轮询的线程不再负责遍历所有的任务,而是仅仅遍历时间刻度。时间轮算法好比指针不断在时钟上旋转、遍历,如果发现某一时刻上有任务(任务队列),那么就会将任务队列上的所有任务都执行一遍,这样便大幅度的减少了额外的扫描操作。
第一章中,我们提出了一个高效的定时任务框架需要具备严格高效的数据结构和简单的并发模型两个特点,而时间轮模型正是具备了这样的特点。
基于时间轮算法思想,后续也出现了很多种时间轮模型,目前流行的大致有三种,分别为简单时间轮模型、带有 round 的时间轮模型以及分层时间轮模型,下面将依次介绍这三种时间轮模型。
2.2 时间轮模型
2.2.1 简单时间轮模型
简单时间轮模型不再使用队列作为数据结构,而是使用数组加链表的形式(很经典的组合), 如下图所示,该时间轮通过数组实现,可以很方便地通过下标定位到定时任务链路,因此,添加、删除、执行定时任务的时间复杂度为 O(1)。

显然,这种简单时间轮就解决了任务队列中遍历效率低下的问题,轮询线程遍历到某一个时间刻度后,总是执行对应刻度上任务队列中的所有任务(通常是将任务扔给异步线程池来处理),而不再需要遍历检查所有任务的时间戳是否达到要求。
通过增加槽(slot)的数量,可以细化的时间粒度以及得到更大的时间跨度,但是这样的实现方式有巨大的缺陷:
- 当时间粒度小,时间跨度大,而任务又很少的时候,时间槽的轮询效率变低。
- 当时间粒度小,时间槽数量多,而任务又很少时,很多槽位占用的内存空间是没有意义的。
2.2.2 带有 round 的时间轮模型
类比循环数组的思想,后人设计了带 round 的时间轮,这种时间轮的结构如下图所示:
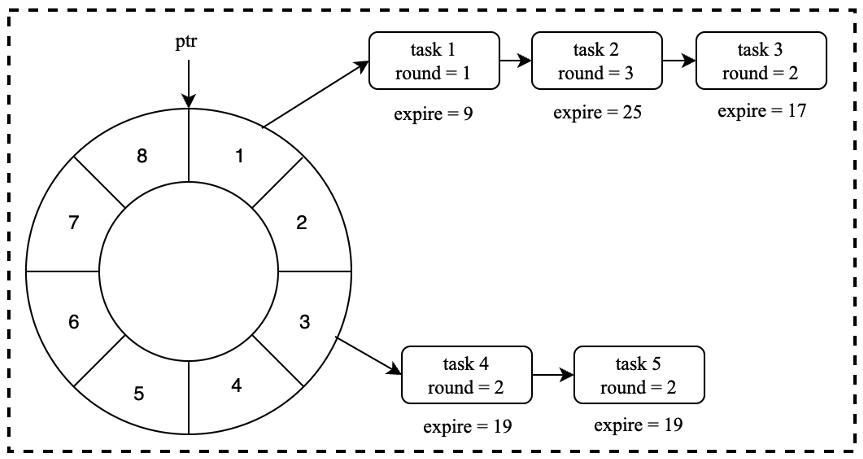
如图 2.2.2 所示,expire 代表到期时间,round 表示时间轮要在转动几圈之后才执行任务,也就是说当指针转到某个 bucket 时,不能像简单的单时间轮那样直接执行 bucket 下所有的任务。而且要去遍历该 bucket 下的链表,判断时间轮转动的次数是否等于节点中的 round 值,只有当 expire 和 round 都相同的情况下,才能执行任务。
这种结构的时间轮明显减少了所需刻度的个数,即弥补了简单时间轮在时间槽位较多,而任务较少情况下内存空间浪费的问题。
但是这种结构的时间轮并不能减少轮询线程的轮询次数,效率相对较低。
2.2.3 分层时间轮模型
分层时间轮也是一种对简单时间轮的改良方案,它的设计理念可以类比于日常生活中的时钟,分别有时、分、秒三个层级,并且每个轮盘分别具有 24、60、60 个刻度,因此,只需要 144 个刻度,即可表示一天的时间,而这种表示方式的优势在于,倍数级别时间表示的新增,只需要常数级别的刻度增加。例如,在 144 个刻度可表示的一天时间的基础上,新增 30 个刻度,即可精细表示一个月的时间。
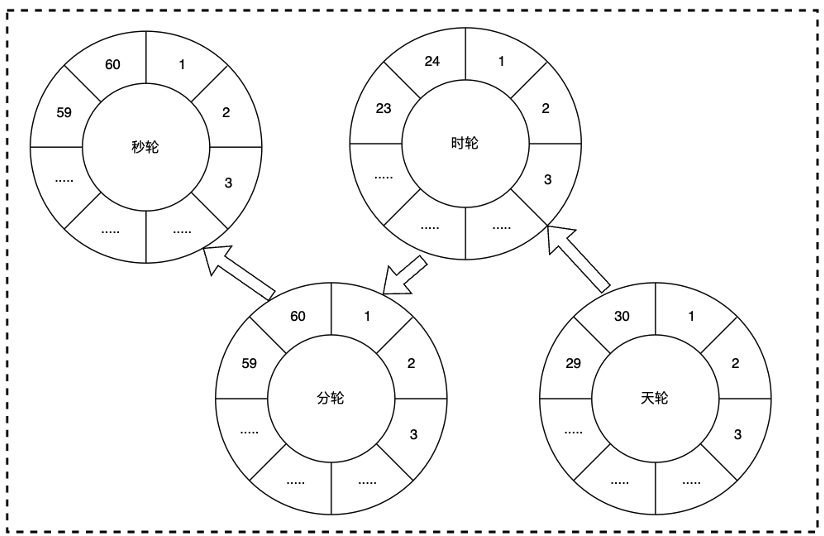
分层时间轮的工作方式为低层级的时间轮带动高层级的时间轮转动,图中箭头为任务的“下放”,例如,2 号 8 点 40 分 0 秒执行的任务,当天轮转动到刻度 2 时,会将第 2 天的任务,下放到对应时轮刻度为 8 的槽位中,当时轮转动到 8 时,会将任务继续下放到分轮刻度为 40 的槽位中,直至到最低层次的时间轮,转动到该槽位时,将该槽位中的任务,全部执行。
针对时间复杂度,这种时间轮对比带有 round 的时间轮不再遍历计算对比任务的 round,而是直接全部取出执行。
针对空间复杂度,分层时间轮利用维度上升的思路对时间轮进行分层,每个层级的时间粒度对应一个时间轮,多个时间轮之间进行级联协作。
2.3 时间轮应用场景介绍
时间轮作为高效的调度模型,在各种场景均有广泛的应用,常见的场景主要有如下几个:
(1)定时器
时间轮常用于实现定时器,可以在指定时间执行特定任务。定时器可以用于周期性任务、超时任务等,如轮询 I/O 事件、定期刷新缓存、定时清理垃圾数据等。
(2)负载均衡
时间轮可以用于实现负载均衡算法,将请求分配到不同的服务器上,避免单个服务器负载过重。时间轮可以根据服务器的负载情况来动态调整分配策略,实现动态负载均衡。
(3)事件驱动
时间轮可以用于实现事件驱动模型,将事件分配到不同的处理器上,提高并发处理能力。事件可以是 I/O 事件、定时事件、用户事件等,时间轮可以根据事件的类型和优先级来动态调整分配策略,实现高效的事件驱动模型。
(4)数据库管理
时间轮可以用于实现数据库管理,将数据分配到不同的存储设备上,提高数据读写效率。时间轮可以根据数据的类型、大小和访问频率等来动态调整数据分配策略,实现高效的数据库管理。
(5)其他应用
时间轮还可以用于其他一些应用,如消息队列、任务调度、网络流量控制等,具体应用取决于具体的需求和场景。
第三章 时间轮在 Dubbo 的应用与实现
3.1 Dubbo 中时间轮的应用
Dubbo 的设计中,客户端在调用服务端的时候,会对任务进行计时,如果任务超时,那么会被检测到,并重试请求。在 Dubbo 最开始的实现中,是采用将所有的返回结果(defaultFuture),都放入一个集合中,并通过一个定时任务,间隔扫描所有的 future,逐个判断是否超时。
这样逻辑简单,但是浪费性能,后面 Dubbo 借鉴了 Netty,引入了时间轮。任务交由时间轮管理,由专门的线程进行调度。
3.2 Dubbo 中时间轮的实现
Dubbo 中时间轮算法的实现,主要有一个类和三个接口:
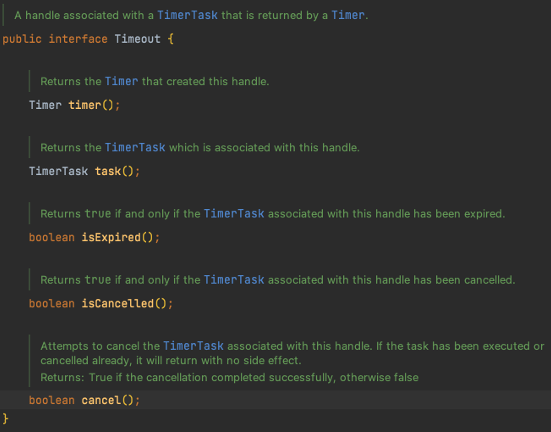
首先是 Timer 接口,这个一个调度的核心接口,主要用于后台的一次性调度,我们仅介绍 newTimeOut 方法,这个方法就是把一个任务扔给调度器执行,第一个参数类型 TimerTask,即需要执行的任务。

接下来是 TimeTask 接口,它只有一个方法 run,参数类型是 Timeout,我们注意到上面 Timer 接口的 newTimeout 这个方法返回的参数就是 Timeout,和此处的入参相同,实际这里传入的 Timeout 参数就是 newTimeout 的返回值。
Timeout 对象与 TimerTask 对象一一对应,两者的关系类似于线程池返的 Future 对象与提交到线程池中的任务对象之间的关系。
最后是 TimeOut 接口,它代表的是对一次任务的处理,其中有几个方法,从介绍上即可看出各方法用途,这里不再赘述。
上述几个接口从逻辑上构成了一个任务调度系统。下面是任务调度系统的核心,即时间轮调度器的实现-- HashedWheelTimer。
仔细看它的类上注释可以发现,该方法并不能提供精确的计时,而是检测每个 tick 中(也就是时间轮中的一个时间槽),是否有 TimerTask,其期望执行时间已经落后于当前时间,如果是则执行该任务。任务执行时间的精确度可以通过细化时间槽来提升。
默认的 tick duration 是 100 毫秒,大部分网络应用中,I/O 超时并非必须是精准的,例如 5 秒超时,实际上稍晚一会也是可以的,因此这个默认值无需修改。

这个类维护了一种称为“wheel”的数据结构,也就是我们说的时间轮。简单地说,一个 wheel 就是一个 hash table,它的 hash 函数是任务的截止时间,也就是我们要通过 hash 函数把这个任务放到它应该在的时间槽中,这样随着时间的推移,当我们进入某个时间槽中时,这个槽中的任务也刚好到了它该执行的时间。
这样就避免了在每一个槽中都需要检测所有任务是否需要执行。在 HashedWheelTimer 的构造函数中,最重要的是 createWheel 方法,忽略基本的参数校验,只看方法主流程,首先是对时间槽数量的规范化处理,处理方式为将构造时传入的数量,修改为大于等于它的最小的 2 的次幂。为什么这样处理以及处理的具体方式,有兴趣可以研究下源代码。
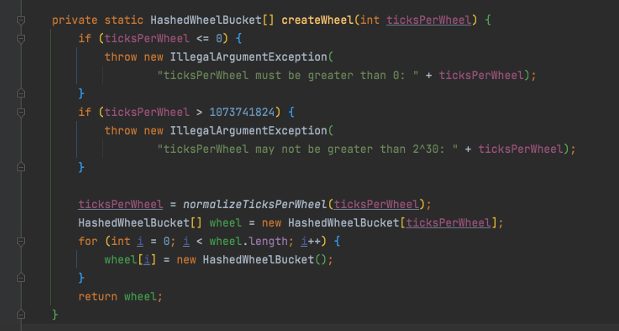
接着则是创建时间槽数组,最后是初始化时间槽数组的每个参数。
下面介绍下 newTimeout 方法,这个方法的主要作用是向调度器中添加一个待执行的任务,同样忽略基本的参数校验,主体流程为:
- 第一步将等待调度的任务数+1,如果超过了最大限制,则-1 并抛出异常。
- 第二步则调用 start 方法,启动时间轮。
- 第三步计算当前任务的截止时间,并做防溢出处理。
- 构造一个 TimeOut ,并放入等待队列。
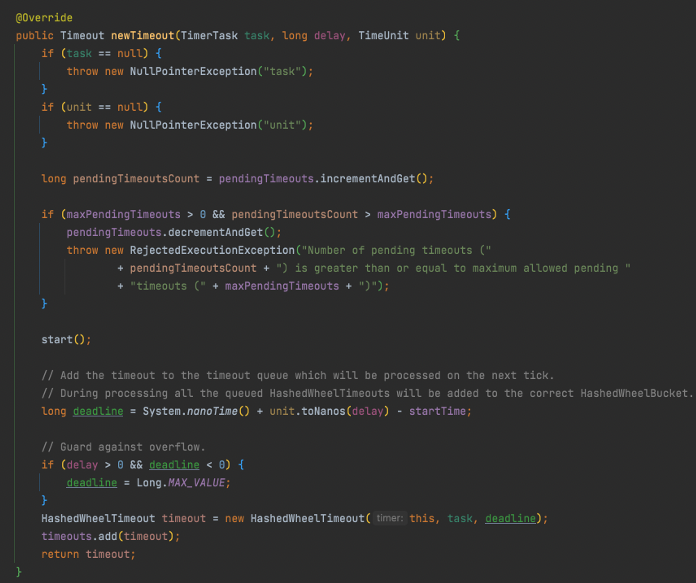
这里我们展开比较重要的 start 方法,首先获取 worker 的运行状态,如果是初始化状态,则更新成已启动状态,启动 workThread 线程,若是其他状态,则做其他相应的处理。接着是等待 workThread 将 startTime 初始化完成(在 Worker 的 run 方法中初始化完成),之所以需要等待 startTime 初始化完成,是因为 newTimeout 方法中,start 方法调用后也用到了这个 startTime,不这样做,任务的截止时间计算会有问题。
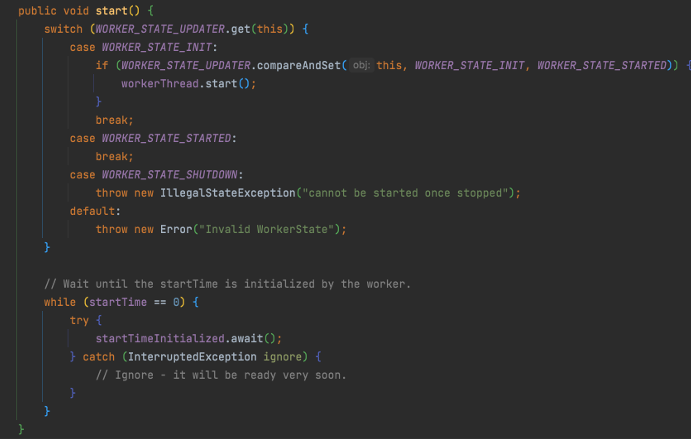
至此,我们介绍了利用 HashedWheelTimer 添加一个任务的主体流程,接下来是时间轮的内部运转。
首先是 HashedWheelTimer 的内部类 Worker,其中 run 方法的主体流程如下:
1.初始化 startTime,这里与上文中 start 方法内部对应。初始化后,利用闭锁 CountDownLatch 通知等待线程往下执行。
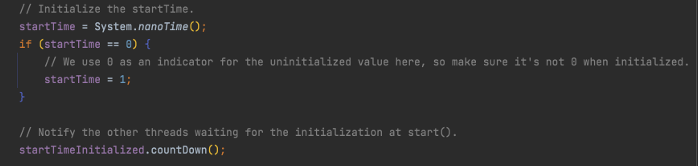
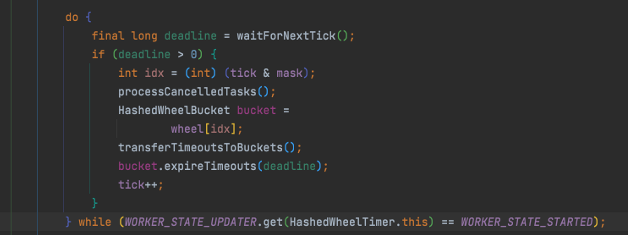
2.当定时器处于已启动状态时,不停地推进 ticket,推进的过程分解为:
- 等待下一个 ticket 的到来。
- ticket 到来后,计算该 ticket 对应时间轮的槽位(取模运算)。
- 处理已取消的任务队列。
- 获取当前时间槽,并将待处理任务队列中的任务放到槽中。
- 执行当前时间槽中的任务。
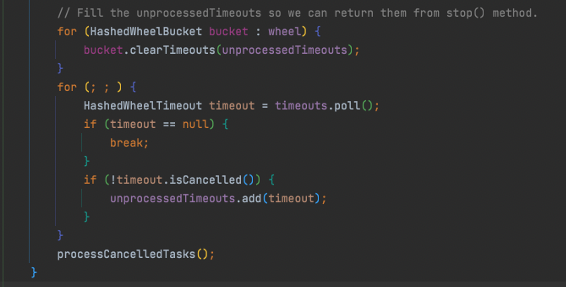
3.如果时间轮已经停止了,则执行以下流程:
- 清理所有时间槽中的未处理任务调度。
- 清理待处理任务调度队列,将未取消的加入到未处理集合中。
- 处理已取消的任务队列。
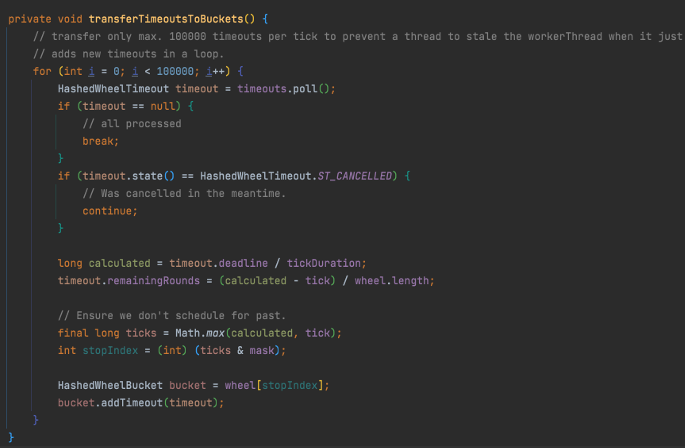
我们重点关注下定时器启动状态下的第 3 步,获取当前时间槽,并将待处理任务队列中的任务放到槽中的方法 transferTimeoutsToBuckets,其流程为以下几个步骤(这里规定循环了有限次,防止待处理队列过大,导致本次添加到槽耗费时间过长):
- 从待处理任务调度队列中取出第一个任务,进行校验。
- 根据取出的待处理任务调度,计算出一个槽。
- 设置此任务调度的剩余圈数(从这里看出 Dubbo 用的是我们在 2.2.2 中介绍的“带有 round 的时间轮”)。
- 取计算出的槽和当前槽中的较大者,并进行取模。
- 将此任务调度加入对应的槽中。
总结:这部分内容我们分别从向调度器中添加任务的主体流程和时间轮内部运转两个部分,简单介绍了 Dubbo 中时间轮的实现。
如果感兴趣,可以学习其源代码,里面很多代码设计非常巧妙,比如 startTime 初始化及初始化完成后的线程间通信实现,这些设计思路对笔者这样的初学者来说很有益处。
第四章 时间轮算法的应用展望
笔者在刚开始工作时,设计过一个叫做下载中心的服务,这个服务的功能为导出和下载项目中的数据文件,实际的定位是为了减少异步线程过多而影响各个核心业务,因此将其功能抽取出来,从而达到减少核心业务压力的目标。
下载中心的初步设计,考虑到并发请求以及文件过大带来的内存溢出问题,除了采取各种方式避免外,整体思路是,预计特别大的文件,先将任务记录进行持久化,并通过后台线程池慢慢执行这些任务,通过任务记录,主动拉取数据、生成文件等。
模型类似于 Netty 中的 BOSS-WORKER 的模式,BOSS 线程负责定时从数据库中查出未消费的任务,并将其分配给 worker 线程池进行消费,如图 4.1 所示。
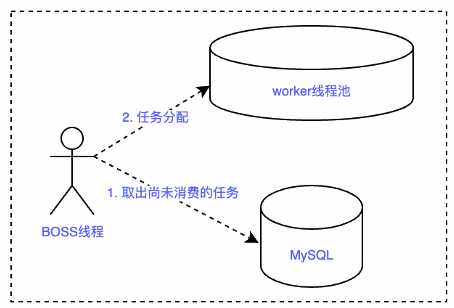
图 4.1 改造前应用服务任务消费模式示意图
当前设计虽然可以做到防止内存溢出等问题,但是这样的设计也存在一定的缺陷:
- 如果后续用户量增多,可以考虑水平扩充服务的数量,但是用于持久化任务记录的数据库会成为瓶颈。
- 即使 BOSS 线程不难做到避免任务的重复消费,但是待执行任务的查询效率会大大降低。
- 整个服务太过于依赖 BOSS 线程。
因此,考虑一种方式替代这种 BOSS-WORKER 模式,目前想到的一种方式为 MQ 消息队列,将待执行的任务信息投至 MQ 队列当中,然后该服务对其进行消费。这样的做法,即可解决上述 3 个问题,并具备维持任务有序性的优势。
但是内存易溢出的问题仍然存在,因此,考虑限制消费任务的线程并发数量。如果超过这个数量,则不再消费任务,而是重新投递任务至 MQ 队列中。这里,我们有更好的做法,即需要将任务重新投递至 MQ 队列时,做一些延时的处理,防止反复重新投递任务。整体流程如图 4.2 所示:
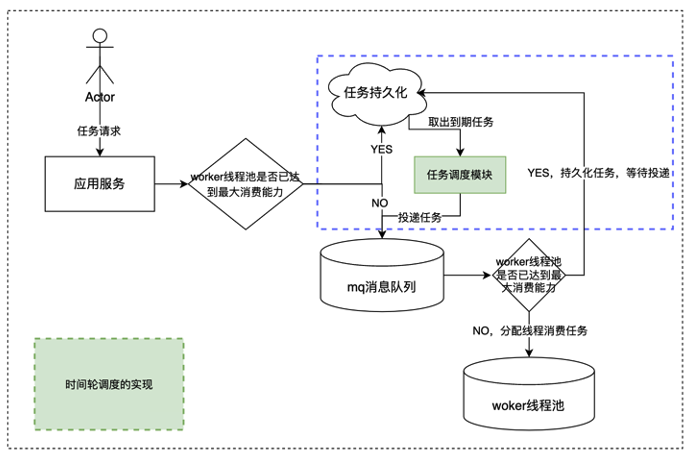
图中,绿色模块为整个系统设计中的用以调度定时任务的任务调度模块,利用时间轮来统一管理这些定时任务。
对于短暂延时和长延迟的消息,我们都期望延时尽可能的精确,而对于长延时的消息,我们还要对其进行持久化,也就是暂存。等到消息快要到期时,再重新取出,进行投递。
而这种长延时消息的持久化,与我们图 4.1 所示定时从数据库取任务所遇到的瓶颈是一致的。
我们更期望有成熟的框架,能够提供 1.长延迟任务的持久化 以及 2. 任务调度 的能力。从中间件平台组提供的 MQ 中,我们发现目前它是已经支持 包含这两个能力的延迟 MQ 功能的。延迟 MQ 架构大致如下图所示:
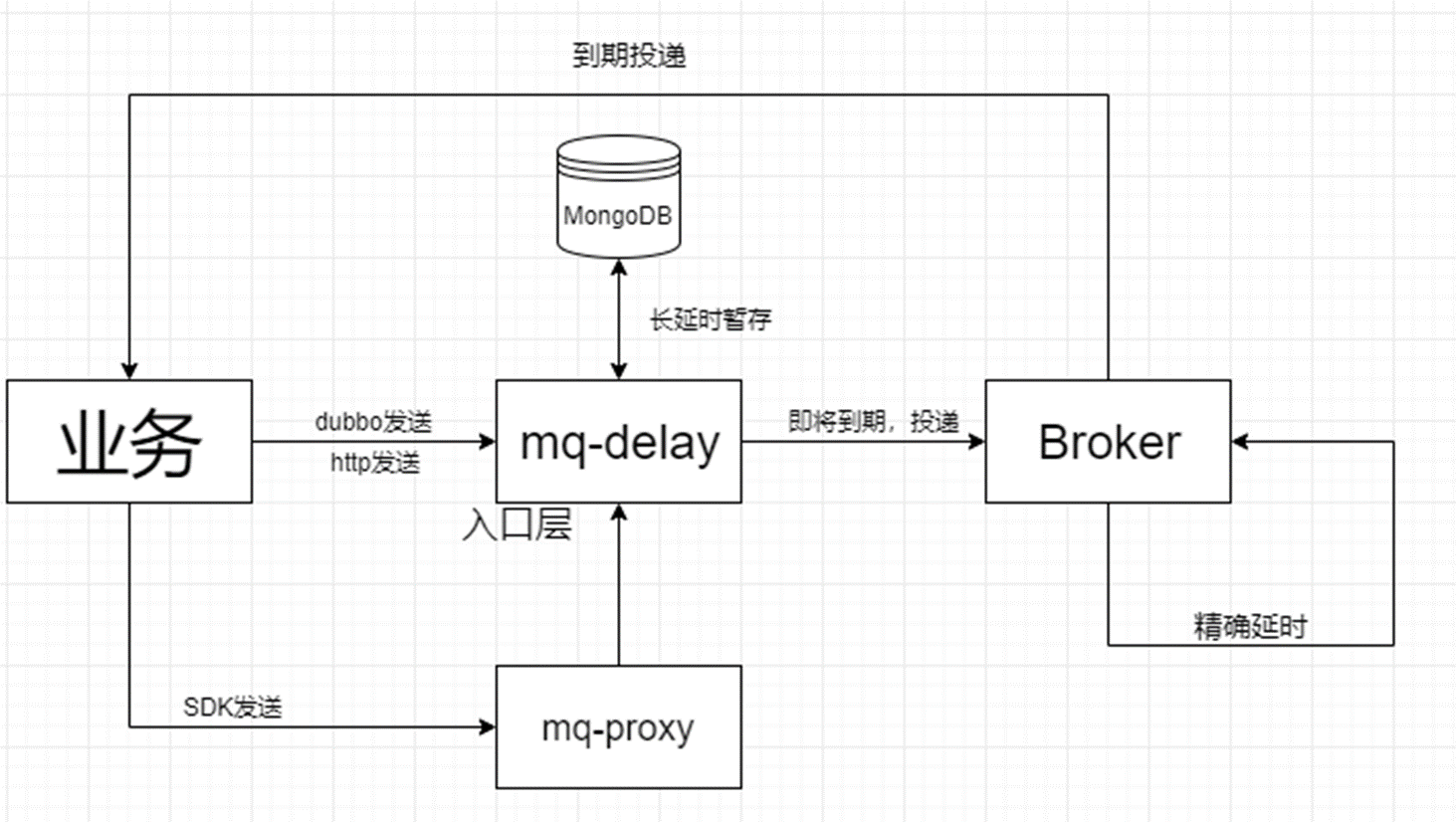
具体延迟消息的发送和处理的流程如下图所示:
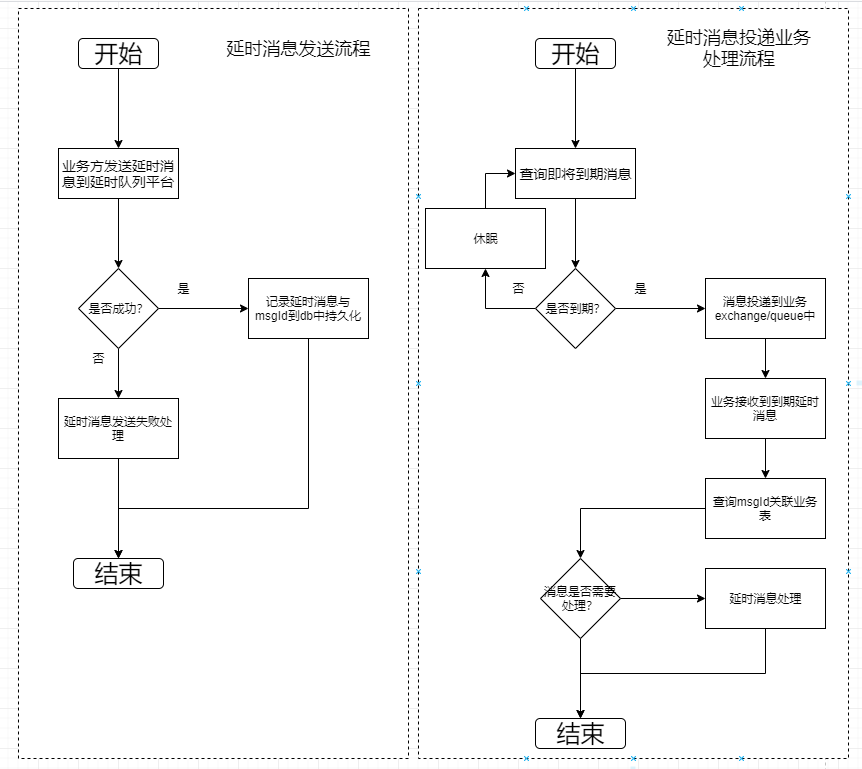
实际上,该延迟 MQ 的实现,正是由时间轮实现的调度 以及利用 MongoDB 数据库 实现的持久化,这与我们所期望的能力完全一致,完全可以满足我们的需求。
总结
本文从定时任务和时间轮算法的起源开始,对时间轮算法进行了介绍。详细的阐述了时间轮的算法思想,以及简单时间轮、带 round 的时间轮以及分层时间轮这三种常见的时间轮模型,并给出了对应的数据结构实现。
接着以 Dubbo 为例,介绍了时间轮模型在 Dubbo 中的应用,从源码出发,介绍了该算法在 Dubbo 中的主要实现。
最后,我们介绍了笔者自身所做过的一个小模块,展开分析了该模块功能目前所遇到的瓶颈,并给出了通过融合了时间轮算法的延迟 MQ 来优化当前设计的思路。
参考文献:
Hashed and Hierarchical Timing Wheels: EfficientData Structures for Implementing a Timer Facility.